
一组歌曲的路径,已经从文件系统导入到 mongodb 里。 后端 python 从 mongodb 读出来供 web js 读取。 发现有几首歌放不出,看后台 nginx 的日志是 404 ,找不到文件。 F12 把路径拷出来,肉眼看路径是对的,但是 urlencode 后和正确的确是有不同,不知道为啥? urlencode ,第一行可以读取,第二行报 404. 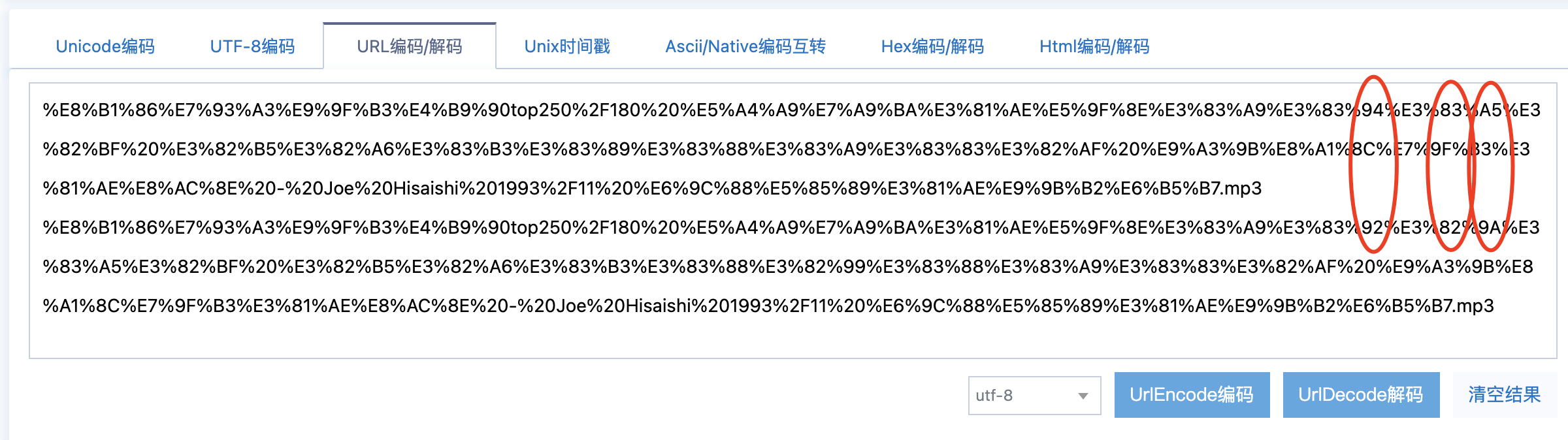 解码结果是一样的!!!
解码结果是一样的!!! 
猜测是 unicode 编码的问题,但是不确定怎么解决。



一组歌曲的路径,已经从文件系统导入到 mongodb 里。 后端 python 从 mongodb 读出来供 web js 读取。 发现有几首歌放不出,看后台 nginx 的日志是 404 ,找不到文件。 F12 把路径拷出来,肉眼看路径是对的,但是 urlencode 后和正确的确是有不同,不知道为啥? urlencode ,第一行可以读取,第二行报 404. 解码结果是一样的!!!
猜测是 unicode 编码的问题,但是不确定怎么解决。
 | 1 soudesuka Feb 7, 2022 我猜测是 文件路径 中的 ピ 和 ド 被拆解成 ヒ 与 和 ト 与 了吧。 详见请搜索 Unicode equivalence |
 | 2 lidlesseye11 Feb 7, 2022 建议 lz 把文本贴上来。你这两张图片怎么搞。。 |
 | 3 ClericPy Feb 7, 2022 是 quote 和 quote_plus 的问题? 话说先搞明白是前端输入错误还是后端解码错误? 提问题直接给例子吧 输入: xxx, 期望: xxx, 错误: xxx |
 | 4 imn1 Feb 7, 2022 #1 +1 ピ(30d4) 分解成 ヒ(30d2) 和 '' (309a)两个字符 处理日语字符,这事情很常见,做个预案吧 |
 | 5 elboble OP 如果是这样,是不是汉字 unicode 也存在这个问题。日语一点不懂,是不是应该存在一个通用的做法? |
 | 6 sagaxu Feb 8, 2022 via Android 文件名和请求路径就不该出现[a-z0-9_]以外的字符,其它信息可以作为元数据存储在 db 里 |
 | 7 yogogo Feb 8, 2022 用参数带文件名吧 |
| 8 soudesuka Feb 8, 2022 Python 函数 unicodedata.normalize(form, unistr) 返回 Unicode 字符串 unistr 的正常形式 form 。form 的有效值为 'NFC' 、 'NFKC' 、 'NFD' 和 'NFKD' 。 NFC:Normalization Form Canonical Composition (以标准等价方式来分解,然后以标准等价重组之) NFD:Normalization Form Canonical Decomposition (以标准等价方式来分解) 第一个路径 = unicodedata.normalize('NFC', 第二个路径) 第二个路径 = unicodedata.normalize('NFD', 第一个路径) |