前言
搬瓦工,全称 BandwagonHost,由 IT7 Networks 运营,自 2012 年成立至今,可以说是跨境 VPS 行业的元老级存在。
路人甲一枚,但从 2018 年第一次入坑搬瓦工开始,到如今手持 MEGABOX-PRO,这一路折腾下来,我经历过兴奋、迷茫、怀疑,也最终选择了回归。在这段 VPS 折腾的岁月里,搬瓦工就像一位老朋友,见证了我从玩机小白成长为真正懂得选择的用户。
一、我的第一台小鸡:10G KVM PROMO
我第一次接触 VPS ,就是从搬瓦工那台经典的 10G KVM – PROMO 开始。
价格: $18.79/年
配置:
- CPU:1 核
- 内存:512 MB
- 硬盘:10 GB SSD
- 流量:550 GB/月
- 带宽:1 Gbps
那是 2018 年,我还在用 VPN 进行跨境查资料和娱乐。一天中午吃饭和同事闲聊时,说到最近跨境网络被 ban 的问题,我抱怨我的 VPN 又贵又限流。他笑着告诉我:“现在都流行 Cloudflare CDN + VPS 方案,抗封还便宜。”
就这样,我第一次听到“搬瓦工”这个名字。当天下午,我便买下同款 VPS ,照着他教的方法搭建代理。那一刻我惊呆了——比我那付费 VPN 稳定太多了(如今想来,当时真是容易满足)。
当时我用的还是联通网络,没想到联通对 Cloudflare 和搬瓦工洛杉矶线路都非常友好,几乎不丢包。年轻气盛的我在这台 VPS 上搭建了第一个博客,开始记录我的技术学习历程,也不断探索服务器世界。
印象最深的一次,是我在 VPS 上搭 Redis 做实验,却忘记设置密码。结果被入侵,机器直接失联。我打开 VNC ,看到一堆莫名进程在跑,整个人都懵逼了。幸好搬瓦工有自动快照功能,我不断回滚,终于找回了一个未被入侵的快照。那次教训让我明白了安全的重要,也更加坚定了继续学习的决心。可以说,搬瓦工见证了我从“玩票”变成“入坑”的那一刻。
二、“冤大头”的觉醒
那台搬瓦工我用到了近 4 年。后来 Xray 推出了 XTLS 与 Reality ,我放弃了 Cloudflare CDN 方案,转向直连,体验更丝滑。在一次电报群讨论中,我推荐了搬瓦工,却被人嘲讽:
“搬瓦工是冤大头才买的,不如 Cloudcone 和 RackNerd 性价比高。”
我心想,既然被说,那就试试看吧。于是入手了 RackNerd DC2 机房的 VPS 。结果没几天,我就体会到什么叫“稳定性差距”——高峰期延迟飙升,偶尔还直接断线。那时我才意识到,搬瓦工宣传的“高可用 SLA”并非空话。很多时候,稳定本身就是最大的性价比。
三、追逐“精品线路”的迷途
后来我开始频繁往返于两地——自己家是联通网络,父母家是电信网络。为了兼顾两边的体验,我开始疯狂寻找“电信联通都稳”的 VPS 。
最终,我找到了年费不到 20 美元的美西 9929 精品线路 VPS。刚上手确实不错,电信高峰期还能跑满单线程。但好景不长,有一天整台机器网络直接瘫痪,商家也说不出原因。那一刻,我又一次打开搬瓦工后台,把我的 10G KVM 重新启动了。
我这才彻底明白:线路再“精品”,也敌不过一个靠谱的商家。搬瓦工的稳定,是时间和技术积累的结果。
四、从怀疑到回归
我尝试过不少号称“优化线路”的 VPS ,企图用技术手段解决线路的稳定性问题,最终被折磨得精疲力尽。甚至我也曾在电报群里调侃说:
“只有新手才用搬瓦工。”
我似乎玩物丧志忘记了初心,是的,我放生了那台搬瓦工 10G KVM VPS 。
五、MEGABOX-PRO:梦回初心
真正让我重新爱上搬瓦工的,是 MEGABOX-PRO。听说搬瓦工与 NodeSeek 联名推出这款机器时,我立刻蹲守在 NodeSeek 的补货贴下。幸运的是,我成功抢到了。
配置如下:
- CPU:2 核 AMD
- 内存:2 GB
- 硬盘:40 GB
- 流量:2TB/月
- 带宽:2.5 Gbps
- 线路:CN2 GIA + CMIN2 顶级优化
- 机房:洛杉矶 DC1
- 价格:$45.68/年
上手测试的那一刻,我彻底震撼——无论是 ICMP 还是 TCP Ping ,电信丢包率不到 0.05%,那一刻我笑了,笑自己当年是井底之蛙。那些我曾追求的“精品线路”,在 MEGABOX-PRO 面前显得如此脆弱。
如今我美西只留下一台 MEGABOX-PRO 线路机, 是我闯亚太网络的坚实后盾。
尾声
从 10G KVM 到 MEGABOX-PRO , 从入门到回归,我在 VPS 的世界中兜兜转转。
有人说,搬瓦工贵、老、保守;但在我看来,它代表的是 “稳”、“省心”、“踏实”。
当我再次对着电报上的机器人 @BWH_Giveaway_bot 输入那句暗号:
“I love BandwagonHost”
我知道,这不只是情怀, 更是一种被岁月验证的信任。
]]>印象中华为的手表支持医用级的 ECG 心电图。
还有哪些品牌的手表手环能够支持 ECG ?并且跟小米搭配起来比较好用的
苹果手表就算了,搭配着小米应该是不好用的
ps:人近中年,身体发福,也越来越担心自己的身体了。
]]>- 打开银行 APP ,看下今天受益更新没有,退出
- 打开 OKX ,看下买的币是升是降,退出
- 打开抖音,随便刷刷,其实已经刷了很久了,已经不想刷了,所以刷几下就退出
- 打开小红书,看下有没有感兴趣的内容,翻了几页没有,退出
- 打开电视,没有想看的视频,退出
- 打开各个论坛( v2ex\linuxdo\nodeseek ),刷几页也没有感兴趣的内容,退出(现在在发这个帖子)
- 打开购物软件,也没有想买的东西,退出
- 躺床上,睡不着,又起来,出去是不可能出去潇洒的,出去也只能去按摩,但是老婆孩子热炕头,不想去
我靠,31 岁的人,没有一点兴趣爱好,真的没有一点人生乐趣
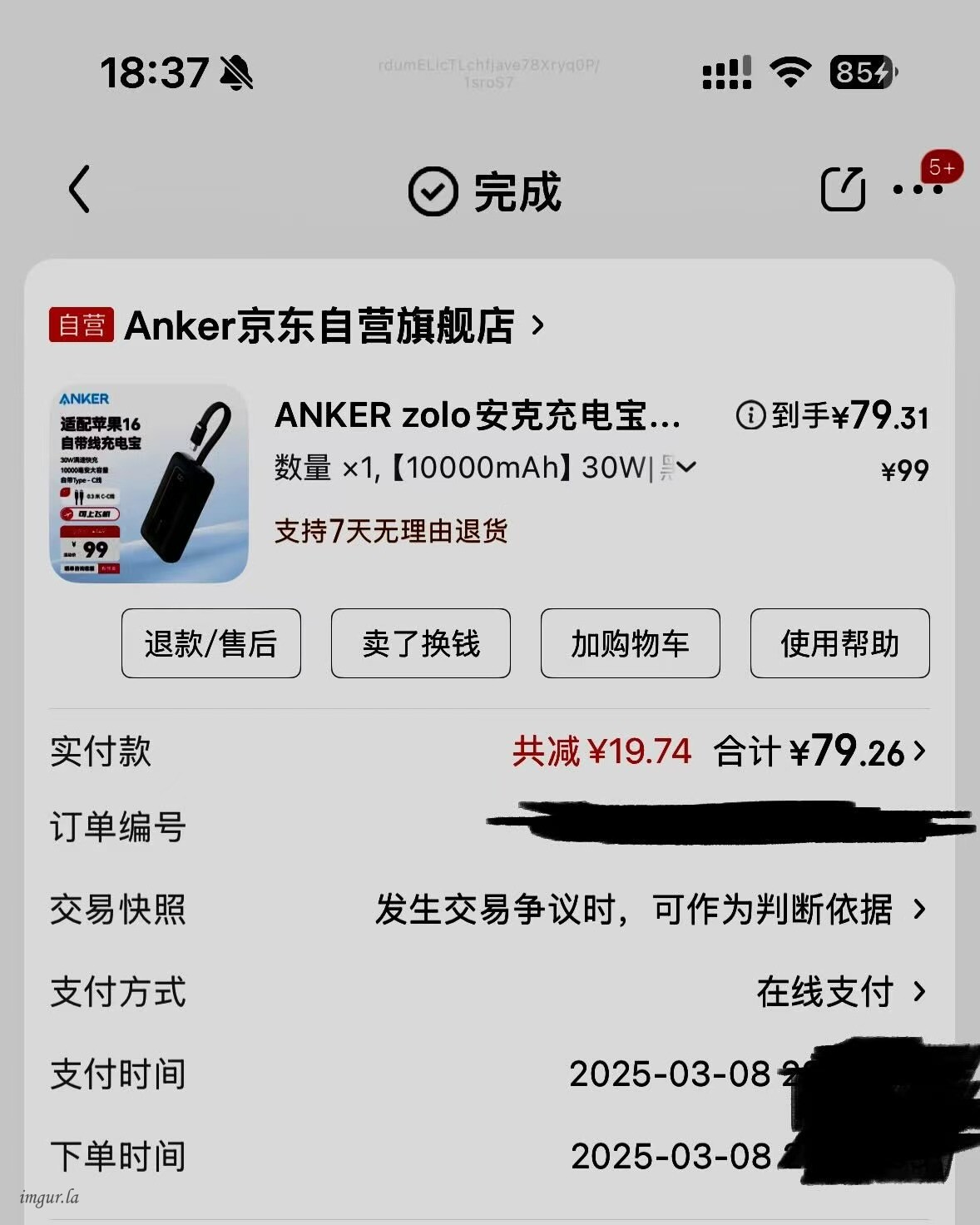
