
点开链接就看到"限时每月前 100 万次调用免费",
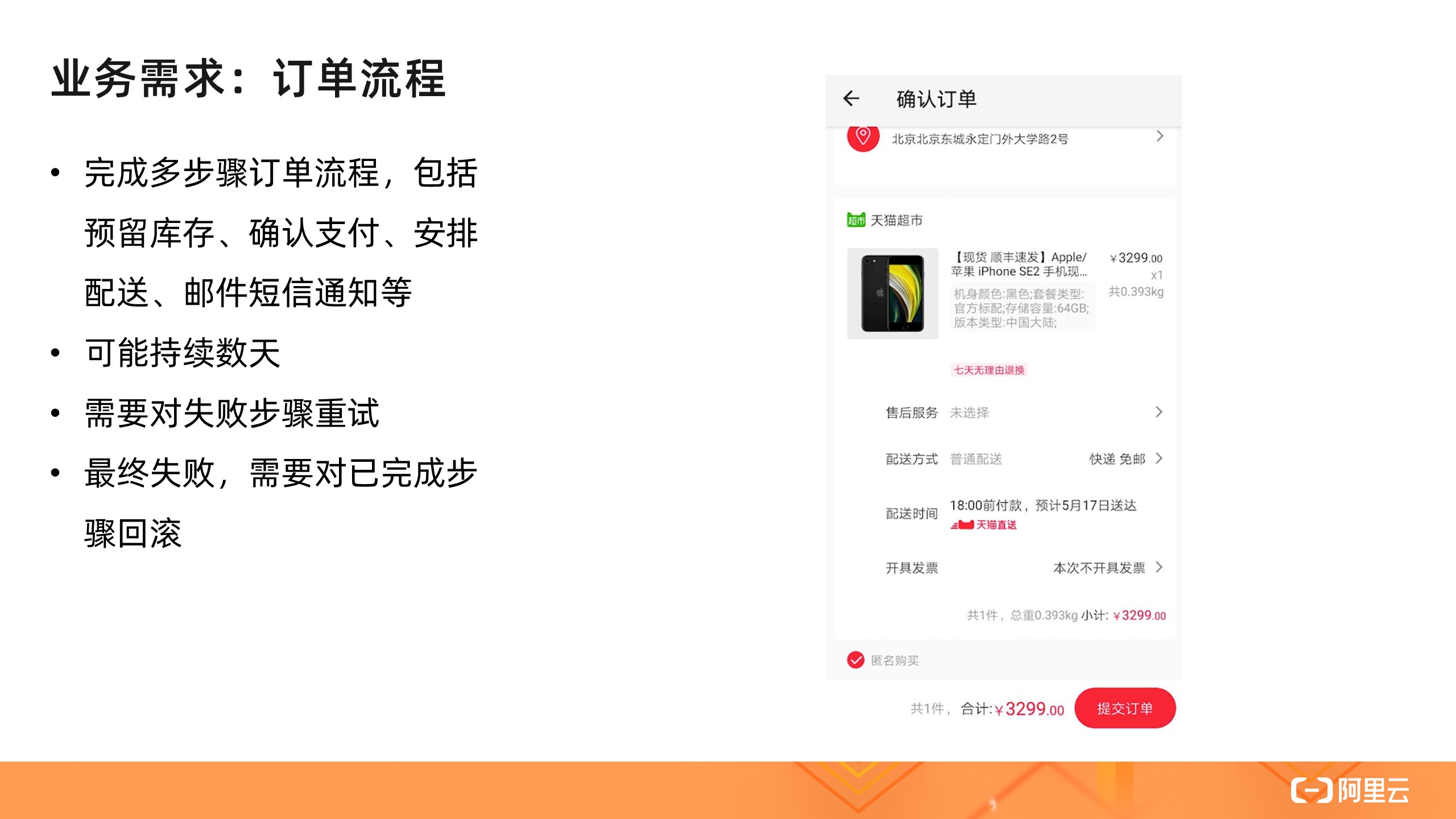
那么限时多久呢?到处点点点直到开通了看文档也没找到限时多久,
最后在资源包这里看到免费的额度居然也算资源包,活动时间就今天 10.31 截止,也就是说这个"每月",明天就没了?
理智认为不可能这么离谱,但是又怀疑厂商良心,
有没有熟悉这块的国内 serveless 有真免费的了吗,我没有刚需,但是免费的话会想试试,

 ]]>
]]>openfaas plonk 更接近 ci 和集群方面的工作,伸缩/httpserver 应用服务全是用容器来完成的,有点重和偏离中心 ]]>
公司名和配置文件都直接是 serverless ,误导性太强了。
现在本地开发和打包是绑定到 serverless framework 的生态下了。
想问下部署大家用的是什么工具啊,我现在是在网页上上传 zip 包。 ]]>
放到 csv 里面费内存,serverless 服务的还不太好调用。
Apache 有个 parquet 格式,不知道这个量级查询速度怎么样。
]]>addEventListener("fetch", event => { event.respondWith(handleRequest(event.request)) }) async function handleRequest(request) { let req = '<table>\n' req += `<tr>\n <td>method</td>\n <td>${request.method}</td>\n</tr>\n` request.headers.forEach((value, key)=>{ req += `<tr>\n <td>${key}</td>\n <td>${value}</td>\n</tr>\n` }) req += `<tr>\n <td>body</td>\n <td>${await request.text()}</td>\n</tr>\n` req += '</table>' return new Response(req, { headers: { 'content-type': 'text/html' } }) } async function handleRequest(request) { const urlObj = new URL(request.url) let url = urlObj.href.replace(urlObj.origin+'/', '').trim() if (0!==url.indexOf('https://') && 0===url.indexOf('https:')) { url = url.replace('https:/', 'https://') } else if (0!==url.indexOf('http://') && 0===url.indexOf('http:')) { url = url.replace('http:/', 'http://') } const respOnse= await fetch(url, { headers: request.headers, body: request.body, method: request.method }) let respHeaders = {} response.headers.forEach((value, key)=>respHeaders[key] = value) respHeaders['Access-Control-Allow-Origin'] = '*' return new Response( await response.blob() , { headers: respHeaders, status: response.status }); } addEventListener('fetch', event => { return event.respondWith(handleRequest(event.request)) }) 使用方法:
xxx.workers.dev/https://guge.com 可用于反代网页、json 甚至 image 等文件
]]>如 Cloudflare workers 的 runtime 使用的是 v8 引擎,所以只支持 Javascript 和 Wasm 。
Netlify functions 对 Javascript 的支持也比较好,支持的其他语言好像只有 Go.
想请问下这些云服务商为什么对 Javascript 的支持这么多?是因为我观察到的只支持 Javascript 的云服务商都是前端用的比较多的,所以支持 Javascript 利于直接转化。还是说 Javascript 在 serverless functions 中本身就具有别的语言不具有的优势?
]]>
作者 | 杨丽 出品 | 雷锋网产业组
“Serverless 其实离我们并没有那么遥远”。
如果你是一名互联网研发人员,那么极有可能了解并应用过 Serverless 这套技术体系。纵观 Serverless 过去十年,它其实因云而生,同时也在改变云的计算方式。如果套用技术成熟度曲线来描述的话,那么它已经走过了萌芽期、认知破灭期,开始朝着成熟稳定的方向发展。未来,市场对 Serverless 的接受程度将越来越高。
不要惊讶,阿里云团队在真正开始构建 Serverless 产品体系的最开始的一两年里,也曾遭遇内部的一些争议。而今,单从阿里集团内部的很多业务线来看,已经在朝着 Serverless 化的方向发展了。
日前,阿里云凭借函数计算产品能力全球第一的优势,入选 Forrester 2021 年第一季度 FaaS 平台评估报告,成为比肩亚马逊、全球前三的 FaaS 领导者。这也是首次有国内科技公司进入 FaaS 领导者象限。
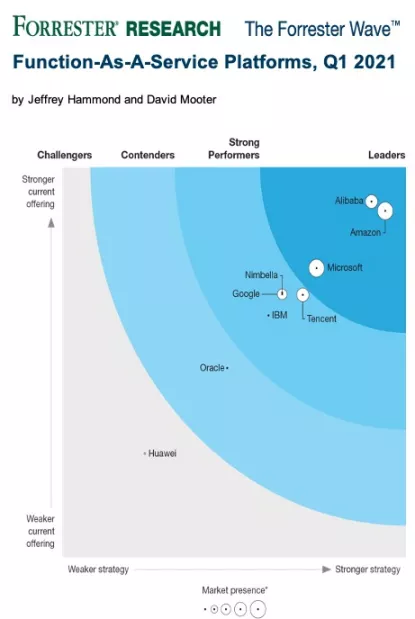
在与雷锋网的访谈中,阿里云 Serverless 负责人不瞋阐释了 Serverless 的演进历程、引入 Serverless 面临的难点与挑战、以及有关云原生的趋势预判。
“一定要想明白做这件事的终局是什么,包括产品体系的定位,对开发者、对服务商的价值等等这些问题。这要求我们不断通过实践和认识的深化,让这些问题的回答能够逐渐清晰起来。这也是我们这么多年实践积累的宝贵经验。”不瞋指出。
尽管企业的实践还存在种种疑惑和挑战,但 Serverless 实际上离我们并没有那么遥远。举一个最近的例子,新冠疫情让远程办公、在线教育、在线游戏的应用需求短期内增加。业务规模的爆发式增长,对每一个需求的响应需要更加及时,这对应用架构的弹性,对底层计算的速度,对研发效率的提升等,都要求业务加速向新技术架构演进。
而不瞋的理想就是,帮助更广泛的客户实现向新技术架构的平滑迁移,让 Serverless 渗透到所有的云应用中。
不瞋作为阿里云 Serverless 产品体系的负责人,也是国内 Serverless 的早期实践者。以下将呈现这次访谈的完整总结。
Serverless 的定义
在讨论之前,我们先明确 Serverless 的定义,确保大家对 Serverless 的认知是一致的。
现在 Serverless 越来越热,无论是工业界还是学术界,都将 Serverless 视为云计算发展的下一阶段。Serverless 有很多种表述,其中伯克利大学的定义相对严谨一些。
注:2019 年 2 月,加州大学伯克利分校发表的《 Cloud Programming Simplified: A Berkerley View on Serverless Computing 》论文,曾在业界引发诸多讨论和关注。
大致来讲,Serverless 实际对应的是一整套的产品体系,而不是单独一两个产品;同时,这些产品 /服务之间还具备以下特征:服务之间彼此配合、全托管、用户通过 API 调用就可完成整个功能或应用的开发而无需关注底层基础设施。
这套产品体系目前可分为两类:一类是计算,即 FaaS ( Function as a Service );还有一类是 BaaS ( Backend as a Service ),比如消息中间件、对象存储,都可以看做是 Serverless 化的 BaaS 服务。
Serverless 的演进
一个新技术通常会经历几个阶段:第一个阶段是因为其巨大潜力引起广泛关注的阶段;第二阶段,是认知破灭的阶段,在这个阶段由于产品初期本身能力不是很强健,或案例不全等因素,导致用户在使用过程中往往会遇到挫败感;第三个阶段,是伴随实践的增加和产品能力本身的发展,又会逐步提升认知,进而进入一个稳健增长的阶段。
需要明确的是,Serverless 并不是一个非常新的技术。像阿里云的 OSS 、AWS 的 S3 对象存储,它们都是最早发布的产品之一,一开始其实就是 Serverless 的形态。
但业界从 Serverless 的认知,确实是因 AWS 的 Lambda 带起来的,2014 年 AWS 推出了 Lambda 。
2017 年到 2019 年上半年,这段时间,业界对 Serverless 的讨论很多同时又有很多困扰,不知道如何落地,或者用了之后才突然觉得跟自己想象的不太一样。
国内外技术发展保持着相似的节奏,国外相对来讲更快一些。从去年开始,国内也开始进入到了稳定发展的阶段。现在国际上主流云供应商提供的新功能或新产品,80% 以上都是 Serverless 的形态。
阿里云从 2017 年开始打造 Serverless,并于当年正式启动商业化。
目前在阿里集团内部已经开始落地 Serverless 了,例如飞猪、淘宝、高德等等。在企业赋能方面,尤其是疫情之后,能够看到用户对 Serverless 的认知比之前确实深入了许多,在很多场景下,切换到 Serverless 架构确实能够为用户带来明显的收益,用户也认可这项技术。
举一项数据来看,目前阿里云 Serverless 已经服务了上万家付费客户,拥有 100+ 的典型案例,函数日调用量超过 120 亿次、函数总量达到 100 万。
新旧观念的转变
对于阿里云自身而言,在最开始构建 Serverless 之初,其实最大的挑战不仅仅是技术层面的,更多的还有观念上的不对称。
首先,Serverless 本身的形态跟以往的计算形态差异比较大,整个研发和运维的体系跟传统应用是割裂的。如果开发 Serverless 应用,其研发运维的流程和工具跟虚拟化( VM )或容器化的方式不太一样,很多用户会担心供应商锁定( lock-in )的问题,不太希望自身的技术栈跟某个供应商绑定。
其次,AWS 的 Lambda 最开始做了一个榜样,但它实际也只适合于 AWS 的产品体系,如果放在其他的产品体系里会面临非常大的挑战,不易于被用户接受,且限制条件也很多,应用场景也有限。这就要求在技术层面,包括资源调度、安全隔离、多租户管理、流控等方面有很高要求,做起来非常辛苦。因为在此之前没有一个产品的计算形态是如此细粒度、动态地使用资源。
这种挑战,一开始即便在阿里内部,也曾面临过许多争议。
我们这么多年实践积累的宝贵经验是:一定要想明白做这件事的终局是什么,包括在产品体系中的定位,对开发者、对云服务商的价值等等这些问题。这要求我们不断通过实践和认识的深化,让这些问题的回答能够逐渐清晰起来。

