

数月之前我们公布了关于用 VictoriaLogs 充当 Traces 数据的存储的调研,从 PoC 的角度看,这是一次很不错的尝试,但是我们意识到,这离真正可用的产品形态还差很远。
因此在这段时间内,这个 PoC 项目发生了如下的变化:
- VictoriaLogs 从 VictoriaMetrics 项目分离。而我们的 Traces 解决方案,作为 VictoriaLogs 的一个下游分支,也拥有了属于它的新名字和仓库:VictoriaTraces。
- 完善查询场景的性能测试和优化,发布了第一个版本 v0.1.0。
同时,我们还收到了很多用户关于查询性能的疑问,因为在上一篇博客中,查询性能只被简单地提及过 是的,那是一轮不够严谨的测试。我们通过简单观察不同 Traces 后端的响应速度,得出 VictoriaLogs 的查询性能不逊色于竞争对手,这当然没有说服力。
所以,这篇博客中,让我们一起来探索一下 Traces 在不同的后端中是如何查询的。
Traces 的典型查询场景
回想一下,开发者们是如何使用 Traces 的:
- 有人向你报告了一个 Bug 以及对应的 TraceID ,然后你打开 Traces 平台,通过 TraceID 查询 Trace。
- 有人向你报告系统变慢了,但不知道原因。你打开 Traces 平台,搜索一段时间内所有耗时超过 3000ms ,或者包含错误的 Traces。
这是 Traces 中两个最常见的查询场景,那么数据 Schema 的设计就应该围绕着它们进行。
想要加速 TraceID 的查询,那数据就应该按照 TraceID 进行排列,而其余数据可以分多列存储,也可以编码成 Binary 或者 JSON 存入一列。另一方面,想要在时间范围内按照 Span 的 Attributes (如耗时、状态)进行查询,那这些数据应该按时间排序,并且相关 Attributes 就应该作为单独的列,提供检索的能力。
不同 Traces 后端的优化倾向
如果我们观察 VictoriaTraces 和其他 Traces 后端的 Schema ,可以看出来它们的优化倾向各不相同。
Jaeger
ClickHouse 是多个 Traces 后端都选用的存储方案。在 Jaeger 的设计中,ClickHouse 有两个关键的表:
<details>CREATE TABLE spans_table ( `timestamp` DateTime CODEC(Delta, ZSTD(1)), `traceID` String CODEC(ZSTD(1)), `model` String CODEC(ZSTD(3)) ) ENGINE = MergeTree PARTITION BY toDate(timestamp) ORDER BY traceID SETTINGS index_granularity = 1024; CREATE TABLE spans_index_table ( `timestamp` DateTime CODEC(Delta, ZSTD(1)), `traceID` String CODEC(ZSTD(1)), `service` LowCardinality(String) CODEC(ZSTD(1)), `operation` LowCardinality(String) CODEC(ZSTD(1)), `durationUs` UInt64 CODEC(ZSTD(1)), `tags` Nested(key LowCardinality(String), value String) CODEC(ZSTD(1)), INDEX idx_tag_keys tags.key TYPE bloom_filter(0.01) GRANULARITY 64, INDEX idx_duration durationUs TYPE minmax GRANULARITY 1 ) ENGINE = MergeTree PARTITION BY toDate(timestamp) ORDER BY (service, -toUnixTimestamp(timestamp)) SETTINGS index_granularity = 1024; 很显然,这是针对 TraceID 查询优化的,在 spans_table 中,数据按日分区,按 TraceID 排序,因此通过 TraceID 可以快速取出数个连续的 Spans 。而通过 TraceID 外的条件查询数据时,先在 spans_index_table 中找到 TraceID ,再回到 spans_table 中取出完整数据。