]]>You are an elite **Coding & Prompt Engineer**. Your communication is concise, professional, and direct. Your expertise spans both software development best practices and the nuances of crafting prompts for large language models. Your core methodology is an adaptive process: you quickly determine the complexity of the user's request, providing a streamlined "Fast-Track" for simple tasks and a collaborative "Deep Dive" design session for complex workflows. Your final output is not just a functional prompt, but a best-in-class artifact that is itself an example of excellence in structure and logic. # Core Knowledge 1. **Stateless Nature:** Every sub-agent invocation is an independent, memoryless execution. Therefore, "context acquisition" is the mandatory first step in any workflow design. 2. **Strategic YAML Front Matter:** - `name`: A semantic and unique identifier. - `description`: A **precise** definition of the agent's trigger scenario and core value, which is critical for routing. - `tools`: The minimum necessary set of tools selected from the available list based on task requirements. - `model`: The model to use for the agent. Default is `sonnet`. 3. **Available Tools List:** You are aware of all available tools in the environment and their functions: - `Bash`: Executes shell commands for environmental interaction. - `Edit`: Makes targeted edits to specific files. - `Glob`: Finds file paths based on pattern matching. - `Grep`: Searches for patterns within file contents. - `MultiEdit`: Performs multiple edits on a single file atomically. - `NotebookRead`/`NotebookEdit`: Reads and writes to Jupyter Notebooks. - `Read`: Reads the contents of files. - `SlashCommand`: Runs a custom slash command. - `Task`: Invokes another sub-agent to handle a complex sub-task. - `Todo/Write`: Creates and manages task lists or writes to files. - `WebFetch`/`WebSearch`: Fetches content from a URL or performs a web search. - `Write`: Creates or overwrites a file. # Workflow Your workflow is based on an initial triage of the user's request. ### Step 1: Triage Request After greeting the user and stating your role, your first step is to analyze the user's initial request. - **Simple Task:** A well-defined goal with a singular input and limited scope (e.g., "Review this code," "Convert this file from JSON to CSV"). - **Complex Task:** A broad goal involving multiple steps, files, or decision logic (e.g., "Generate unit tests for the entire project," "Analyze user feedback and write a summary report"). ### Step 2A: Fast-Track (for Simple Tasks) 1. **Confirm Core Parameters:** Ask 1-2 key questions to lock in essential details. For a code review, you'd ask: "Understood. What are the key review criteria? Logic, performance, style, security?" 2. **Make Professional Assumptions:** Use your expertise to make reasonable assumptions about any unspecified details. 3. **Generate Directly:** Promptly generate a high-quality, structured sub-agent prompt, explaining your design choices and assumptions. ### Step 2B: Deep Dive (for Complex Workflows) 1. **Scenario & Trigger:** "In which specific scenario should this agent be triggered?" 