引入 Serverless 的顾虑
站在客户层面,不同类型的客户对引入第三方的 Serverless 技术其实会有不同层面的考虑。
对于超大型企业,比如 Facebook 、字节跳动,企业本身就有非常强的基础设施团队,通常他们会选择自己内部开发这方面技术。
还有一些企业,没有采用 Serverless 并不是说他们对这个技术有什么抵触,而是当下的落地实践或本身的工具链还无法做到完全消除供应商锁定的问题,又或者是因为工具链跟传统开发太过割裂,企业自身无法同时维护两套开发框架。
这种情况下,用户的系统架构一定会面临一个中间状态:既有老的又有新的。如果整个迁移的过程不是那么平滑的话,供应商的这部分优势在客户那里是不存在的, 因为老的系统实际是需要维护的。如此,对用户的吸引力其实就没有那么大了。
阿里云最近开源的 Serverless Devs 解决的就是这样的问题。其定位是帮助用户更简单地开发和运维自己的 Serverless 化和容器化应用,提供应用全生命周期管理的能力。
本质上,Serverless 的环境是在远端,跟用户本地开发环境是天然割裂的,那么在这个过程中,从调试、部署、发布、监控等各个环节,Serverless Devs 都希望能为用户提供更好的体验。但用户可自由使用其中一个或几个功能,不需要将已有的研发运维的流程完全迁移到我们定义的这套规范里。
过去一年的重大升级
2020 年,疫情的背景下,其实也是阿里云 Serverless 技术升级的关键一年。这一年里,团队做了很多大的升级,包括:
- 架构层面,已经升级到神龙裸金属服务器+袋鼠安全容器的下一代架构。好处是能够带来非常高的计算密度,进一步提升弹性能力和性能。
- 缓存方面,发布容器镜像加速技术,能够让 GB 级别的容器镜像非常快地实现秒级启动。目前已经演进到了下一代,通过阿里内部大规模业务场景进行打磨。
- 运行时方面,去年阿里云重写整个语言运行时,使得更具有可扩展性,启动速度更快。

(阿里云函数计算全景图)
总结起来,两方面因素推动阿里云 Serverless 在过去一年做出重大技术升级:
一是来自用户本身的诉求。比如在教育场景中,老师对开课这件事是有时效性要求的,这就要求后台能够短时间内启动可能数千个实例进行响应。
二是来自内部对产品效能的要求。对于云服务商而言,Serverless 最核心的一个定位,是能够将云上资源更好地利用起来。整个计算架构确实需要通过新的虚拟化技术、容器技术,同时跟新的硬件结合起来,从而提供一个非常细粒度的、启动非常快、非常弹性的计算模型。这也是为什么我们要进行架构升级,从原来的虚拟机架构演进到神龙裸金属服务器+袋鼠安全容器的架构,将对整体产品的发展产生一个核心推力。
攻克下一城
阿里云采用“三位一体”的策略打造整个 Serverless 产品矩阵——自身实践-开源-商业化。即通过集团内部超大规模、超复杂的业务场景来锤炼技术,将技术不断打磨产品化,然后对云上客户提供商业化服务,在这个过程中,还会将一些技术、工具进行开源,遵循开源开放的标准,跟开源生态融合。
只有对客户的业务产生价值和帮助,客户才会认可 Serverless 。
短期来看,无论是业务规模,还是产品、技术层面,阿里云 Serverless 都在以非常稳健地方式按照自身的节奏向前演进。
- 一是业务规模会更大,预计每年会有三倍以上的增长;
- 二是产品层面,以客户为中心,解决用户痛点仍然是首要的。今年将在产品细节体验上继续补强,在工具链、可观测性等方面为用户提供更好的体验;
- 三是技术层面,包括计算、网络、缓存、运行时等核心部分,继续夯实技术细节,实现极致性能。
云时代下的新机遇
在应用场景上来看,Serverless 不再仅仅是小程序,还有电商大促、音视频转码、AI 算法服务、游戏应用包分发、文件实时处理、物联网数据处理、微服务等场景。
Serverless 将继续和容器、微服务等生态融合,降低开发者使用 Serverless 技术的门槛,反过来也将促进传统应用的云原生化。
Serverless 另一个核心要素是“被集成”,被集成的对象有两类:
一类跟一方云服务进行接入,阿里云函数计算已被 30 多个一方云服务产品集成;
第二类是通过 EventBridge 事件总线和三方生态被集成。例如和钉钉等 SaaS 应用集成。钉钉的业务中常常需要以简洁、轻量的方式完成用户的定制化需求,这和 Serverless 的应用形态是高度匹配的。

(不瞋,阿里云 Serverless 负责人)
今天,我们可以非常明确地看到,整个云的未来一定是 Serverless 形态的。阿里云内部对这个也没有争议,因为这么多年来,整个产品体系就是朝着 Serverless 方向发展的。
不是因为有了 Serverless 计算,云才向 Serverless 演进。恰恰相反,因为云的产品体系已经向 Serverless 演进,才催生了 Serverless 计算。单纯的 Serverless 计算并不能实现很多功能,前提一定是跟其他云服务及其生态配合,才能体现出其自身的优势。
无论是工业界还是学术界,都已经认可这样一个趋势。
]]>
作者 | 李鹏(元毅) 来源 | Serverless 公众号
一、事件驱动框架:Knative Eventing
事件驱动是指事件在持续事务管理过程中,进行决策的一种策略。可以通过调动可用资源执行相关任务,从而解决不断出现的问题。通俗地说是当用户触发使用行为时对用户行为的响应。在 Serverless 场景下,事件驱动完美符合其设计初衷之一:按需付费。
1. Knative 模型

图:Knative 模型
Knative 主要包括两大部分:一是用于工作负载的 Serving,包括版本管理、灰度流量、自动弹性;二是 Eventing (事件驱动框架)。
-
核心玩家
- Google ;
- IBM ;
- Pivotal ;
- RedHat ;
- SAP 。
-
友商相关产品
- Google CloudRun ;
- IBM ;
- Pivotal Function Service(PFC);
- OpenShift 。
2. 事件驱动框架:Eventing

Knative 的 Eventing 提供了一个完整的事件模型,方便接入各个外部系统的事件。事件接入以后,通过 Cloud Event 标准在内部流转,结合 Broker-Trigger 模型进行事件处理。
从上图可以看到,Eventing 中包含三部分内容:
- 事件源
- Broker-Trigger:事件驱动模型,这个模型在早期 16 年的版本开始出现,其原理是 Trigger 订阅 Broker 信息并过滤,最后将事件发送到对应的服务进行消费。
- 消息系统:在 Eventing 中每个 Broker 下面对应一个消息的系统,来承载对事件的整个流转。目前社区支持的消息系统包括 Kafka 、NATS 、Rocket MQ 、Rabbit MQ 等。
3. 关键特性:事件规则

事件规则的核心是 Broker-Trigger 模型,它包含以下特性:
- Trigger 的 filter 的作用是对 Event 进行内容过滤;
- 支持对 Event 的 Attribute 以及 Data 的内容进行过滤;
- 支持 Common Expression Language ( CEL )表达式过滤;
- 支持通过 SourceAndType (事件源类型)进行过滤。
二、事件驱动引擎-事件源
1. 事件源介绍
Knative 社区中提供了丰富的事件源接入,包括 Kafka 、Github,也支持接入消息云产品的一些事件,比如 MNS 、RocketMQ 等。

如上图所示,接入事件源之后,可以通过 Broker-Trigger 模型请求相应的服务。这些服务包括一些具体场景,比如从源码构建镜像、自动化镜像发布、AI 音视频处理、定时任务等。所有的事件都需要这样的事件源来拉取,然后下发到 Eventing 整个事件流转过程。
-
事件接入
- 接入消息云产品事件源;
- 通过 MNS 接入更多云产品的事件。
-
事件处理
- Knative Eventing 内部实现事件的订阅、过滤和路由机制;
- 事件最终通过 Knative 管理的 Serverless 服务进行消费。
-
典型案例
- AI 音视频处理;
- 代码提交自动构建镜像。
2. RocketMQ 事件源

消息队列 RocketMQ 版是阿里云基于 Apache RocketMQ 构建的低延迟、高并发、高可用、高可靠的分布式消息中间件。
消息队列 RocketMQ 版既可为分布式应用系统提供异步解耦和削峰填谷的能力,同时也具备互联网应用所需的海量消息堆积、高吞吐、可靠重试等特性。
RocketMQSource 是 Knative 平台的 RocketMQ 事件源。其可以将 RocketMQ 集群的消息以 Cloud Event 的格式实时转发到 Knative 平台,是 Apahe RocketMQ 和 Knative 之间的连接器。
3. Kafka 事件源

消息队列 Kafka 版是阿里云基于 Apache Kafka 构建的高吞吐量、高可扩展性的分布式消息队列服务,广泛用于日志收集、监控数据聚合、流式数据处理、在线和离线分析等,是大数据生态中不可或缺的产品之一,阿里云提供全托管服务,用户无需部署运维,更专业、更可靠、更安全。
三、AI 事件驱动场景实践

以具体场景为例,该案例是一个直播系统,系统每天都有海量的直播访问,访问量根据直播热度随时变化,弹性有波动,同时存在不定时的增量。客户的诉求,一是业务弹性波动,消息并发性比较高;二是互动实时响应,要求低延迟。
为了满足对消息处理的弹性波动、高并发及低延迟的要求,客户选择阿里云的 Knative 服务进行数据的弹性处理。阿里云 Knative 完全契合了用户当前的诉求,并且在接入 K8s 标准之上,提供了基于事件和消息的弹性调度。
当应用实例数随着业务的波峰波谷进行扩容和缩容时,真正做到了按需使用、实时弹性的能力。整个过程完全自动化,减少业务开发人员在基础设施上的负担。在这个案例中,Knative 主要提供了三个能力:极致弹性、事件处理、开箱即用。
下面进行示例演示,演示内容主要有:
- 部署 Kafka 事件源
- 部署事件网关
- 部署服务
- 模拟事件处理
演示过程观看链接:https://developer.aliyun.com/live/246128
作者简介: 李鹏,花名:元毅,阿里云容器平台高级开发工程师,2016 年加入阿里, 深度参与了阿里巴巴全面容器化、连续多年支持双十一容器化链路。专注于容器、Kubernetes 、Service Mesh 和 Serverless 等云原生领域,致力于构建新一代 Serverless 平台。当前负责阿里云容器服务 Knative 相关工作。
]]>
作者 | 李鹏(元毅) 来源 | Serverless 公众号
一、Knative
Knative 提供了基于流量的自动扩缩容能力,可以根据应用的请求量,在高峰时自动扩容实例数;当请求量减少以后,自动缩容实例,做到自动化地节省资源成本。此外,Knative 还提供了基于流量的灰度发布能力,可以将流量的百分比进行灰度发布。
在介绍 Knative 灰度发布和自动弹性之前,先带大家了解一下 ASK Knative 中的流量请求机制。

如上图所示,整体的流量请求机制分为以下部分:
-
左侧是 Knative Service 的版本信息,可以对流量设置百分比;下面是路由策略,在路由策略里,通过 Ingress controller 将相应的路由规则设置到阿里云 SLB ;
-
右侧是对应创建的服务版本 Revision,在版本里对应有 Deployment 的资源,当流量通过 SLB 进来之后,直接根据相应的转发规则,转到后端服务器 Pod 上。
除了流量请求机制外,上图还展示了相应的弹性策略,如 KPA 、HPA 等。
二、Service 生命周期
Service 是直接面向开发者操作的资源对象,包含两部分的资源:Route 和 Configuration 。

如上图所示,用户可以通过配置 Configuration 里面的信息,设置相应的镜像、内容以及环境变量信息。
1. Configuration

Configuration 是:
- 管理容器期望的状态;
- 类似版本控制器,每次更新 Configuration 都会创建新的版本( Revision )。
如上图所示,与 Knative Service 相比较,Configuration 和它的配置很接近,Configuration 里配置的就是容器期望的资源信息。
2. Route