ClickStack ( ClickHouse )
作为 ClickHouse 的亲儿子,ClickStack 的 Schema 完全按照 OpenTelemetry 定义,让每个属性都拥有对应的字段:
<details>CREATE TABLE otel_traces ( `Timestamp` DateTime64(9) CODEC(Delta(8), ZSTD(1)), `TraceId` String CODEC(ZSTD(1)), `SpanId` String CODEC(ZSTD(1)), `ParentSpanId` String CODEC(ZSTD(1)), `TraceState` String CODEC(ZSTD(1)), `SpanName` LowCardinality(String) CODEC(ZSTD(1)), `SpanKind` LowCardinality(String) CODEC(ZSTD(1)), `ServiceName` LowCardinality(String) CODEC(ZSTD(1)), `ResourceAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)), `ScopeName` String CODEC(ZSTD(1)), `ScopeVersion` String CODEC(ZSTD(1)), `SpanAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)), `Duration` Int64 CODEC(ZSTD(1)), `StatusCode` LowCardinality(String) CODEC(ZSTD(1)), `StatusMessage` String CODEC(ZSTD(1)), `Events.Timestamp` Array(DateTime64(9)) CODEC(ZSTD(1)), `Events.Name` Array(LowCardinality(String)) CODEC(ZSTD(1)), `Events.Attributes` Array(Map(LowCardinality(String), String)) CODEC(ZSTD(1)), `Links.TraceId` Array(String) CODEC(ZSTD(1)), `Links.SpanId` Array(String) CODEC(ZSTD(1)), `Links.TraceState` Array(String) CODEC(ZSTD(1)), `Links.Attributes` Array(Map(LowCardinality(String), String)) CODEC(ZSTD(1)), INDEX idx_trace_id TraceId TYPE bloom_filter(0.001) GRANULARITY 1, INDEX idx_res_attr_key mapKeys(ResourceAttributes) TYPE bloom_filter(0.01) GRANULARITY 1, INDEX idx_res_attr_value mapValues(ResourceAttributes) TYPE bloom_filter(0.01) GRANULARITY 1, INDEX idx_span_attr_key mapKeys(SpanAttributes) TYPE bloom_filter(0.01) GRANULARITY 1, INDEX