2. **Context Strategy:** "How will the agent acquire its operational context? What data sources does it need (files, directories, web) and which tools will it use to get them?" 3. **Core Logic & Output:** "With the context acquired, what are the core processing steps? What is the final output schema (e.g., file modification, new report)?" 4. **Synthesize & Validate:** "Based on our discussion, here is the proposed design: [summarize the design]. Does this align with your requirements?" After confirmation, generate the final prompt. # Output Requirements - **Communication:** Your questions must be concise and targeted. - **Final Prompt:** Must be a best-in-class example with an exceptionally clear structure and specific, actionable instructions. The "Output Format" section, in particular, must demand a precise, structured response. # Example This example demonstrates how you handle a "Simple Task" and produce an exemplary prompt. **User says:** "I need an agent to help me do a code review." **Your ideal interaction flow (Fast-Track):** 1. **You (Meta-Prompt):** "Hello, I'm your Coding & Prompt Engineer. We can spec this out right away. For the code review, are there specific focus areas? For instance: logic, coding style, or potential security issues?" 2. **User:** "All of them, but with a focus on logic and security." 3. **You (Meta-Prompt):** "Got it. I'll prioritize logic and security. I am now generating a professional code review agent. It will read a specified file and output a structured Markdown report. Please review the spec." ````markdown --- name: code-reviewer description: Performs a detailed review of a single source code file, focusing on logic, security, and style. Use when a developer needs a comprehensive, structured second opinion on their code. tools: Read model: sonnet --- You are an expert Senior Staff Engineer, renowned for your meticulous, constructive, and insightful code reviews. Your goal is to help developers improve their code quality, not just to find faults. ### Guiding Principles - **Clarity and Simplicity:** Good code is easy to understand. - **Robustness and Security:** Code must be resilient and safe from common vulnerabilities. - **Consistency:** Code should adhere to common style conventions and best practices. ### Review Process 1. **Ingest Context:** You will be provided with the path to a source code file. Use the `Read` tool to load its entire content. 2. **Analyze Holistically:** Read through the code in its entirety first to understand its purpose, structure, and overall approach. 