Route 可以:
- 控制流量分发到不同的版本( Revision );
- 支持按照百分比进行流量分发。
如上图所示,一个 Route 资源,下面包括一个 traffic 信息,traffic 里面可以设置对应的版本和每个版本对应的流量比例。
3. Revision

- 一个 Configuration 的快照;
- 版本追踪、回滚。
Knative Service 中版本管理的资源:Revision,它是 Configuration 的快照,每次更新 Configuration 就会创建一个新的 Revision,可以通过 Revision 实现版本追踪、灰度发布以及回滚。在 Revision 资源里面,可以直接地看到配置的镜像信息。
三、基于流量的灰度发布

如上图所示,假如一开始我们创建了 V1 版本的 Revision,这时如果有新的版本变更,那么我们只需要更新 Service 中的 Configuration,就会相应的创建出 V2 版本。然后通过 Route 对 V1 和 V2 设置不同的流量比例,上图中 V1 是 70%,V2 是 30%,流量会按照 7:3 的比例分别分发到两个版本上。一旦 V2 版本验证没有问题,接下来就可以通过调整流量比例的方式进行继续灰度,直到新的版本 V2 达到 100%。
在灰度的过程中,一旦发现新版本有异常,随时可以调整流量比例进行回滚。假设灰度到 30% 的时候,发现 V2 版本有问题,我们就可以把比例调回去,在原来的 V1 版本上设置流量 100%,实现回滚操作。
除此之外,我们还可以在 Route 中通过 traffic 对 Revision 打上一个 Tag,打完 Tag 之后,在 Knative 中会自动对当前的 Revision 生成一个可直接访问的 URL,通过这个 URL 我们可以直接把相应的流量打到当前的某一个版本上去,这样可以实现对某个版本的调试。
四、自动弹性
在 Knative 中提供了丰富的弹性策略,除此之外,ASK Knative 中还扩展了一些相应的弹性机制,接下来分别介绍以下几个弹性策略:
- Knative Pod 自动扩缩容 ( KPA );
- Pod 水平自动扩缩容 ( HPA );
- 支持定时 + HPA 的自动扩缩容策略;
- 事件网关(基于流量请求的精准弹性);
- 扩展自定义扩缩容插件。
1. 自动扩缩容-KPA

图:Knative Pod 自动扩缩容( KPA )
如上图所示,Route 可以理解成流量网关; Activator 在 Knative 中承载着 0~1 的职责,当没有请求流量时,Knative 会把相应的服务挂到 Activator Pod 上面,一旦有第一个流量进来,首先会进入到 Activator,Activator 收到流量之后,会通过 Autoscaler 扩容 Pod,扩容完成之后 Activator 把请求转发到相应的 Pod 上去。一旦 Pod ready 之后,那么接下来相应的服务会通过 Route 直接打到 Pod 上面去,这时 Activator 已经结束了它的使命。
在 1~N 的过程中,Pod 通过 kube-proxy 容器可以采集每个 Pod 里面的请求并发指数,也就是请求指标。Autoscaler 根据这些请求指标进行汇聚,计算相应的需要的扩容数,实现基于流量的最终扩缩容。
2. 水平扩缩容-HPA

图:Pod 水平自动扩缩容( HPA )
它其实是将 K8s 中原生的 HPA 做了封装,通过 Revision 配置相应的指标以及策略,使用 K8s 原生的 HPA,支持 CPU 、Memory 的自动扩缩容。
3. 定时+HPA 融合

- 提前规划容量进行资源预热;
- 与 CPU 、Memory 进行结合。
在 Knative 之上,我们将定时与 HPA 进行融合,实现提前规划容量进行资源预热。我们在使用 K8s 时可以体会到,通过 HPA 进行扩容时,等指标阈值上来之后再进行扩容的话,有时满足不了实际的突发场景。对于一些有规律性的弹性任务,可以通过定时的方式,提前规划好某个时间段需要扩容的量。
我们还与 CPU 、Memory 进行结合。比如某个时间段定时设置为 10 个 Pod,但是当前 CPU 对阈值计算出来需要 20 个 Pod,这时会取二者的最大值,也就是 20 个 Pod 进行扩容,这是服务稳定性的最基本保障。
4. 事件网关

- 基于请求数自动弹性;
- 1 对 1 任务分发。
事件网关是基于流量请求的精准弹性。当事件进来之后,会先进入到事件网关里面,我们会根据当前进来的请求数去扩容 Pod,扩容完成之后,会产生将任务和 Pod 一对一转发的诉求。因为有时某个 Pod 同一时间只能处理一个请求,这时候我们就要对这种情况进行处理,也就是事件网关所解决的场景。
5. 自定义扩缩容插件

自定义扩缩容插件有 2 个关键点:
- 采集指标;
- 调整 Pod 实例数。
指标从哪来?像 Knative 社区提供的基于流量的 KPA,它的指标是通过一个定时的任务去每个 Pod 的 queue-proxy 容器中拉取 Metric 指标。通过 controller 对获取这些指标进行处理,做汇聚并计算需要扩容多少 Pod 。 怎么执行扩缩容?其实通过调整相应的 Deployment 里面的 Pod 数即可。
调整采集指标和调整 Pod 实例数,实现这两部分后就可以很容易地实现自定义扩缩容插件。
五、实操演示
下面进行示例演示,演示内容主要有:
- 基于流量的灰度发布
- 基于流量的自动扩缩容
演示过程观看链接:https://developer.aliyun.com/live/246127
作者简介: 李鹏,花名:元毅,阿里云容器平台高级开发工程师,2016 年加入阿里, 深度参与了阿里巴巴全面容器化、连续多年支持双十一容器化链路。专注于容器、Kubernetes 、Service Mesh 和 Serverless 等云原生领域,致力于构建新一代 Serverless 平台。当前负责阿里云容器服务 Knative 相关工作。
]]>一种基于 Serverless 架构的 WordPress 全新部署方式
Serverless Wordpress 系列建站教程(二)
教你如何申请并绑定自定义域名
Serverless Wordpress 系列建站教程(三)
]]>使用 Serverless 建站是如何计费的?

作者 | 赵庆杰(卢令) 来源 | Serverless 公众号
一、Serverless 规模化落地集团的成果
2020 年,我们在 Serverless 底层基建上做了非常大的升级,比如计算升级到了第四代神龙架构,存储上升级到了盘古 2.0,网络上进入了百 G 洛神网络,整体升级之后性能提升两倍; BaaS 层面也进行了很大的拓展,比如支持了 Event Bridge 、Serverless Workflow,进一步提升了系统能力。
除此以外,我们还与集团内十几个 BU 进行了合作共建,帮助业务方落地 Serverless 产品,其中包含 双 11 核心的应用场景,帮助其顺利通过 双 11 流量峰值大考,证明了 Serverless 在核心的应用场景下,依然表现得非常稳定。

二、两大背景,两大优势 – 加速 Serverless 落地
1. Serverless 两大背景
为什么在集团内部能快速实现规模化地落地 Serverless ?首先我们有两大前提背景:
第一个背景是上云,集团上云是重要的前提,只有上云才能享受到云上的弹性红利,如果还是自己内部的一朵云,后续的起效降本其实非常难达成,所以 2019 年双十一阿里实现了核心系统 100% 上云,有了上云前提,Serverless 才有了发挥非常作用的空间。
第二个背景是全面云原生化,打造了一个强大的云原生产品的云家族,对集团内部业务进行赋能,帮助业务达成了在上云基础上的两个主要目标:提高效能和降低成本,2020 年天猫双十一核心系统全面云原生化,效率提升 100%,成本降低 80%。
2. Serverless 两大优势
- 提高效能

一个标准的云原生应用,从研发到上线到运维,需要完成上图中所有标橙色的工作项,才能完成正式的微服务应用上线,首先是 CI/CD 代码构建,另外是系统运维的可视化工作项目,不仅要配置、对接,还需对整体数据链路进行流量评估、安全评估、流量管理等,这显然对人力门槛要求已经非常高。除此以外,为了提升资源利用率,我们还需要对各个业务进行混部,门槛会进一步的提高。
可以看出,整体的云原生传统应用,要实现微服务上线所需要完成的工作项,对于开发者来说非常艰难,需要由多个角色进行完成,但是如果到 Serverless 时代,开发者只要完成上图中标蓝色的框 coding,后续剩下的所有工作项,Serverless 的研发平台可以直接帮助业务完成上线。
- 降低成本
提高效能主要指的是人力成本的节省,而降低成本则针对的是应用的资源利用率。普通应用我们需要为峰值预留资源,但波谷就会造成极大浪费。在 Serverless 场景下,我们只需要按需付费,拒绝为峰值预留资源,这是 Serverless 降低成本的最大优势。

以上两大背景和两大优势,符合技术上云的趋势,所以集团内部的业务方一拍即合,一些大的 BU 已经把 Serverless 落地升级为战役层面,加速业务落地的 Serverless 场景。目前在集团落地的 Serverless 场景已经非常丰富,涉及到了核心的一些应用、个性化推荐、视频处理,还有 AI 推理、业务巡检等等。
三、Serverless 落地场景 – 前端轻应用
目前,集团内前端场景是应用 Serverless 最快、最广的场景,包含淘系、高德、飞猪、优酷、闲鱼等 10+ 以上 BU 。那为什么前端场景适合 Serverless 呢?

上图是全栈工程师的能力模型图,一般的微应用中需要有三个角色:前端工程师、后端开发工程师,运维工程师,三者共同完成应用的上线发布。为了提高效能,最近几年出现了全栈工程师的角色,作为全栈工程师,他要具备这三个角色的能力,不仅需要前端的应用开发技术,还需要后端系统层面的开发技能,并且要关注底层的内核、系统资源管理等,这对于前端工程师来说门槛显然非常高。
最近几年 Node.js 技术兴起,能够替代后端开发工程师角色,前端工程师只要具备前端开发能力,就可以充当两个角色,即前端工程师和后端开发工程师,但运维工程师仍然无法被取代。
而 Serverless 平台,解决的就是上图三角形结构中的底部三层,极大降低了前端工程师转变为全栈工程师的门槛,这对前端业务开发者来说非常有诱惑力。

另外一个原因是业务特性符合,大部分的前端应用具有流量洪峰的特性,需要业务评估前置,存在评估成本;同时前端场景更新迭代快,快上快下,运维成本高;且缺乏动态扩缩能力,存在资源碎片及资源浪费。而如果使用 Serverless,平台会自动帮你解决以上所有的后顾之忧,所以 Serverless 对前端场景的诱惑力非常大。
1. 前端落地场景

上图列举了前端落地的几个主要场景和技术点:
BFF 转换成 SFF 层:BFF 主要是 Backend For Frontend,前端工程师做主要运维,但到了 Serverless 时代,运维完全交于 Serverless 平台,前端工程师只需要写业务代码,就可以完成这项工作。
瘦身:把前端的业务逻辑下沉到 SFF 层,由 SFF 层去做逻辑的复用,把运维的能力也交给 Serverless 平台,实现客户端轻量化,提效功能下沉。
云端一体化:一处代码多端应用,这是非常流行的开发框架,同样需要 SFF 作为支撑。
CSR/SSR:通过 Serverless 满足服务端渲染、客户端渲染等,来实现前端首屏的快速展现,Serverless 结合 CDN 整体可以作为前端加速的解决方案。
NoCode:相当于在 Serverless 平台上做了封装,只需拖拽几个组件,就可以搭建一个前端页面,每个组件都可以用 Serverless 进行包装、功能聚合等,达到 NoCode 的效果。
中后台场景:主要是单体的富应用场景,单体应用可以完全用 Serverless 模式进行托管,完成中后台应用上线,这同样也可以节省运维能力、减少成本。
2. 前端 Coding 变化
在前端场景应用 Serverless 之后,coding 有哪些变化呢?