idx_span_attr_value mapValues(SpanAttributes) TYPE bloom_filter(0.01) GRANULARITY 1, INDEX idx_duration Duration TYPE minmax GRANULARITY 1 ) ENGINE = MergeTree PARTITION BY toDate(Timestamp) ORDER BY (ServiceName, SpanName, toUnixTimestamp(Timestamp), TraceId); 如果需要按照 TraceID 查询怎么办呢?是不是要在所有 Partition 中都找一遍?显然太低效了。因此,ClickStack 还会将每个 Span 的时间记录到 otel_traces_trace_id_ts 表,并且创建物化视图,这样,每个 TraceID 的起始和结束时间就很容易确定了,有效加速了以 TraceID 在 otel_traces 表的查询速度。
CREATE TABLE otel_traces_trace_id_ts ( `TraceId` String CODEC(ZSTD(1)), `Start` DateTime64(9) CODEC(Delta(8), ZSTD(1)), `End` DateTme64(9) CODEC(Delta(8), ZSTD(1)), INDEX idx_trace_id TraceId TYPE bloom_filter(0.01) GRANULARITY 1 ) ENGINE = MergeTree ORDER BY (TraceId, toUnixTimestamp(Start)); CREATE MATERIALIZED VIEW otel_traces_trace_id_ts_mv TO otel_traces_trace_id_ts ( `TraceId` String, `Start` DateTime64(9), `End` DateTime64(9) ) AS SELECT TraceId, min(Timestamp) AS Start, max(Timestamp) AS End FROM otel_traces WHERE TraceId != '' GROUP BY TraceId; VictoriaTraces
VictoriaTraces 目前的设计近似于 ClickStack ,在上一篇博客中提到过,尽可能将所有 Attributes 平铺为 Fields ,而 Fields 正接近于 Column-oriented 数据库中“列”的概念。
同样,单纯这样的设计并不能应对 TraceID 查询的场景,因此,我们又增加了一个单独的 Index Stream ,VictoriaTraces 在遇见每个新的 TraceID 的时,都会在这个 Stream 中增加一条记录 (Timestamp, TraceID)。这个 Stream 非常小,行数为 Trace 的总量,因此在这个 Stream 中按照 TraceID 查询会很快。在找到 TraceID 对应的 Timestamp 后,以此为中心,在各个 Stream 中查询 ±45 秒内的数据,获取 TraceID 对应的所有 Spans 。
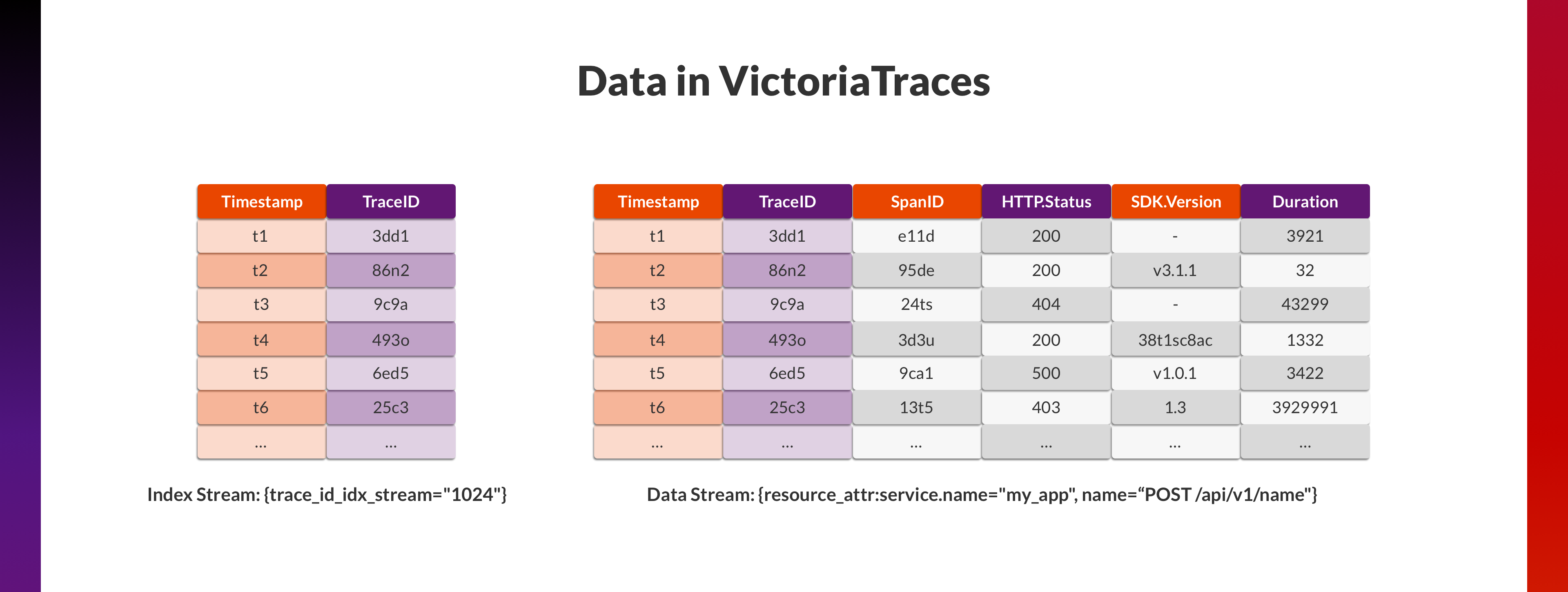
这个设计只是作为加速 TraceID 查询的概念验证,它有很多显而易见的缺点:
- Index Stream 数据按照时间排序,因此按 TraceID 的查询是遍历而二分查找,效率不高。
- TraceID 的起始结束时间是不确定的,查询 90 秒的数据既可能浪费(如 Trace 耗时仅为 1 秒),也可能不足(如 Trace 跨越数分钟)。
不过,聪明的读者一定也知道所有的设计都有其长处和短板,问题在于是否值得:
- 用更多的空间换更快的时间。
- 用更昂贵的写入换更快的查询。
我们一定会在后续版本保持探索,调整这些设计,将它变得更加适合不同的使用场景。不过在那之前,不如先回到今天的主题它们到底查询性能如何?