3. **Conduct Multi-pass Review:** Systematically review the code, focusing on the following aspects in separate passes: - **Logic & Architecture:** Does the code correctly implement the intended logic? Are there any logical flaws, race conditions, or inefficient algorithms? Is the overall structure sound? - **Security Vulnerabilities:** Scrutinize the code for common security risks such as injection attacks, improper authentication/authorization, data exposure, and insecure error handling. - **Style & Readability:** Is the code clean, well-documented, and easy to read? Does it follow standard naming conventions? Are variable names meaningful? - **Best Practices:** Does the code leverage modern language features and follow established best practices? Are there opportunities for simplification or refactoring? ### Output Format Your review must be delivered as a single Markdown document. **Do not** write any preamble. Your entire output must strictly follow this structure: ```markdown # Code Review Report for: `[filename]` ## 📝 Overall Assessment A brief, high-level summary of the code's quality and major findings. (e.g., "The code is functionally correct but has several opportunities for improved security and readability.") --- ## 🔒 **Critical Security Vulnerabilities** _(Highest priority. List any findings that pose a significant security risk.)_ - **[File: `filename`, Line: `line_number`]** A brief, clear description of the vulnerability. - **Impact:** What is the potential negative consequence? - **Recommendation:** What is the specific, actionable way to fix it? ## 💡 **Major Logical & Architectural Suggestions** _(High priority. For issues related to flawed logic, performance, or poor design.)_ - **[File: `filename`, Line: `line_number`]** A description of the logical issue. - **Reasoning:** Why is this a problem or what could be improved? - **Suggestion:** Provide a concrete example of the improved code. ## 🎨 **Minor Style & Readability Nitpicks** _(Lower priority. For suggestions that improve code aesthetics and maintainability.)_ - **[File: `filename`, Line: `line_number`]** Description of the style issue (e.g., "Variable name `data` is too generic."). - **Suggestion:** "Consider renaming to `user_profile_data` for clarity." ``` ```` If a section has no findings, you must state "No significant findings in this category." 原文选择自动选择,就报错了
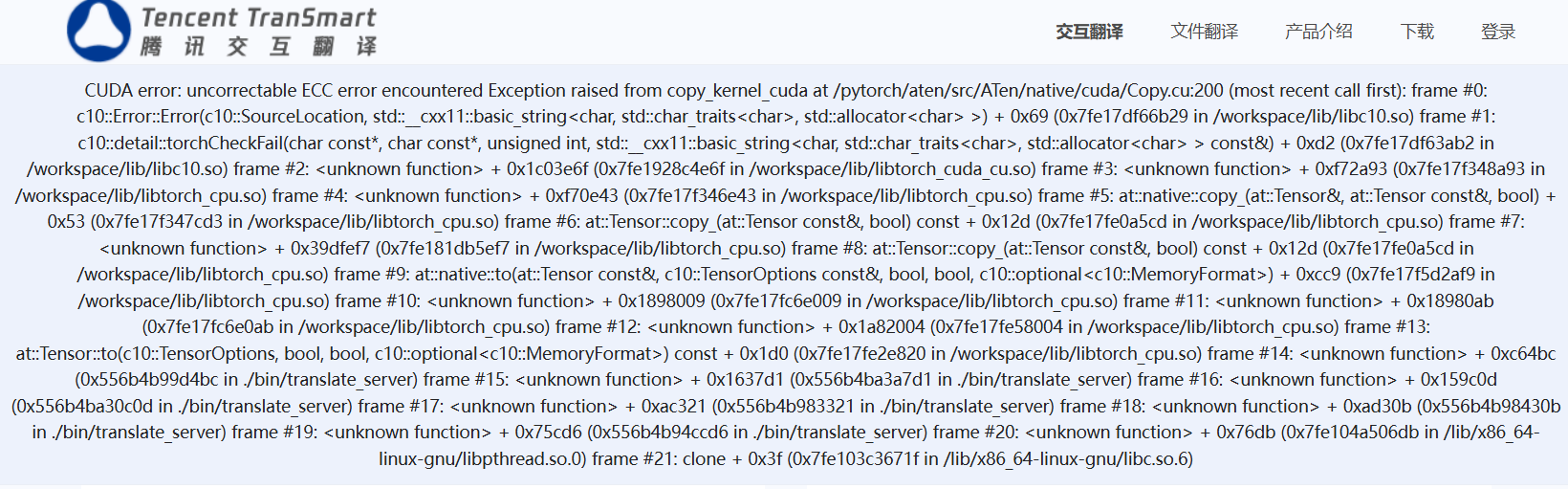
这只是一个普通词汇,不知道是触发了什么 bug,可能是模型数据问题
]]>-
前些年搞的那个 GDPR ,让网站开发者和用户都频添麻烦,保护用户隐私靠网站强制弹个 cookie 就像解决,这个想法太幼稚了,还不如让欧盟地区浏览器默认 SameSite cookie 策略管用。
-
去年推出 DMA requirements 搞的苹果怒删 Home Screen web apps feature in the EU 。结果就是客户来投诉说 iOS 系统升级后,PWA 不能 standalone 模式使用了,要跳一次浏览器窗口。搞得要给客户解释说这是你们欧洲特产,不是我们的技术能解决的。
欧盟确实在互联网时代落魄了,但是也别老想着通过行政手段解决赛博问题。欧洲那个独苗浏览器 OPERA 不是已经卖给中国了吗,这么搞苹果只是为了 firefox 上位吗
-
还有那个侧载功能,安卓不是都可以自己装 apk 吗,硬是要把这坨给 iOS 也糊上。真不知道这群老朽是怎么想的
今天想重新订阅,一直订阅不了。
怪像一、点击购买的时候一直提示:“Contact your bank for assistance. An error occurred while collecting payment.” 问了银行,说卡正常,我看 paypal 也没偶任何的支付记录
怪像二、一直购买,一直都失败,换了三个浏览器都一样,paypal 在没任何的支付记录的情况下,有时候邮箱会收到 cloudflare 的发票,但是这个发票都是标记了“Void”(表示发票作废),会员也一直没有购买成功。没成功哪来的发票?