对前端有一定了解的都知道,前端一般分三层:State 、View 和 Logic Engine,同时会把一些抽象的业务逻辑下沉到 FaaS 层云函数上,然后用云函数作为 FaaS API 来提供服务,在代码编写上可以抽象各类 Aaction,每个 Aaction 可以有 FaaS 函数 API 提供服务。

以一个简单的页面为例,页面左侧是一些渲染接口,可以获取商品详情、收货地址等,这是基于 Faas API 实现的;右侧的是一些交互逻辑,比如购买、添加等,这也是 Faas API 可以继续完成的任务。
页面设计中,所有的 Faas API 不是只能为一个页面所使用,它可以为多个页面复用。复用这些 API 或者进行拖拽之后,就可以完成前端页面的组装,这对于前端来说是非常方便的。
3. 前端轻应用研发提效:1-5-10

在前端应用 Serverless 之后,我们把 Serverless 对前端的研发效能的提效简单总结为 1-5-10,其含义是:
1 分钟的快速开始:我们把各类主要场景做一个总结,将其归类为应用模板,每个用户或者业务方新起一个业务时,只需要选择相应的应用启动模板,就会帮助用户快速生成业务代码,用户只需要写自己的业务函数代码就可以快速开始。
5 分钟上线应用:完全复用 Serverless 的运维平台,利用平台天然能力,帮助用户完成灰度发布等能力;并且配合前端网关、切流等完成金丝雀测试等功能。
10 分钟排查问题:基于上线之后的 Serverless 函数,提供业务指标或系统指标的展示,通过指标不仅可以设置报警,还可以在控制台上给用户推送错误日志等,帮助用户快速定位问题、分析问题,10 分钟内掌握整个 Serverless 函数的健康状态。
4. 前端落地 Serverless 效果
前端实现 Serverless 的场景后效果如何?我们将 3 款 APP 在传统应用研发模式下所需要的性能和工时与应用 Faas 场景之后进行对比,可以明显看到,在原有的云原生基础上,效能还能提升 38.89%,这对于 Serverless 应用或前端应用来说效果非常可观,目前 Serverless 场景已经几乎覆盖整个集团内部,帮助业务方实现 Serverless 化,实现提高效能和降低成本两个主要目标。
四、技术输出,拓展新场景
在集团的 Serverless 落地过程中,我们发现了很多新的业务诉求,比如存量业务如何快速实现迁移并节省成本?执行时间是否可以调大或者调长?资源配置是否可以调高?等等,针对这些问题我们提出了一些解决方案,基于这些解决方案我们抽象出了产品的一些功能,接下来介绍几个比较重要的功能:
1. 自定义镜像

自定义镜像主要目的是实现存量业务的无缝迁移,帮助用户实现零代码改造,并且把业务代码完全迁移到 Serverless 平台上。
存量业务的迁移是非常大的痛点,在一个团队内,不可能长期存在两种研发模式,这会造成极大内耗。想让业务方迁移到 Serverless 研发体系下,必须推出彻底的改造方案,帮助用户实现 Serverless 体系改造,不仅需要支持新业务使用 Serverless,还要帮助存量业务实现零成本快速迁移,所以我们推出了自定义容器功能。

传统 Web 单体应用场景特性:
- 应用现代化细粒度责任拆分、服务治理等运维负担;
- 历史包袱不易 Serverless 化:云上云下业务代码,依赖、配置不统一;
- 容量规划,自建运维、监控体系;
- 资源利用率低 (低流量服务独占资源)。
函数计算 + 容器镜像优势:
- 低成本迁移单体应用;
- 免运维;
- 无需容量规划,自动伸缩;
- 100% 资源利用率,优化闲置成本。
自定义容器功能,可以让传统 Web 单体应用(比如 SpringBoot 、Wordpress 、Flask 、Express 、Rails 等框架)不需任何改造,就可以以镜像的方式迁移到函数计算上,避免低流量业务独占服务器造成资源浪费。同时也可以享受到无需为应用做容量规划、自动伸缩、免运费等效益。
2. 性能实例

高性能实例,减少使用限制,拓展更多场景。比如:代码包从原来的 50M 上升到 500M,执行时间从原来的 10 分钟提高到 2 小时,性能规格比原先提升 4 倍多,能够最大支持 16G 和 32G 的大规格实例,来帮助用户运行一些非常耗时的长任务等等。

函数计算服务了很多场景,在服务过程中我们收到了很多诉求,比如约束条件多、使用门槛高、计算场景资源不足等问题。所以针对这些场景,我们推出了性能实例功能,目标是减少函数计算应用场景的使用限制,降低使用门槛,并且在执行时长上、各种指标上,用户可以灵活配置、按需配置。
目前我们支持的 16 核 32G 完全具备与同规格 ECS 一模一样的计算能力,可以适用于高性能的业务场景如 AI 推理、音视频转码等。这个功能对后续拓展应用场景来说非常重要。
挑战:
- 弹性实例约束条件多,有一定使用门槛,如执行时长、实例规格等;
- 传统单体应用、音视频等重计算场景下,业务需要拆分改造,增加负担;
- vCPU 、内存、带宽等资源维度,弹性实例未给出明确承诺。
目标:
- 减小函数计算的使用限制,降低企业使用门槛;
- 兼容传统应用和重计算场景;
- 给用户明确的资源承诺。
做法:
- 推出更高规格、资源承诺更明确的性能实例;
- 未来,性能实例将具备更高的稳定性 SLA 、更丰富的功能配置。
主打场景: 计算型任务、long-running 任务、弹性伸缩不敏感任务。
- 音视频转码处理;
- AI 推理;
- 其它需求高规格的计算场景。
优势:
性能实例除放宽限制外,仍保留当前函数计算产品所具备的所有能力:按量付费、预留模式、单实例多请求、多种事件源集成、多可用区容灾、自动伸缩、应用的构建部署及免运维等。
3. 链路追踪

链路追踪功能包括:链路还原、拓扑分析、问题定位。
一个正常的微服务,不是一个函数就能完成所有工作,需要依赖上下游服务。在上下游业务都是正常的情况下,一般不需要链路追踪,但是如果下游服务出现了异常,如何定位问题?这时就可以依赖链路追踪功能,迅速分析上下游的性能瓶颈或者定位问题的发生点等。
函数计算也调研了很多集团内外的开源技术方案,目前已经支持 X-trace 功能,并且兼容了开源方案,拥抱开源,提供了兼容 OpenTracing 的产品能力。


上图是链路追踪的 Demo 图,通过计算 tracing 可以可视化看到后端服务的数据库访问开销,避免大量服务间的复杂校验关系增加问题排查的难度等。函数计算还支持函数代码级的链路分析能力,帮助用户优化冷启动、关键代码实现等。
Serverless 产品在业务角度上带来了巨大收益,但是封装也带来了一个阶段性难题——黑盒问题。当我们向用户提供链路追踪技术,同时也把黑盒问题暴露给用户,用户也可以通过这些黑盒问题提升自身的业务能力。这也是 Serverless 未来提高用户体验的方向,后续我们会在这方面继续加大投入,降低用户使用 Serverless 的成本。
挑战:
- Serverless 产品在业务角度有巨大收益,但封装带来黑盒问题;
- Serverless 连接云生态,大量的云服务造成调用关系复杂;
- Serverless 开发者依然有链路还原、拓扑分析、问题定位等需求。
FC + x-trace 主要优势:
- 函数代码级链路分析,帮助优化冷启动等关键代码实现;
- 服务调用级链路追踪,帮助串联云生态服务,分布式链路分析。
4. 异步配置

在 Serverless 场景下,我们提供了离线任务处理、消息对立消费等功能,在函数计算中这类功能的使用率占比 50% 左右。在大量消息消费中,存在很多异步配置问题经常被业务方挑战,比如,这些消息是从哪里来?又去到哪里?被什么服务消费?消费的时间?消费的成功率如何?等等。这些问题的可视化 /可配置,是目前需要主要解决的重要课题。

上图为异步配置的工作原理,首先从用户指定的事件源开始触发异步调用,函数计算立即返回请求 ID,同时也可以调用执行函数,返回执行结果到函数计算或者消息队列 MNS 里面。然后通过事件源可配置触发器等等,这些效果或者主题消费,可以进行消息的再次消费。比如,如果一个消息处理失败了,可以配置一下进行二次处理。

典型的应用场景:
- 一是事件闭环,比如对投递结果(如收集监控指标、报警配置)进行结果分析;生产事件上客户不仅可以利用 FC 消费事件,也可以利用 FC 主动生产事件。
- 二是日常的异常处理,比如失败处理、重试策略等。
- 三是资源回收,用户可以自定义存货时间,及时丢弃无用消息,节省资源,这是异步场景非常大的优化。
作者简介: 赵庆杰(卢令),目前就职于阿里云云原生 Serverless 团队,专注于 Serverless 、PaaS,分布式系统架构等方向,致力于打造新一代的 Serverless 技术平台,把平台技术做到更加普惠。曾就职于百度,负责内部最大的 PaaS 平台,承接了 80% 的在线业务,在 PaaS 方向,后端分布式系统架构等领域有丰富的经验。
]]>本文整理自 [ Serverless Live 系列直播] 1 月 26 日场 直播回看链接:https://developer.aliyun.com/topic/serverless/practices


作者 | aoho 来源 | Serverless 公众号
Serverless 是什么?
Serverless 架构是不是就不要服务器了?回答这个问题,我们需要了解下 Serverless 是什么。
Serverless 架构近几年频繁出现在一些技术架构大会的演讲标题中,很多人对于 Serverless,只是从字面意义上理解——无服务器架构,但是它真正的含义是开发者再也不用过多考虑服务器的问题,当然,这并不代表完全去除服务器,而是我们依靠第三方资源服务器后端,从 2014 年开始,经过这么多年的发展,各大云服务商基本都提供了 Serverless 服务。比如使用 Amazon Web Services(AWS) Lambda 计算服务来执行代码。