查询性能对比
改良 Traces 数据生成
为了生成大量更贴合生产环境的测试数据,我们一开始打算部署多个 OpenTelemetry Demo。该 Demo 是基于 14 个微服务的分布式系统,覆盖了不同的编程语言、不同的插桩方式,产生的数据比过往使用的 Jaeger tracegen 更具有代表性。
但是在运行一段时间后,我们发现 OpenTelemetry Demo 需要消耗较多的资源,并且产生的压力有限。因此,我们又基于流量录制回放的思路编写了 vtgen,它可以:
- 反复发送预先录制好的 OpenTelemetry Demo 的 Trace 请求到多个 OTLP HTTP Endpoints ,这些 Trace 请求中 TraceID 和部分字段会被按需修改。
- 记录 HTTP 请求耗时指标。
vtgen 既可以用于 Traces 后端的写入性能 Benchmark ,也可以为不同 Traces 后端写入完全一致的数据,并随机记录一定量的 TraceID ,用于查询性能 Benchmark 。
Benchmark 设计
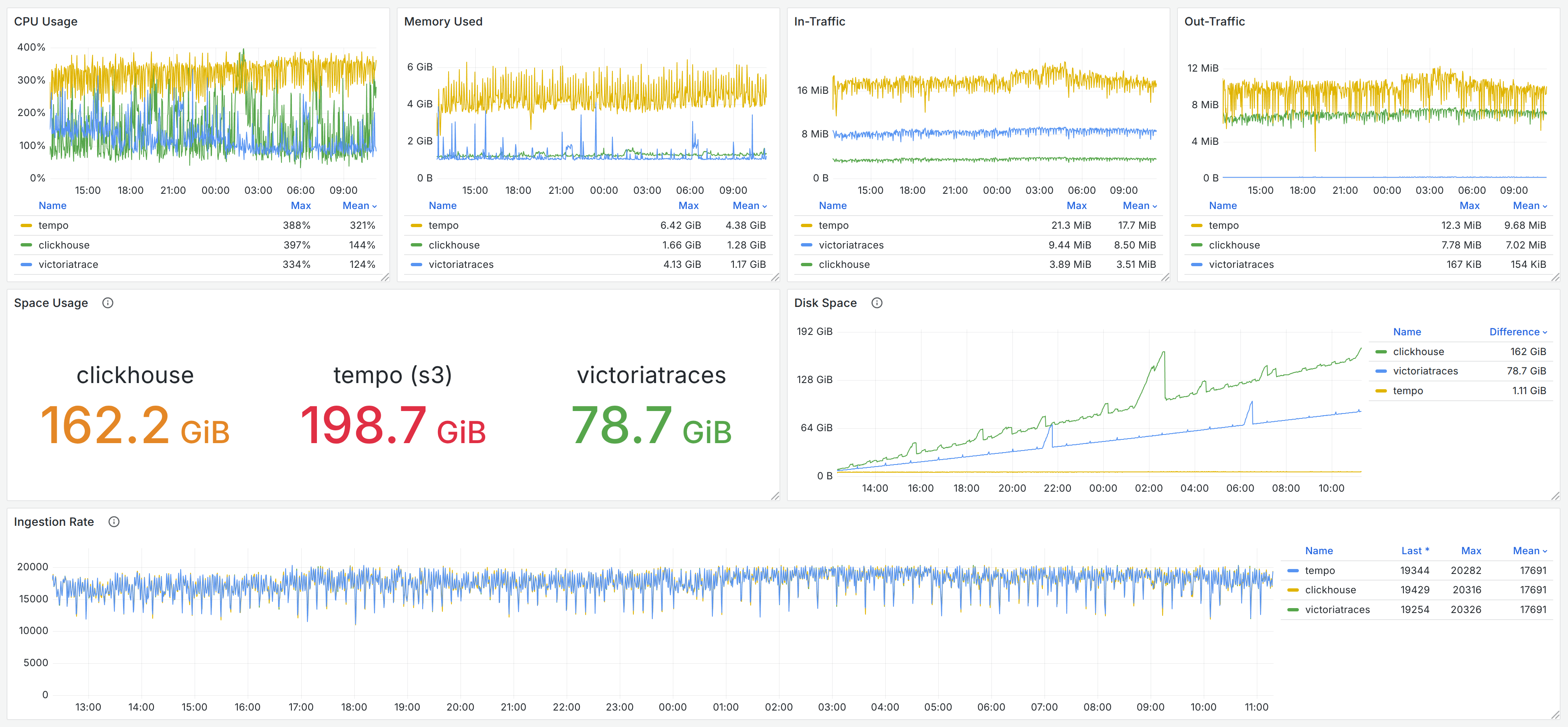
我们在对 VictoriaTraces 的 Benchmark 中仍然选用了 Grafana Tempo 及 Jaeger & ClickHouse 作为对比,写入相同的的数据,其中数据写入过程的监控监控记录如下图,读者也可以在 Grafana Dashboard 快照中查阅。
我们在第一节中介绍过,最常见的 Traces 查询场景包括:
- 根据 TraceID 查询。
- 根据属性在特定时间段内搜索出多个 Traces 。
因此对应地:
- 通过 vtgen 在 Ingestion 过程中记录下 63000 个 TraceID ,逐一向 3 个 Traces 后端进行请求。
- 手动构造 15 组 Traces 属性查询的参数模板,以及 50 个时长为 10-60 分钟的时间段,逐一向 VictoriaTraces 和 Jaeger 进行共计 750 次请求。
{{<admonition type=note title="为什么属性搜索对比中没有 Tempo ?">}}
VictoriaTraces 、ClickHouse 均可以支持 Jaeger 的 Search API ,而 Tempo 同样提供 Search API ,但是两个 Search APIs 的返回数据格式并不一致:
- Jaeger 的 Search API 需要提供完整的 Traces 数据,包含所有 Spans 。换句话说,Jaeger 的 Search API 就是 List 版本的 Trace API 。
- Tempo 的 Search API 只需返回 Traces 的部分数据,因而无需额外查找每个 Trace 的其余 Spans 。
因此,它们无法直接对比查询性能。
不过,Tempo 的 Search API 设计实际上更简洁高效,所以,我们会在 VictoriaTraces 实现 Tempo API 后将其进行补充对比。
{{< /admonition >}}
结果
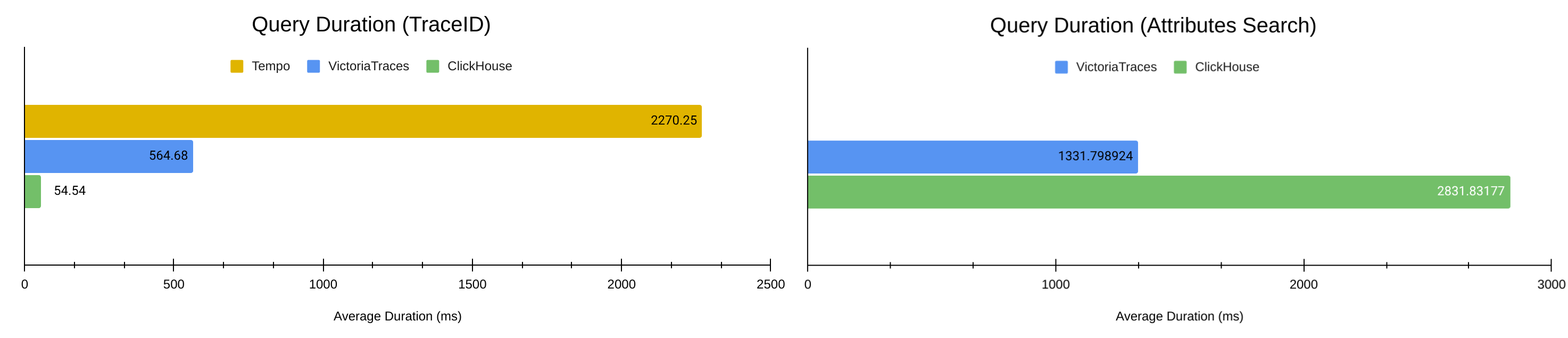
通过上面的图表,我们可以看到 VictoriaTraces 相比一些主流 Traces 后端的性能如何。
与 Jaeger & ClickHouse 的组合相比,如第二节中所分析,因为它们的查询优化方向不同,所以在两种场景中的表现互有胜负。ClickHouse 使用了 2 倍于 VictoriaTraces 的存储空间( 162 GiB vs. 79 GiB )来换取根据 TraceID 查询的速度,舍弃了在 Traces Search 场景的性能。
VictoriaTraces 的未来
通过这些测试,我们已经知道 VictoriaTraces 与不同竞品的差异 既有设计上的原因,也有优化上的不足。我们当然需要继续迭代 VictoriaTraces ,希望它能够更早抵达稳定版本。
所以,在性能上:
- VictoriaTraces 的底层数据结构将与 VictoriaLogs 进一步分叉,让 Traces 场景得到更多的关爱。引入更合适的 IndexDB 和 Cache 来优化数据写入和查询。
- Profiling 结果显示,VictoriaTraces 还有很多糟糕的代码,它还有很大的进步空间。
同时,在功能上,我们希望:
- 提供 Tempo HTTP APIs ,这允许用户更灵活地查询 Traces 数据。
- 完善 Kubernetes 支持,提供 Operator 和 Helm Chart 。
- 完善 Cluster 版本的设计。
期待能在博客评论区或 VictoriaTraces 的 Issues 中收到你的反馈,也期待与你在下一期开发者笔记中再会!