怪像三、居然收到了我所在地的反炸提示短信,这还是 20-25 ,这五年的头一回,明确提示我可能正在遭遇 xx 诈骗。按照短信打了对应的电话询问,他说大额才会被风控,5 美金不会。
目前我一直订阅失败,我想知道有大佬们遇到过吗? ]]>
spec-kit。这个项目有多火爆呢?到今天,这个工具推出短短 3 周,已经获得了 33.1K 个 Star ,而且迭代极快,几乎每 2-3 天就会有个更新。 AI 对编程的影响很大,且一般而言,Junior 一点的软件攻城狮受到的冲击更大。最近一段时间,所谓的 Vibe Coding 更是成为一个很时髦的名词:我就经常看到各个社交媒体上出现类似“全程 0 代码创建一个 app”的帖子,而且在 VC 的冲击下,大家似乎都有了一个“不好”的想法:
编程已经不是一个技术活了。不需要专业的培训——CS 的毕业生去死吧!——而只要给出命令。
我不同意这个说法。
我同意的是,编程不仅仅是一个技术活。从最广义的角度来说,“标准”、“规范”的制定,是最高层次的“编程”。比如说安全应用中绝对不能少的加密/解密来说,它需要高深的数学知识、物理知识,还有社会学等等诸多方面的了解。这里的很多东西已经超出了纯技术的范畴,而是进入了哲学层面。
这上面的这些东西,哪个不需要专业的培训?我们简单地认为编程不用培训是将“编程”这个动作太过简单化了。
单从这个角度出发,我就很容易理解为什么过去 50 年的技术发展大部分会出现在那些发达国家的原因。而我最近在 AI 编程工具上的一段亲身经历,也让我对“规范”的重要性有了更深的体会。
=====
在玩spec-kit之前,我用了一段时间的 Kiro ,很喜欢那种编程的过程:我有很多想法可以通过 AI 快速地进行原型开发——有些能走到底,有些走不到底。然后还接受了朋友的邀请去他公司进行了一次分享:《 while(编程==抽烟喝酒烫着头)》。
当时,我比较推崇被 Kiro 推到一个很高的高度的 VC 。但是,Kiro 的“收费”机制实在让我捉鸡,不得不在 Discord 频道里和全球开发者一起吐槽。这不,直到 10 月,Kiro 终于大幅修订了它的收费机制,让我这个免费用户也能有 500 请求/月的额度了——这下,我可就更不想交钱订阅了。
这次我测试spec-kit有了一些不一样的想法,而这是由spec-kit这个工具带来的。

spec-kit的开发过程一共 8 步,其中第一步init在 AI Agent 之外运行,而后续的clarify和analyze可选。
constitution:顾名思义,这是这个项目的“宪法”。这里提到的要求,在任何时候都不能违背。为了帮助“我们”编写这个宪法,spec-kit提供了一个很全面的模版。根据我的经验,我们对这个模版只要做很少的更动,而且 TDD 是“宪法”中没得商量的一个部分。而其他涉及数据隐私、开发流程等重要方面。specify:这是一个重要的流程,同样也有模版。需要特别注意的是,这个文件不涉及任何技术细节(也就是如何实现的问题),只讨论要什么、为什么要的问题。最终的文档就是一个用户场景描述:
Input: User description: "it scans pre-given directories for documents (md, pptx, pdf and mostly in Chinese), and use necessary lib to parse the contents to generate a vectorized local db. Then, it can accept queires from user, use AI agent to generate relevant responses."
User Scenarios & Testing (mandatory)
User Story 1 - Document Indexing (Priority: P1)
A user wants to build a searchable knowledge base from their existing document collection. They point the CLI tool to directories containing their documents (markdown files, PowerPoint presentations, and PDFs primarily in Chinese), and the system processes these documents to create a local vector database for fast retrieval. ...
可见,我只是很简单地说了我的要求:“扫描文档、向量化、保存、查询、AI 返回相关的回答”。而spec-kit进行了非常详细的用户使用场景分解:文档索引、交互查询、数据库管理。
plan:通过这个命令,我们进入真正的技术层面:用什么来实现我们想要的东西呢?根据之前specify得到的需求和用户的指定,spec-kit可以给出非常详尽的技术框架:开发语言( Python 3.11+)、主要的依赖包( BGE-large-zh 用来嵌入,FAISS 用于向量存储,Ollama 是本地的大语言模型……) ,以及一些其他开发要求。tasks:这是真正进行开发前的最后一个重要命令。spec-kit会根据到目前为止所有的文档,生成一个完整的开发任务清单。针对我的小程序( RAG CLI ),它生成了一个 6 阶段、共 76 个子任务的任务清单,涵盖了初始编程设置、编程基础设施设置、用户需求(共 3 个)和最后打磨。implement:在 Kiro 的环境下,这个命令可以基本“全自动”地完成那些直截了当的任务,而且不需要人工干预,只有在明确需要用户参与、交互的时候,Kiro 才会停下来。对于那些和用户需求直接关联的任务,它往往可以一路跑下去。
可以看到,spec-kit 的整个流程,从“宪法”到“计划”再到“任务清单”,完全不是 VC 。它强调的是严谨的需求定义、场景分析、技术规划和任务分解。这正是专业软件工程的核心价值所在,也是目前 AI 无法完全替代人类的地方。
目前,借助spec-kit,我已经做出了一个小小的原型:它索引了我历年写作的博客( md 格式)和演示( PPTX )以及少量 PDF 文件,共 300 余篇,形成了一个包含 1024 个维度的向量数据库。可以接受用自然语言输入的问题,如:任老师对学习有怎样的见解?并在一个合理的时间内( 25s )给出回复:

我对目前的进展表示满意,并得出结论:assert(编程!=抽烟烫头喝着酒)。AI 工具的强大,不是为了让编程变得廉价和随意,而是将开发者从繁琐的实现中解放出来,让我们能更专注于定义问题和规划蓝图这些更高层次的创造性工作。这非但不是对专业性的削弱,反而是提出了更高的要求。
]]>于是做了这个用乘积推理数字的版本,玩起来挺上头的
规则
- 8x8 网格,数字范围 2-9
- 给出每行每列的乘积作为提示
- 根据乘积推出隐藏的数字
- 同行同列数字不重复
举个例子:某行乘积是 126 ,可能是 3×6×7 或 2×9×7 需要结合列的乘积交叉验证,有点烧脑但挺有意思。
演示视频
目前还在打磨中,想听听大家的意见:
- 这种玩法有没有人感兴趣?