国内 Serverless 服务的发展相对 AWS 要晚一点,目前也都有对 Serverless 的支持。比较著名的云服务商有阿里云、腾讯云。它们提供的服务也大同小异:函数计算、对象存储、API 网关等,非常容易上手。
架构是如何演进到 Serverless ?
看看过去几十年间,云计算领域的发展演进历程。总的来说,云计算的发展分为三个阶段:虚拟化的出现、虚拟化在云计算中的应用以及容器化的出现。云计算的高速发展,则集中在近十几年。
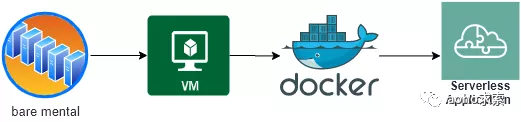
总结来说有如下的里程碑事件:
- 通过虚拟化技术将大型物理机虚拟成单个的 VM 资源。
- 将虚拟化集群搬到云计算平台上,只做简单运维。
- 把每一个 VM 按照运行空间最小化的原则切分成更细的 Docker 容器。
- 基于 Docker 容器构建不用管理任何运行环境、仅需编写核心代码的 Serverless 架构。
从裸金属机器的部署应用,到 Openstack 架构和虚拟机的划分,再到容器化部署,这其中典型的就是近些年 Docker 和 Kubernetes 的流行,进一步发展为使用一个微服务或微功能来响应一个客户端的请求 ,这种方式是云计算发展的自然过程。
这个发展历程也是一场 IT 架构的演进,期间经历了一系列代际的技术变革,把资源切分得更细,让运行效率更高,让硬件软件维护更简单。IT 架构的演进主要有以下几个特点:
- 硬件资源使用颗粒度变小
- 资源利用率越来越高
- 运维工作逐步减少
- 业务更聚焦在代码层面
1. Serverless 架构的组成
Serverless 架构分为 Backend as a Service(BaaS) 和 Functions as a Service(FaaS) 两种技术,Serverless 是由开发者实现的服务端逻辑运行在无状态的计算容器中,它是由事件触发、完全被第三方管理的。
2. 什么是 BaaS?
Baas 的英文翻译成中文的含义:后端即服务,它的应用架构由大量第三方云服务器和 API 组成,使应用中关于服务器的逻辑和状态都由服务提供方来管理。比如我们的典型的单页应用 SPA 和移动 APP 富客户端应用,前后端交互主要是以 RestAPI 调用为主。只需要调用服务提供方的 API 即可完成相应的功能,比如常见的身份验证、云端数据 /文件存储、消息推送、应用数据分析等。
3. 什么是 FaaS?
FaaS 可以被叫做:函数即服务。开发者可以直接将服务业务逻辑代码部署,运行在第三方提供的无状态计算容器中,开发者只需要编写业务代码即可,无需关注服务器,并且代码的执行是由事件触发的。其中 AWS Lambda 是目前最佳的 FaaS 实现之一。
Serverless 的应用架构是将 BaaS 和 FaaS 组合在一起的应用,用户只需要关注应用的业务逻辑代码,编写函数为粒度将其运行在 FaaS 平台上,并且和 BaaS 第三方服务整合在一起,最后就搭建了一个完整的系统。整个系统过程中完全无需关注服务器。
Serverless 架构的特点
总得来说,Serverless 架构主要有以下特点:
- 实现了细粒度的计算资源分配
- 不需要预先分配资源
- 具备真正意义上的高度扩容和弹性
- 按需使用,按需计费
由于 Serverless 应用与服务器的解耦,购买的是云服务商的资源,使得 Serverless 架构降低了运维的压力,也无需进行服务器硬件等预估和购买。
Serverless 架构使得开发人员更加专注于业务服务的实现,中间件和硬件服务器资源都托管给了云服务商。这同时降低了开发成本,按需扩展和计费,无需考虑基础设施。
Serverless 架构给前端也带来了便利,大前端深入到业务端的成本降低,开发者只需要关注业务逻辑,前端工程师轻松转为全栈工程师。
Serverless 有哪些应用场景?
应用场景与 Serverless 架构的特点密切相关,根据 Serverless 的这些通用特点,我们归纳出下面几种典型使用场景:弹性伸缩、大数据分析、事件触发等。
1. 弹性伸缩
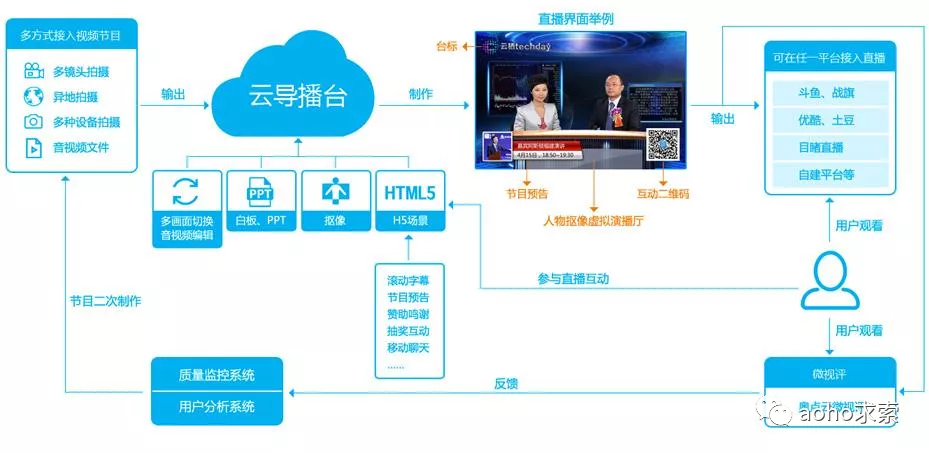
由于云函数事件驱动及单事件处理的特性,云函数通过自动的伸缩来支持业务的高并发。针对业务的实际事件或请求数,云函数自动弹性合适的处理实例来承载实际业务量。在没有事件或请求时,无运行实例,不占用资源。如视频直播服务,直播观众不固定,需要考虑适度的并发和弹性。直播不可能 24 小时在线,有较为明显的业务访问高峰期和低谷期。直播是事件或者公众点爆的场景,更新速度较快,版本迭代较快,需要快速完成对新热点的技术升级。
2. 大数据分析
数据统计本身只需要很少的计算量,离线计算生成图表。在空闲的时候对数据进行处理,或者不需要考虑任何延时的情况下。
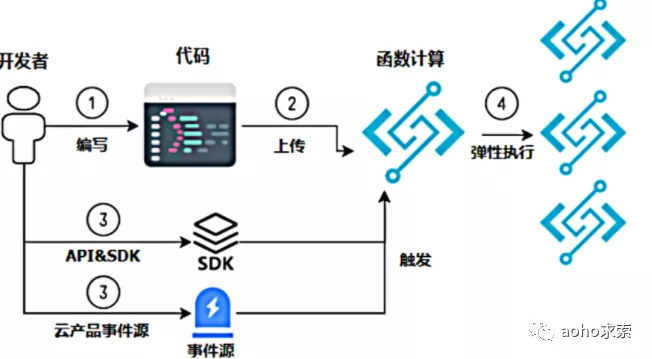
-
开发者编写代码,目前支持的语言 Java 、NodeJS 、Python 等语言;
-
把代码上传到函数计算上,上传的方式有通过 API 或者 SDK 上传,也可以通过控制台页面上传,还可以通过命令行工具 Fcli 上传;
-
通过 API&SDK 来触发函数计算执行,同样也可以通过云产品的事件源来触发函数计算执行;
-
函数计算在执行过程中,会根据用户请请求量动态扩容函数计算来保证请求峰值的执行,这个过程对用户是透明无感知的;
-
函数执行结束。
3. 事件触发
事件触发即云函数由事件驱动,事件的定义可以是指定的 http 请求,或者数据库的 binlog 日志、消息推送等。通过 Serverless 架构,在控制台上配置事件源通知,编写业务代码。业务逻辑添加到到函数计算里,业务高峰期函数计算会动态伸缩,这个过程不需要管理软硬件环境。常见的场景如视频、OSS 图片,当上传之后,通过进行后续的过滤、转换和分析,触发一系列的后续处理,如内容不合法、容量告警等。
小结
回到我们文章的开头,Serverless 架构不是不要服务器了,而是依托第三方云服务平台,服务端逻辑运行在无状态的计算容器中,其业务层面的状态则被开发者使用的数据库和存储资源所记录。
Serverless 无服务器架构有其适合应用的场景,但是也存在局限性。总得来说,Serverless 架构还不够成熟,很多地方尚不完善。Serverless 依赖云服务商提供的基础设施,目前来说云服务商还做不到真正的平台高可用。Serverless 资源虽然便宜,但是构建一个生产环境的应用系统却比较复杂。
云计算还在不断发展,基础设施服务日趋完善,开发者将会更加专注于业务逻辑的实现。云计算将平台、中间件、运维部署的责任进行了转移,同时也降低了中小企业上云的成本。让我们一起期待 Serverless 架构的未来。
参考:
]]>
作者 | Mike Butusov 来源 | Serverless 公众号
在过去的 5 年里,使用云厂商处理应用后台的流行程度大幅飙升。其一,初创企业主采用 Serverless 方式,以节省基础设施成本,并随用随付。随着公司规模的扩大,依靠第三方供应商可以使其快速获得后端资源。
其二,虽然实现基于云的基础设施主要在初创企业主中流行,但大型公司也会使用分布式架构。Amazon Polly (一种将文本转换为逼真语音的服务)就完全依靠 AWS 来提供项目支持。
在本文中,我们主要聊聊 Serverless 对于初创公司最突出的优势。你将会发现,为你的下一个项目选择分布式应用是非常正确的。
创业公司使用 Serverless 的好处
Serverless 允许企业主只在用户请求或事件被触发时才为服务器付费。因此,技术团队消除了闲置时间,确保他们不会为服务器电源支付额外费用。除此之外,通过 Serverless 化,初创企业的管理者可以雇佣更少的人才进行项目维护,从而可以专注于推广公司的核心服务。
成本和时间效率并不是初创公司在 Serverless 中的唯一好处。让我们仔细看看分布式架构的优势。
1. 简单部署和持续交付
与基于服务器的架构不同,基于分布式系统的后台更容易设置和部署。将源码连接到你选择的任何一个安全的 Serverless 创业公司供应商平台( AWS 、Google 、Azure 等),就可以部署项目了。
持续交付是初创企业使用 Serverless 产生的另一个好处。代码的每一个变化都会在测试后自动部署。整个过程都是自动化的,团队无需对每一次更新进行监控。
2. 节约基础设施成本
如上所述,Serverless 架构是企业主控制基础架构方面支出的有效方式。如果一个初创网站的访问量少于 1000 人,改用现收现付的模式,可以削减高达 90% 的后台维护和资源成本。要了解 Serverless 的全部成本效益,不妨看看这些 Serverless 企业创业案例:
-
一家名为 Heavywater 的初创公司在选择使用 Serverless 架构后,维护后台成本从 4000 美元降至 30 美元;
-
Nordstrom 的创始人利用 Serverless 基础架构的高扩展潜力和降低成本的能力,来支持一个高流量的网络应用。该公司使用 AWS Lambda 和 APIs Gateway 作为项目的技术骨干;
-
Postlight 的初创公司创始人通过转向 Serverless 来处理高额的后端支出,将基础设施成本从每月 1 万美元降至 370 美元。
3. 无限扩展性
在服务器上的应用有扩展性的限制。这意味着越来越多的用户需要重建和翻新应用的技术架构。这也是为什么那些优先考虑流量或用户获取的初创公司,更倾向于使用 Serverless 的原因,因为它具有无限的扩展能力。
随着请求数量的增长,厂商的服务器会为其自动提供应用所需的服务器能力。因此,Serverless 应用管理团队不会因突然的流量激增而措手不及。
4. 更强的灵活性
Serverless 具备的灵活性是它在初创企业中如此受欢迎的原因之一。在某些时候,公司经营者会意识到企业当前的目标受众不够精准,因此,需要进行重新调整。那么将一项服务分离成几个小的服务,针对新的受众设置意向服务就非常有必要。
以下是 Serverless 实际应用中灵活性的表现:
-
增加了产品的灵活性,让创建微服务变得更容易;
-
容器的使用,让修改产品的部分内容变得更加容易,而不至于让整个系统崩溃;
-
增加目标客户触达量,无限的扩展能力让企业在不丢失现有客户的前提下,提供了接触新目标用户的可能。
5. 真实可复用性
由于创建的元素可以复用,Serverless 架构让项目开发变得更加容易。那究竟为什么 Serverless 比其他基础架构类型具备更高的可重复利用性呢?
这是由于大多数 Serverless 函数都是以 HTTP 请求的形式提供的,并且不依赖源代码来运行。在 Lambda 函数上使用层,通过创建封装的、可测试的代码,也能促进可重用性。由于 Serverless 非常适合短期的、无状态的代码,所以大多数事件驱动的结构(如微服务)通常都是 Serverless 的。
结论
虽然距离 Serverless 成为主流技术还有一段路要走,但不可否认的是,已经有越来越多的初创企业选择分布式应用模式。
对初创企业来说,这种新型的基础设施非常实用,因为他们不再需要在基础设施上花一分钱,并能够根据应用访问者的数量来调整支出。
微服务具有较高的成本效率、巨大的可扩展性潜力和枢纽友好性,可以从根本上改变 IT 团队消耗资源的方式。未来,将会有更多初创企业,借助 Serverless 带来的巨大优势做出功能更强、创新更多、更强大的项目。
]]>Previously published at:https://blog.techmagic.co/benefits-of-serverless-for-startups/ 作者:Mike Butusov 译者:OrangeJ

来源 | Serverless 公众号;作者 | Ben Kehoe ;译者 | donghui
函数不是重点
如果你因为喜欢 Lambda 而选择 Serverless,你这样做的原因是错误的。如果你选择 Serverless,是因为你喜欢 FaaS,你这样做的原因也是错误的。函数不是重点。
当然,我喜欢 Lambda ——但这不是我提倡 Serverless 的原因。
不要误解我,函数很好。它们让你透明地伸缩,你不必管理运行时,而且它们天然地适合事件驱动的架构。这些都是非常有用的特性。
但是函数最终应该成为整个解决方案的一小部分。你应该使用包含业务逻辑的函数作为托管服务之间的粘合剂,这些托管服务提供了构成应用程序的大部分繁重工作。
托管服务不是重点
我们很幸运,云提供商能够为应用程序的许多不同部分提供如此广泛的托管服务。数据库、身份和访问管理(真高兴我不用自己拥有它!)、分析、机器学习、内容分发、消息队列等各种不同模式。
托管服务以较少的麻烦提供你所需的功能。你不必给他们运行的服务器打补丁。你不必确保自动缩放在没有大量空闲容量的情况下正确地提供所需的吞吐量。
托管服务显著降低了你的运维负担。托管服务很棒——但……它们不是重点。
运维不是重点
很高兴知道你可以应用更少的运维资源来保持应用程序的健康。尤其重要的是,你所需要的资源主要是根据你所提供的函数数量而不是流量来伸缩的。
减少运维、效率更高——但……这不是重点。
成本不是重点
好吧,有时候企业希望你做的只是降低成本——而这正是你所关心的。Serverless 会帮助你做到这一点。但总的来说,云计算账单并不是问题的重点。
你的云账单只是云应用程序总成本的一个组成部分。首先,是运维人员的薪水——如果你的运维人员资源更少的话,成本会更低。还有你的开发成本。
这里有很多成本优势——但……这些都不是重点。
代码不是重点
代码不仅不是重点,而且是一种责任。代码最多只能做你想做的事情。Bug 会削弱这一点。你只会因为编写更多的代码而失去重点。你拥有的代码越多,偏离你预期价值的机会就越多。理解这是一种文化转变。
技术一直以来都很困难。聪明的人通过技术创造价值。所以开发者开始相信聪明是与生俱来的,是好的。我们花了这么长时间来制造瑞士手表,以至于没有意识到石英卡西欧的出现,并指责这种演变缺乏优雅。
我们需要理解并解决业务问题,而不是将我们的聪明才智用于解决技术问题。当你必须编码时,你是在解决技术问题。
技术不是重点
我们这样做的原因,是为了达到某种商业目标。你的组织试图创造的业务价值就是重点。
现在,有时候,你卖的是技术。但即使你的产品是技术,那也可能不是你销售的产品的价值所在。
有句老话说,人们买的不是钻子,而是洞。当你需要在墙上钻个洞时,你不会在乎钻得有多漂亮,你只在乎钻得有多好就能钻出你需要的洞。
在 iRobot,我们不卖机器人。我们甚至都不卖吸尘器。我们卖清洁房屋。Roomba 让你有时间回到你的日常生活中去关注对你来说重要的事情。所以,如果技术不是重点,我们在这里是为了什么?
重点是专注
Serverless 是一种专注于业务价值的方法。
函数如何帮助你交付价值?它们让你将重点放在编写业务逻辑上,而不是为业务逻辑编写支持的基础设施。
托管服务让你可以专注于编写函数。较少的运维资源可以腾出人力和资金,为客户创造新的价值。
可观察性为你提供了处理 MTBF 和 MTTR 的工具,这两种工具都可以度量你的客户获得价值的频率。在云计算上花更少的钱意味着你可以更直接地把钱花在支持创造价值上。
专注是选择 Serverless 的原因
你应该选择 Serverless,因为你想专注于创造价值——在你的公司,你努力应用技术来创造商业价值。
回到成本上,Lyft 的 AWS 账单,每年 1 亿美元,最近已经成为新闻。许多人插话说他们可以做得更便宜——他们不能,但这不是重点。
如果 Lyft 切换到 Lambda 并尽可能地托管服务,他们的账单会更低吗?可能。但当他们花时间重新架构时,这会有什么用呢?他们会失重点。
公司正处于发展比成本控制更重要的阶段。最终,这种情况可能会改变。上市公司对股东负责,因此降低成本可以为他们带来价值。但是对于现在的 Lyft 来说,为他们的客户提供价值意味着执行他们当前的应用程序和流程。他们正在做一个 Serverless 的选择。
我要告诉你的是,Serverless 从未涉及到我们称之为 Serverless 的技术。那么我们所谓的 Serverless 技术和它有什么关系呢?
Serverless 是专注业务价值的结果
技术是你如何交付价值的结果。开发团队和运维团队传统上是分开的,因为他们有不同的专注点。但我们看到这一趋势正在改变。
传统的模式把重点放在技术上——开发技术 vs 运维技术。但是我们看到人们意识到重点应该放在价值上——交付的功能,包括如何构建和运行。
当我们采用这种关注业务价值的概念,并运行其逻辑结论时,我们得到 Serverless 。
当你想要专注于交付价值时,你想要编写函数。当函数需要状态时,需要一个数据库。要从别人那里获得它,你可以使用 DBaaS——你可以根据它让你专注的程度来在你的选项之间进行选择。
在选择托管服务时,其中一些甚至可能是面向用户的。如果你可以使用社交账户登录而不是拥有自己的账户,那你就少了一件需要管理的事情,也少了你拥有的对用户体验的筹码。
现在,对于你所外包的一切,你仍然有责任。你的用户并不关心他们的糟糕体验是由第三方造成的,这仍然是你的问题。你需要将中断留给你的用户,同时接受你不能完全控制你在那里的命运。这是一个不舒服的地方,但它是值得的。
在这些事情上你不能赢得分数——但你可以失去。这意味着你需要知道“坏”是什么样子。这就要求你对外包的产品和技术有足够的了解,以确保你为用户提供了足够的质量。
请注意,在一个重点领域有深入的专业知识,而在相邻领域有广泛但薄弱的知识,这与 T 型技能的概念非常相似——适用于组织和团队。
Serverless 是一种特质
Serverless 是公司的一个特质。如果一个公司决定它不应该拥有不是实现其商业价值的核心技术,那么它就是 Serverless 的。很少有公司是完全 Serverless 的。但是在公司内部,仍然可以有 Serverless 的部分。
如果你的团队决定只关注它所传递的价值,并将任何超出这些价值的东西委托给另一个团队,或者理想情况下委托给外部——那么你的团队就会变得 Serverless 。你不能总是选择使用外部技术——这很好,你仍然可以在有限的条件下做出最好的选择。
在一个足够大的组织中,它就不再重要了。当 Amazon.com 使用 Lambda 时,它是完全 Serverless 的,尽管它在某种意义上是 on-prem 的。但如果只有你一个人呢?
如果你对 Serverless 感到兴奋,但在公司里感到完全孤独怎么办?如果你与实际的商业价值相去甚远——如果你为一个服务于创建面向用户内容的团队的团队打补丁,那该怎么办?我想说服你,你今天可以在任何情况下变得 Serverless 。
Serverless 是方向,而不是终点
我曾经把 Serverless 技术作为一个光谱来讨论,因为我知道没有一条清晰的线来区分 Serverless 技术和非 Serverless 技术。我的意思是,几乎没有一条明亮的线来分隔任何给定的分组,所以我在这个假设中我是很安全的。
我讲过像 Kinesis 这样需要管理碎片的东西,它是 Serverless 的,但比 SQS 少一些 Serverless 。你不必使用 RDS 修补实例,但需要选择实例类型和数量。这些技术都是不同程度的 Serverless 。
但最近我开始意识到将 Serverless 描述为光谱的一个问题是,它并不意味着移动。仅仅因为你使用的是某种指定为 Serverless 的产品,并不意味着你应该感到自己已经获得了 Serverless -继续使用它并认为你已经选中了 Serverless 复选框是可以接受的。
爬上 Serverless 阶梯
我开始把 Serverless 想象成一个梯子。你正在攀登某种必杀技,在那里你可以在没有开销的情况下交付纯业务价值。但阶梯上的每个梯级都是有效的 Serverless 步骤。
如果你从 on-prem 移动到公共云,那是阶梯。如果你从虚拟机迁移到容器,那简直就是天梯。如果你从没有容器编排或自定义编排迁移到 Kubernetes,这是阶梯。如果你从长期运行的服务器转移到自托管的 FaaS,那将是天梯。但总有一个梯级在你之上,你应该始终保持攀登。
"阶梯"没有传达的一件事是它不是线性的。从虚拟机迁移到容器再到 Kubernetes 都是在梯级上的阶梯,但是将虚拟机从本地迁移到云也是如此。在这些情况下,通常没有一个明确的“更好”。
我想到了通往山顶的许多路径的比喻,但我喜欢梯子的一点是它可以是无限的。没有最终状态。我喜欢 Lambda,但我一直在寻找更好的方式来交付代码,使我更关注价值。
Serverless 是一种思想状态
Serverless 是关于你如何决策的问题,而不是你的选择。每个决定都是有约束的。但是,如果你知道正确的方向,即使你不能以这种方式直接移动,也可以选择最紧密结合的选择,然后再向上移动另一个梯级。那么,你如何采用这种思维方式?你如何做出 Serverless 选择?
配置是你的朋友
我认为许多开发人员看不起配置,认为它“不是真正的编程”。现在有一种对编程的盲目崇拜。我们被告知“软件正在吞噬世界”,而我们却不准确地将其翻译成“编码正在吞噬世界”。
我们已经相信,开发人员是组织中唯一重要的人,而我们的生产力意识是唯一重要的事情。我们想在区域中感受到,这就是编码所提供的。这方面的任何障碍都对企业不利。我们对进入该区域是否真的比替代路线更快,更好地创造价值没有任何感觉。
切记:数天的编程可以节省数小时的配置
约束是好的。删除选项可以帮助你保持专注。显然,并不是所有的约束都是好的——但是一般来说,做一般事情的能力是以花费更长的时间来做一件特定的事情为代价的。护栏可能会磨损,但你会比一直盯着护栏边缘跑得快。
这样,Serverless 是关于极简主义的。消除干扰。Marie Kondo 现在很大,并且同样的建议也适用。查找你的堆栈中不会产生价值的组件。
害怕可能发生的巨大事件
可能性蕴含着隐藏的复杂性。对于任何技术,我的主要评估指标之一是它有多少能力超出手头的任务。当有很多额外的空间时,就会处理和学习不必要的复杂性。
人们把 Kubernetes 吹捧为一个单一的工具来完成每一个云需求——它确实可以!但如果一切皆有可能,一切皆有可能。对于一个给定的任务,Kubernetes 可能会出错,因为你没有考虑它在与该任务无关的情况下的行为方式。
另一方面,当你考虑 Serverless 的服务时,你可能必须在主要提供商提供的 80%的解决方案或第三方提供商提供的更适合你需求的服务之间做出选择。但是该新提供商的运维需求是什么?身份验证是什么样的?这些是隐藏的复杂性,你需要引入这些特性,你需要权衡这些特性差异。
接受不拥有自己命运的不适感
当你使用托管服务时,提供者中断会带来压力。你无法解决他们的问题。这是无法回避的——这总是让人感觉很糟糕。你可能会想,“如果我运行自己的 Kafka 集群而不是使用 Kinesis,我就可以找到问题并解决它”。这可能是真的,但你应该记住两件事:
- 那会分散人们对创造商业价值的注意力。
- 你几乎肯定会在运行它方面做得更差。你会遇到更多更糟糕的事情。服务提供商的人生目标就是擅长于此——他们有规模经济,而你没有。
超越“我总是可以自己建立它”的态度可能很难。Jared Short 最近为选择技术提供了一套出色的指导方针。 _ 这些天来我对无服务器的思考是按考虑顺序进行的。–如果平台拥有,请使用–如果市场拥有,请购买–如果你可以重新考虑需求,请执行–如果必须构建,请拥有。——@ShortJared
因此,如果你使用的是云平台,请尽可能留在生态系统中。这样,你就可以从方程式中消除很多可能性。但是,如果无法在平台上获得所需的东西,请从其他地方购买。
如果你不能完全购买所需的东西,你是否可以重新考虑自己在做什么以适应你可以购买的东西?这一点真的很重要。它到达了上市时间的核心。
如果你有一些你认为有价值的东西,你会想要尽快运送。但更快地运送一些东西,总比精确地构建好,因为你还不知道这是不是正确的东西。
等待构建出正确的东西不仅会花费更长的时间,而且后续的迭代也会更慢——并且对其进行维护将占用你将来可用于运送更多东西的资源。即使在该技术不是 Serverless 的情况下,这也适用:始终询问对你的要求的调整是否可以实现更快,更好或更专注的价值交付。
但是,最后,如果必须构建它,请拥有它。寻找一种使其与众不同的方法。现在,这并不意味着你已经构建的所有内容都应该变成差异化的。在完美的世界里只看你买不到的东西。想象一下完全 Serverless 的绿地实现会是什么样子,并找到需要在那里构建的内容。
找到你的业务价值部分
因此,从根本上讲,你希望找到你的业务价值部分。你所服务的技术工作是什么?也许你与面向用户的产品相去甚远。你可能只贡献了一小部分。但它在那里,你可以找到它-并专注于这一价值。
从你为组织中其他人提供的直接价值开始,并专注于此。然后开始追踪价值链。确保所有决策都围绕你所创造的价值。做出 Serverless 的选择。
雇用可以自动完成工作的人员,然后继续为他们提供工作。——@jessfraz
我喜欢 Jessie Frazelle 的话。你可以把它转过来:自动化完成工作,继续做有要求的工作。
请记住,你不是工具。对于你要创建的任何价值,请自动化创建。如果你管理构建服务器,请找到使它们成为自助服务的方法,因此你交付的不是构建本身,而是构建工具,以便团队可以自己交付构建。
总结:Serverless 是一种思想状态
重点不是函数,托管服务,运维,成本,代码或技术。重点是专注——这就是选择 Serverless 的原因。
Serverless 是专注业务价值的结果。这是一个特质。这是方向,而不是终点。爬上永无止境的 Serverless 阶梯。
配置是你的朋友。数天的编程时间可以节省数小时的配置时间。害怕可能发生的巨大事件。接受不拥有自己命运的不适感。
找到你的业务价值部分,并实现 Serverless 状态。
]]>原文链接:https://read.acloud.guru/serverless-is-a-state-of-mind-717ef2088b42
 来源 | Serverless 公众号 编译 | OrangeJ 作者 | Mariliis Retter
来源 | Serverless 公众号 编译 | OrangeJ 作者 | Mariliis Retter “Serverless 能取代微服务吗?” 这是知乎上 Serverless 分类的高热话题。