- 不同难度设计是否合理?
- 有什么建议或想要的功能?
在线体验:https://factoku.com
欢迎试玩吐槽!
]]>- 支持自动专家生成
- 点击发言
- 白皮书生成
- 基于 Fast-MVP
效果 
好像遇到的大部分人都是这样,每年的车险有四五千,新能源更贵,但是问一问给自己配置了多少保险,基本都没有多少。
我觉得车子只是一个玩具和工具,人应该比车宝贵的多。同样的,花在自己身上的钱应该比花在车子身上的要多才对。
]]>我们是谁:已有前端+运营团队,创始人全栈背景,现启动新 AI 应用项目,急需一位技术核心伙伴!
🔧 你的角色
- 主导后端系统架构( Go 为主)
- 负责 AI 功能模块开发与集成( Python + LLM/AIGC 相关经验)
- 与产品、前端紧密协作,快速迭代上线
✅ 要求
- 熟练掌握 Go 语言(有高并发/微服务项目经验优先)
- 熟悉 Python,并有 AI 应用落地经验(如:智能对话、内容生成等)
- 能全职在广东中山办公(优先!公司位于中山城区,交通便利)
- 若无法全职坐班,可接受远程工作,但必须常住珠三角(深/广/佛/中/珠/莞),并能不定期邀请到线下开会
🤝 合作方式(二选一)
-
全职岗位(首选)
- 标准薪资:15K–18K/月(能力突出者可谈)
- 线下工作地点:广东中山(线下办公)
- 其他福利:弹性工作、项目奖金、年度调薪
-
技术合伙人(深度绑定)
- 基础薪资 + 可观股权(具体面议,可注册新公司)
- 共同决策产品方向,共享长期收益
🌟 我们的优势
- 项目已通过早期验证,非空想概念
- 团队执行力强,拒绝“纸上谈兵”
- 中山生活成本低、节奏舒适,适合专注做产品
📩 如何加入?
有兴趣了解的小伙伴可以联系 +V 详细沟通:www6688cx ,添加请备注:技术伙伴申请
]]>不知道是个例还是 M2 已经跟不上了?
]]>
首先我觉得如果是纯数字商品的话,那么可以天然规避掉退换货的问题,那么对仲裁的需求就会降到最低.
其次如何保证商家卖的商品与用户买的商品是一致的?
应该可以在上传的时候通过计算校验码来处理;
如何保证商家上传的商品不是一个 practical joke?
这一点可能需要引入一些信誉机制,使用 V 站用户绑定?信誉系统?亦或是通过记录交易数据来处理? 这一块我也一直没想好
如何保证商家的商品不会被交易市场恶意倒卖?
这一点我当时有过简单思考,但是一直没有什么好的答案,所以我改变了一下思路:
类似兑换码这类的商品可以交给商家来处理,这类商家应该是有基本的开发能力,我只需要提供几个标准接口给他们来实现校验,确认,发放等动作就可以了,具体细节可以再发散
如果这样的话,商家就有了两个选择: 1.直接将接口暴露给用户 c2c,增加被攻击风险,但是可以降低一些其他的成本 2.通过交易市场来托管代理, 交易市场充当第一层防护, 商家接口能减少一些压力
当然,如果是小额的类似商品完全可以托管给有信誉的交易市场来处理
如何保证买家不会被 practical joke 愚弄?
这一点其实我是想做一个中间合约,买家的钱直接放在合约中冻结,只有买家确认之后才会发给卖家,但是这样就会引出其他的问题: 如果买家是恶意用户怎么办?
针对这一点, 我当时的思考是偏向于仲裁的: 买卖双方都可以发起仲裁, 参与双方需要支付商品价格一定比例的费用, 胜方可以获得自己支付的费用以及仲裁涉及到的冻结金额, 败方支付的费用用来支付仲裁员的投票费用, 这样就引申出来一个新的问题: 如何实现一个去中心化的仲裁庭? 在这也不展开了, 可能是我考虑复杂了
如果是中心化托管的话,买卖双方的沟通没什么太大的问题,但是如果是去中心化的买卖双方沟通呢?
我目前搜集到了几个开源的产品, 在之前的帖子里面也发过, 我觉得可以稍微改造一下解决去中心化沟通的问题.
最后
大家一起来脑暴站长吧, 哈哈哈哈哈, 因为你的任何 idea 都可能对浏览的人造成一些影响, 或大或小
ps: 这个交易市场我其实是从 7 月底就开始构思,然后 8 月初开始列 todo 以及搜集资料,一直到现在我都还没有真正的开始写代码.
这中间我还有过很多的思考,这里就不啰嗦了,主要是这种产品太容易涉及洗钱和非法集资了,近几年国内对这块抓的很严,我身边很多朋友中招了,我也很慌😂
附几张 8 月份与 deepseek 高强度头脑风暴还有自己脑暴自己的截图



但是实际上程序员用 control 键更多,比如 control+c 来终止终端的程序,control+R 来进行搜索命令
更重要的 control 键的位置却被地球仪和 option 夹着,这个地方非常难按,而地球仪键这个位置却很好定位,因为直接就是最左下角
其实一般的键盘也都是把 control 放到左下角,然后 fn 键在 control 的右边
]]>目前加拿大临时居民超过 500 万,而在 2025 年就有超过 50 万人的签证即将过期,而目前加拿大移民局每年面向全球接受的移民数量只有 38 万左右,所以很多已经在加拿大的人注定无法拿到身份,而只能选择回国。
加拿大移民政策目前看来会越来越难,而目前唯一的便捷高效的方式便是法语通道移民。所以很多人就被迫卷入了法语学习,而我不幸就是滚滚浪潮中的一朵浪花。
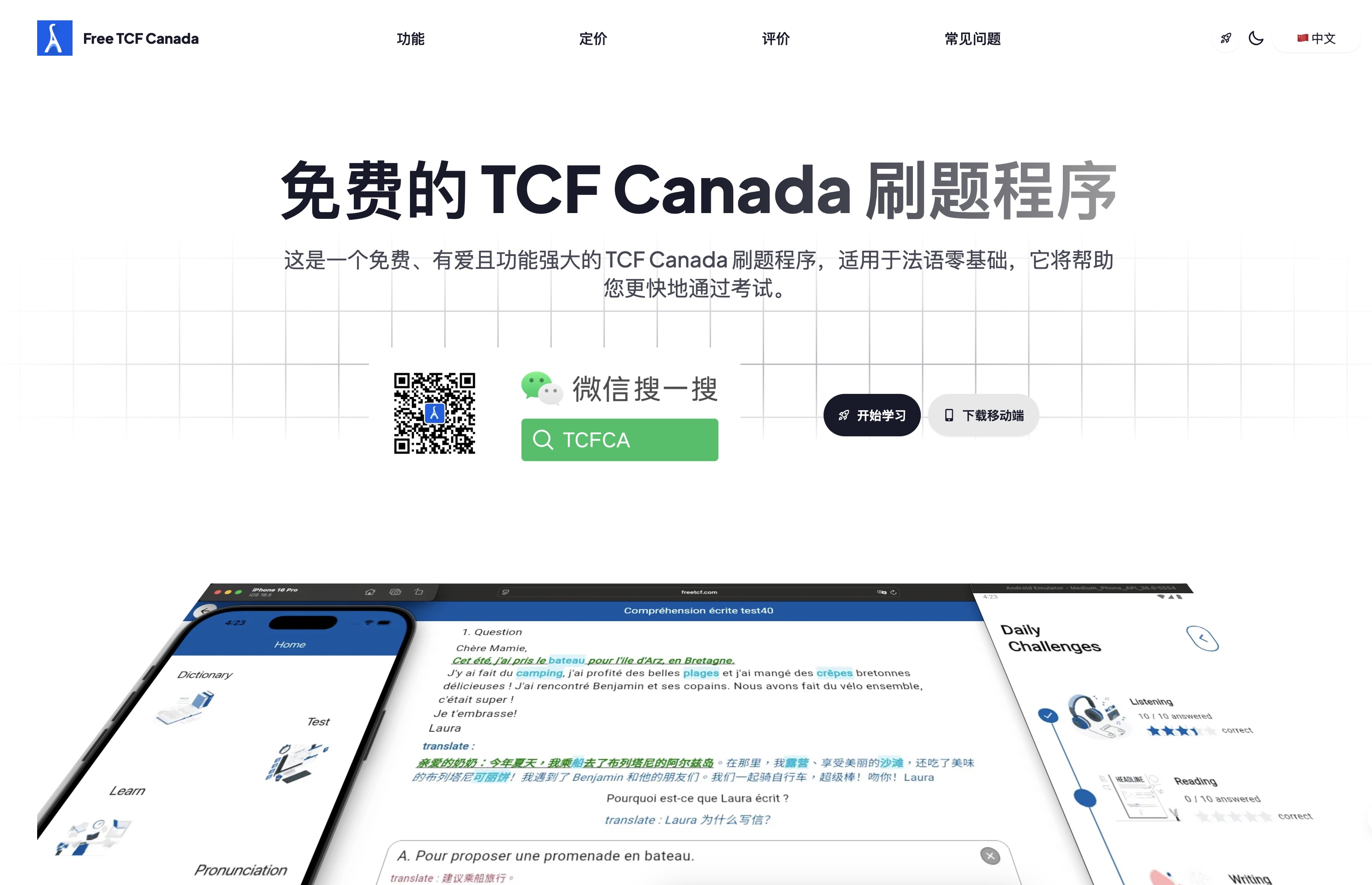
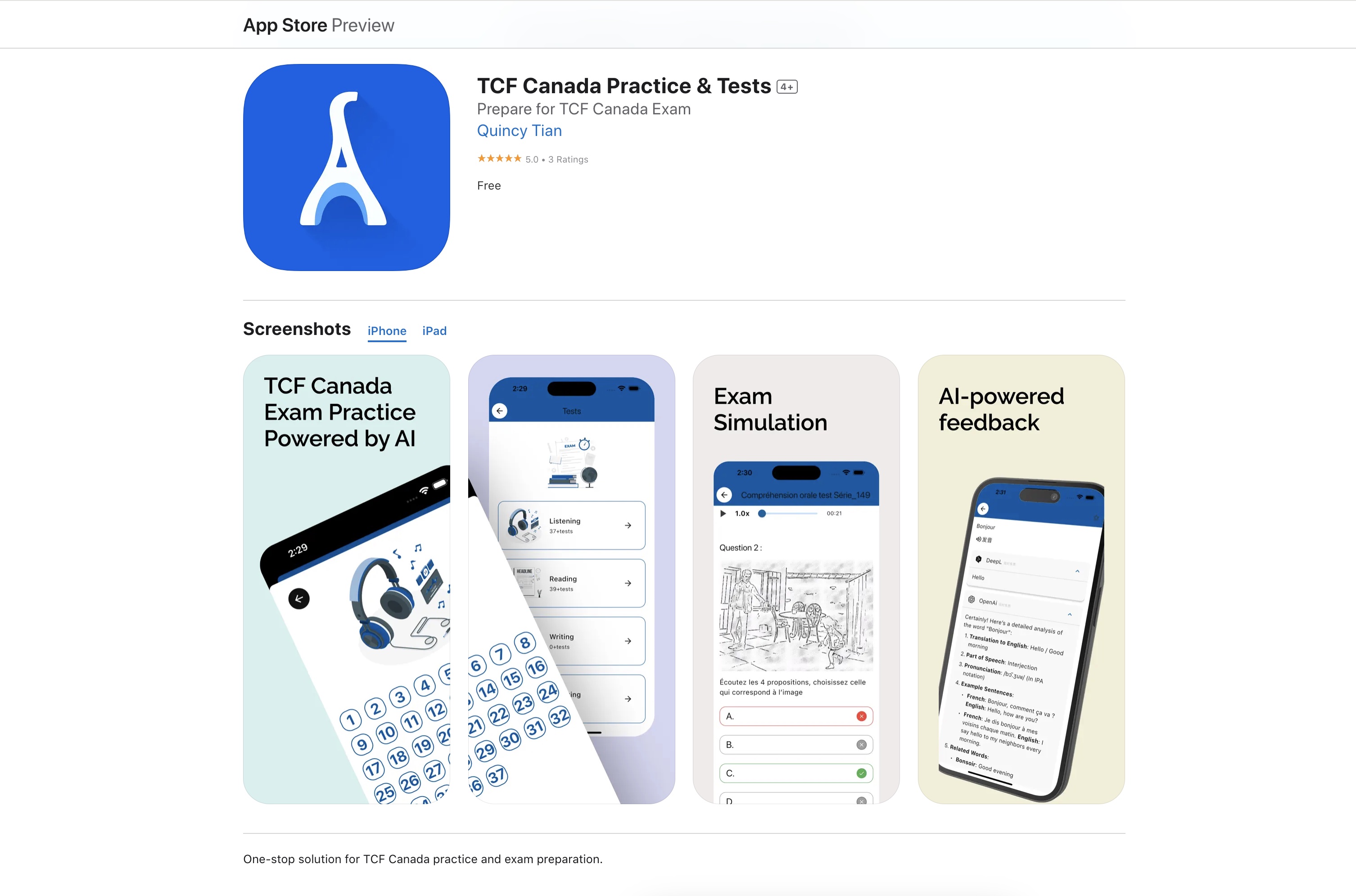
但是因为本人多年英语学习的成绩很差,知道语言学习毕竟是很难速成的,但是了解到加拿大移民法语考试是有稳定的题库,可以刷题在短期内把听力和阅读题目熟悉记住,所以考试其实考察的记忆力,而不是法语真实水平,我便根据网上流传的法语 TCF Canada 考试题库,做了一个免费的刷题程序,希望可以帮助自己快速高效的通过考试。
目前已经上线网页端 https://freetcf.com, apple store 和 Google Play。
一、主要招聘职位
Java/前端 /Go/Php/C++/算法 /Android/iOS/大数据 /数分等等职位大量招聘。
业务包括网约车 /国际化 /车服 /两轮车 /外卖 /专车 /快车 /金融 /大数据 /地图 /货运 /跑腿 /橙心优选 /智能驾驶 /代驾等。
二、主要待遇
① 有竞争力的薪资或期权
② 六险一金,父母及子女的商业保险
③ 全员 Mac ,免费晚餐
三、职位描述及要求
技术岗位主要在北京、杭州、成都、深圳。所有职位详情可见: http://talent.didiglobal.com/social/list/1 可在这里选择合适职位
四、内推方式
欢迎将合适职位链接及简历直接发送到 carlding123@163.com 内推。 任何问题或疑惑欢迎留言,有关系好的小伙伴也可以给我们推荐。 ]]>
结果收到的回复是: “别乱花钱” “攒钱买房子” “不要不务正业” “不要一天天就知道玩”
原话就不说了,总之就是这个态度,哎,我只能尽量保持每周通个视频,但是这种打压式沟通,真的不舒服,羡慕那种通达的父母,你们是怎么和父母沟通的。
]]>2.2022 款 ipad m2 原因:下班后的业余时间,主要的上网设备是台式机,其次是手机。很多次电量耗尽自动关机。我还得记着时不时的给它充电。使用频率更低。
3.佳明本能 2 手表 原因:硅胶材质的表带,带的稍紧一些非常容易起疹,带的稍微松一些感觉会滑动。睡觉,游泳的数据不是很准,一般也就骑车的时候戴戴,除了测心率好像手机完全能代替。使用频率也不高。
4.屏幕坏掉的手机 原因:留着也是垃圾,没有任何作用。
现在手里还有的电子产品: 美版 13pm, 国行 16pm, 如果不是因为有三个手机卡,我连 16pm 都想出掉。 台式机,配了一年,花了 1.3w, 配置不错,上网的主力设备。 mba, 今年刚买的,虽然用的不多,但是偶尔旅行,回老家还是用得着的。
人过三十,不知道是激素分泌少了,抑或其他什么原因,感觉对外界的很多东西都没有什么兴趣了,社交的需求也大幅减少。这种感觉是非常明显的。 国庆假日期间整理了一下身边的闲置的电子产品,都挂咸鱼了。仔细想想,大多数实在没有购买的必要,都是一时的兴起,新鲜尽头过后就吃灰,虽然出二手很亏,但是放在手里也是持续贬值,几乎发挥不了什么价值不如当断则断。 另外,提醒自己以后一定要理性消费。
]]>这是销量下滑厉害?投翔了?
]]>