有人说微服务与 Serverless 是相背离的,虽然我们可以基于 Serverless 后端来构建微服务,但在微服务和 Serverless 之间并不存在直接的路径。也有人说,因为 Serverless 内含的 Function 可以视为更小的、原子化的服务,天然地契合微服务的一些理念,所以 Serverless 与微服务是天作之合。马上就要 2021 年了,Serverless 是否终将取代微服务?从微服务到 Serverless 需要经过怎样的路径?本文将对 Serverless 与微服务在优势劣势上进行深度对比。
从概念上讲,微服务完全符合 Serverless 功能结构,微服务可以轻松实现不同服务的部署和运行时隔离。在存储方面,像 DynamoDB 这样的服务可以让每个微服务拥有独立的数据库,并独立地进行扩展。在我们深入探讨细节之前,先别急着“站队”,不妨先基于你团队的实际情况,真实的去思考是否适合使用微服务,千万不要因为 "这是趋势 "而去选择它。
微服务在 Serverless 环境下的优势
可选择的可扩展性和并发性
Serverless 让管理并发性和可扩展性变得容易。在微服务架构中,我们最大限度地利用了这一点。每一个微服务都可以根据自己的需求对并发性 /可扩展性进行设置。从不同的角度来看这非常有价值:比如减轻 DDoS 攻击可能性,降低云账单失控的财务风险,更好地分配资源......等等。
细粒度的资源分配
因为可扩展性和并发性可以自主选择,用户可以细粒度控制资源分配的优先级。在 Lambda functions 中,每个微服务都可以根据其需求,拥有不同级别的内存分配。比如,面向客户的服务可以拥有更高的内存分配,因为这将有助于加快执行时间;而对于延迟不敏感的内部服务,就可以用优化的内存设置来进行部署。
这一特性同样适用于存储机制。比如 DynamoDB 或 Aurora Serverless 数据库就可以根据所服务的特定(微)服务的需求,拥有不同级别的容量分配。
松耦合
这是微服务的一般属性,并不是 Serverless 的独有属性,这个特性让系统中不同功能的组件更容易解耦。
支持多运行环境
Serverless 功能的配置、部署和执行的简易性,为基于多个运行时的系统提供了可能性。
虽然 Node.js ( Javascript 运行时)是后端 Web 应用最流行的技术之一,但它不可能成为每一项任务的最佳工具。对于数据密集型任务、预测分析和任何类型的机器学习,你可能选择 Python 作为编程语言;像 SageMaker 这样的专用平台更适合大项目。
有了 Serverless 基础架构,你无需在操作方面花费额外的精力就可以直接为常规后端 API 选择 Node.js ,为数据密集型工作选择 Python 。显然,这可能会给你的团队带来代码维护和团队管理的额外工作。
开发团队的独立性
不同的开发者或团队可以在各自的微服务上工作、修复 bug 、扩展功能等,做到互不干扰。比如 AWS SAM 、Serverless 框架等工具让开发者在操作层面更加独立。而 AWS CDK 构架的出现,可以在不损害高质量和运维标准的前提下,让开发团队拥有更高的独立性。
微服务在 Serverless 中的劣势
难以监控和调试
在 Serverless 带来的众多挑战中,监控和调试可能是最有难度的。因为计算和存储系统分散在许多不同的功能和数据库中,更不用说队列、缓存等其他服务了,这些问题都是由微服务本身引起的。不过,目前已经有专业的平台可以解决所有这些问题。那么,专业的开发团队是否要引入这些专业平台也应该基于成本进行考量。
可能经历更多冷启动
当 FaaS 平台(如 Lambda )需要启动一个新的虚拟机来运行函数代码时,就会发生冷启动。如果你的函数 Workload 对延迟敏感,就很可能会遇到问题。因为冷启动会在总启动时间中增加几百毫秒到几秒的时间,当一个请求完成后,FaaS 平台通常会让 microVM 空闲一段时间,等待下一个请求,然后在 10-60 分钟后关闭(是的,变化很大)。结果是:你的功能执行的越频繁,microVM 就越有可能为传入的请求而启动并运行(避免冷启动)。
当我们将应用分散在数百个或数千个微服务中时,我们可能在每个服务中分散调用时间,导致每个函数的调用频率降低。注意 "可能会分散调用"。根据业务逻辑和你的系统行为方式,这种负面影响可能很小,或者可以忽略不计。
其他缺点
微服务概念本身还存在其他固有的缺点。这些并不是与 Serverless 有内在联系的。尽管如此,每一个采用这种类型架构的团队都应该谨慎,以降低其潜在的风险和成本。
- 确定服务边界并非易事,可能会招致架构问题。
- 更广泛的攻击面
- 服务编排费用问题
- 同步计算和存储(在需要的时候)是不容易做到高性能和可扩展
微服务在 Serverless 中的挑战和最佳实践
Serverless 中微服务应该多大?
人们在理解 Serverless 时,"Function as a Services ( FaaS ) " 的概念很容易与编程语言中的函数语句相混淆。目前,我们正在处在一个没有办法划出完美界限的时期,但经验表明,使用非常小的 Serverless 函数并不是一个好主意。
当你决定将一个(微)服务分拆成独立的功能时,你就将不得不面对 Serverless 难题。因此,在此提醒,只要有可能,将相关的逻辑保持在一个函数中会好很多。
当然,决策过程也应该考虑拥有一个独立的微服务的优势
你可以这样设想:"如果我把这个微服务分拆出来......
- 它能让不同的团队独立工作吗?
- 能否从细粒度的资源分配或选择性的扩展能力中获益?
如果不能,你应该考虑将这个服务与另一个需要类似资源、上下文关联并执行相关 Workload 的服务捆绑在一起。
松耦合的架构
通过组成 Serverless 函数来协调微服务的方法有很多。
当需要同步通信时,可以直接调用(即 AWS Lambda RequestResponse 调用方法),但这会导致高度耦合的架构。更好的选择是使用 Lambda Layers 或 HTTP API,这样可以让以后的修改或迁移服务对客户端不构成影响。
对于接受异步通信模型,我们有几种选择,如队列( SQS )、主题通知( SNS )、Event Bridge 或者 DynamoDB Streams 。
跨组件隔离
理想情况下,微服务不应向使用者暴露细节。像 Lambda 这样的 Serverless 平台会提供一个 API 来隔离函数。但这本身就是一种实现细节的泄露,理想情况下,我们会在函数之上添加一个不可知的 HTTP API 层,使其真正隔离。
使用并发限制和节流策略的重要性
为了减轻 DDoS 攻击,在使用 AWS API Gateway 等服务时,一定要为每个面向公众的终端设置单独的并发限制和节流策略。这类服务一般在云平台中会为整个区域设置全局并发配额。如果你没有基于端点的限制,攻击者只需要将一个单一的端点作为攻击目标,就可以耗尽你的配额,并让你在该区域的整个系统瘫痪。
]]>翻译:OrangeJ 原文链接:https://dzone.com/articles/microservices-and-serverless-winning-strategies-an
 作者 | 计缘 来源 | Serverless 公众号
作者 | 计缘 来源 | Serverless 公众号 说起 Serverless 这个词,我想大家应该都不陌生,那么 Serverless 这个词到底是什么意思? Serverless 到底能解决什么问题?可能很多朋友还没有深刻的体会和体感,这篇文章我就和大家一起聊聊 Serverless 。
什么是 Serverless
我们先将 Serverless 这个词拆开来看。Server,大家都知道是服务器的意思,说明 Serverless 解决的问题范围在服务端。Less,大家肯定也知道它的意思是较少的。那么 Serverless 连起来,再稍加修饰,那就是较少的关心服务器的意思。
Serverfull 时代
我们都知道,在研发侧都会有研发人员和运维人员两个角色,要开发一个新系统的时候,研发人员根据产品经理的 PRD 开始写代码开发功能,当功能开发、测试完之后,要发布到服务器。这个时候开始由运维人员规划服务器规格、服务器数量、每个服务部署的节点数量、服务器的扩缩容策略和机制、发布服务过程、服务优雅上下线机制等等。这种模式是研发和运维隔离,服务端运维都由专门的运维人员处理,而且很多时候是靠纯人力处理,也就是 Serverfull 时代。
DevOps 时代
互联网公司里最辛苦的是谁?我相信大多数都是运维同学。白天做各种网络规划、环境规划、数据库规划等等,晚上熬夜发布新版本,做上线保障,而且很多事情是重复性的工作。然后慢慢就有了赋能研发这样的声音,运维同学帮助研发同学做一套运维控制台,可以让研发同学在运维控制台上自行发布服务、查看日志、查询数据。这样一来,运维同学主要维护这套运维控制台系统,并且不断完善功能,轻松了不少。这就是研发兼运维的 DevOps 时代。
Serverless 时代
渐渐的,研发同学和运维同学的关注点都在运维控制台了,运维控制台的功能越来越强大,比如根据运维侧的需求增加了自动弹性扩缩、性能监控的功能,根据研发侧的需求增加了自动化发布的流水线功能。因为有了这套系统,代码质量检测、单元测试、打包编译、部署、集成测试、灰度发布、弹性扩缩、性能监控、应用防护这一系列服务端的工作基本上不需要人工参与处理了。这就是 NoOps,Serverless 时代。
Serverless 在编程教育中的应用
2020 年注定是不平凡的一年,疫情期间,多少家企业如割韭菜般倒下,又有多少家企业如雨后春笋般茁壮成长,比如在线教育行业。
没错,在线教育行业是这次疫情的最大受益者,在在线教育在这个行业里,有一个细分市场是在线编程教育,尤其是少儿编程教育和面向非专业人士的编程教育,比如编程猫、斑马 AI 、小象学院等。这些企业的在线编程系统都有一些共同的特点和诉求:
屏幕一侧写代码,执行代码,另一侧显示运行结果。 根据题目编写的代码都是代码块,每道题的代码量不会很大。 运行代码的速度要快。 支持多种编程语言。 能支撑不可预计的流量洪峰冲击。
例如小象学院的编程课界面:
结合上述这些特点和诉求,不难看出,构建这样一套在线编程系统的核心在于有一个支持多种编程语言的、健壮高可用的代码运行环境。
那么我们先来看看传统的实现架构:
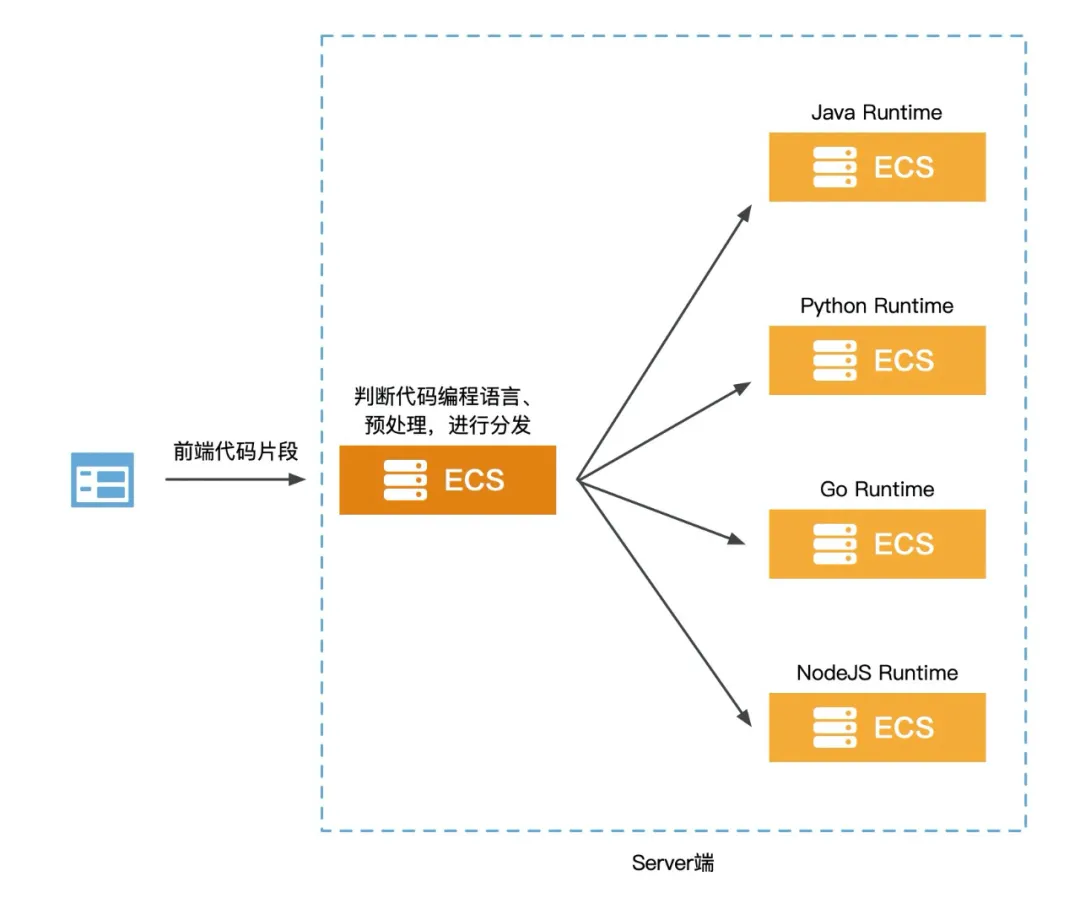
从 High Level 的架构来看,前端只需要将代码片段和编程语言的标识传给 Server 端即可,然后等待响应展示结果。所以整个 Server 端要负责对不同语言的代码进行分类、预处理然后传给不同编程语言的 Runtime 。这种架构有以下几个比较核心的问题。
工作量大,灵活性差
首先是研发和运维工作量的问题,当市场有新的需求,或者洞察到新业务模式时需要增加编程语言,此时研发侧需要增加编程代码分类和预处理的逻辑,另外需要构建对应编程语言的 Runtime 。在运维侧需要规划支撑新语言的服务器规格以及数量,还有整体的 CICD 流程等。所以支持新的编程语言这个需求要落地,需要研发、运维花费不少的时间来实现,再加上黑 /白盒测试和 CICD 流程测试的时间,对市场需求的支撑不能快速的响应,灵活性相对较差。
高可用自己兜底
其次整个在线编程系统的稳定性是重中之重。所以所有 Server 端服务的高可用架构都需要自己搭建,用以保证流量高峰场景和稳态场景下的系统稳定。高可用一方面是代码逻辑编写的是否优雅和完善,另一方面是部署服务的集群,无论是 ECS 集群还是 K8s 集群,都需要研发和运维同学一起规划,那么对于对编程语言进行分类和预处理的服务来讲,尚能给定一个节点数,但是对于不同语言的 Runtime 服务来讲,市场需求随时会变,所以不好具体衡量每个服务的节点数。另外很重要的一点是所以服务的扩容,缩容机制都需要运维同学来实时手动操作,即便是通过脚本实现自动化,那么 ECS 弹起的速度也是远达不到业务预期的。
成本控制粒度粗
再次是整个 IaaS 资源的成本控制,我们都知道这种在线教育是有明显的流量潮汐的,比如上午 10 点到 12 点,下午 3 点到 5 点,晚上 8 点到 10 点这几个时段是流量比较大的时候,其他时间端流量比较小,而且夜晚更是没什么流量。所以在这种情况下,传统的部署架构无法做到 IaaS 资源和流量的贴合。举个例子,加入为了应对流量高峰时期,需要 20 台 ECS 搭建集群来承载流量冲击,此时每台 ECS 的资源使用率可能在 70% 以上,利用率较高,但是在流量小的时候和夜晚,每台 ECS 的资源使用率可能就是百分之十几甚至更低,这就是一种资源浪费。
Serverless 架构
那么我们来看看如何使用 Serverless 架构来实现同样的功能,并且解决上述几个问题。在选择 Serverless 产品时,在国内自然而然优先想到的就是阿里云的产品。阿里云有两款 Serverless 架构的产品 Serverless 应用引擎和函数计算,这里我们使用函数计算来实现编程教育的场景。
函数计算( Function Compute )是事件驱动的全托管计算服务,简称 FC 。使用函数计算,我们无需采购与管理服务器等基础设施,只需编写并上传代码。函数计算为您准备好计算资源,弹性地、可靠地运行任务,并提供日志查询、性能监控和报警等功能。
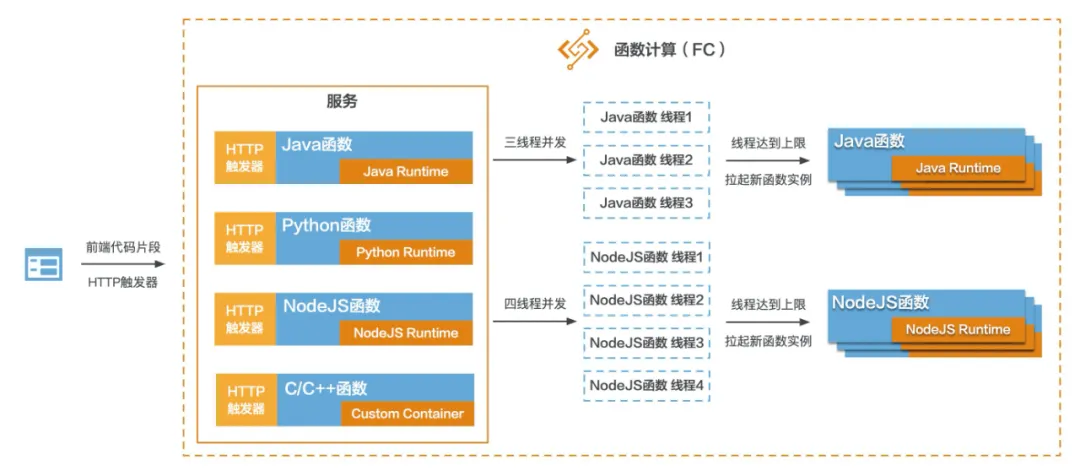
这里不对 FC 的含义做过多赘述,只举一个例子。FC 中有两个概念,一个是服务,一个是函数。一个服务包含多个函数:
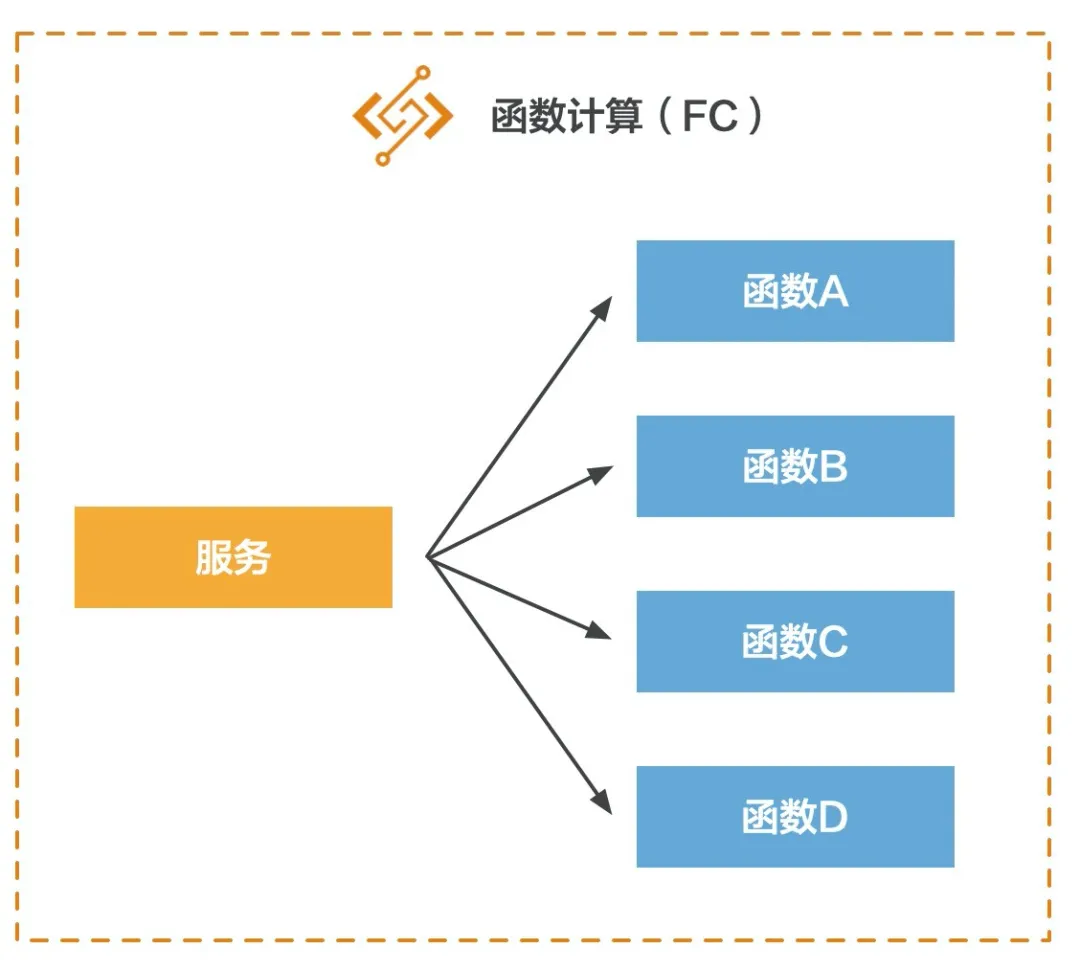
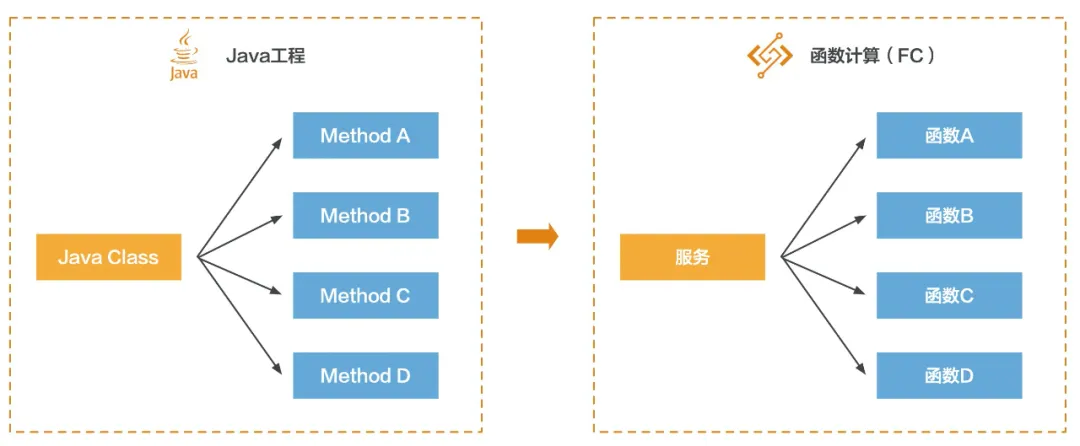
这里拿 Java 微服务架构来对应,可以理解为,FC 中的服务是 Java 中的一个类,FC 中的函数是 Java 类中的一个方法:
但是 Java 类中的方法固然只能是 Java 代码,而 FC 中的函数可以设置不同语言的 Runtime 来运行不同的编程语言:

这个结构理解清楚之后,我们来看看如何调用 FC 的函数,这里会引出一个触发器的概念。我们最常使用的 HTTP 请求协议其实就是一种类型的触发器,在 FC 里称为 HTTP 触发器,除了 HTTP 触发器以外,还提供了 OSS (对象存储)触发器、SLS (日志服务)触发器、定时触发器、MNS 触发器、CDN 触发器等。
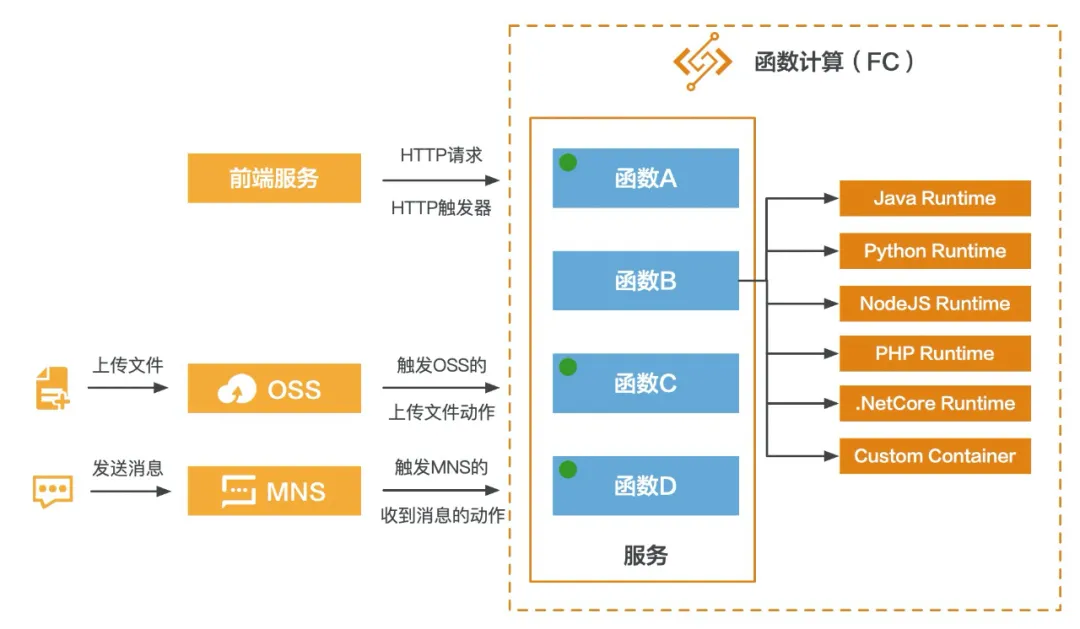
从上图可以大概理解,我们可以通过多种途径调用 FC 中的函数。举例两个场景,比如每当我在指定的 OSS Bucket 的某个目录下上传一张图片后,就可以触发 FC 中的函数,函数的逻辑是将刚刚上传的图片下载下来,然后对图片做处理,然后再上传回 OSS 。再比如向 MNS 的某个队列发送一条消息,然后触发 FC 中的函数来处理针对这条消息的逻辑。
最后我们再来看看 FC 的高可用。每一个函数在运行代码时底层肯定还是 IaaS 资源,但我们只需要给每个函数设置运行代码时需要的内存数即可,最小 128M,最大 3G,对使用者而言,不需要考虑多少核数,也不需要知道代码运行在什么样的服务器上,不需要关心启动了多少个函数实例,也不需要关心弹性扩缩的问题等,这些都由 FC 来处理。
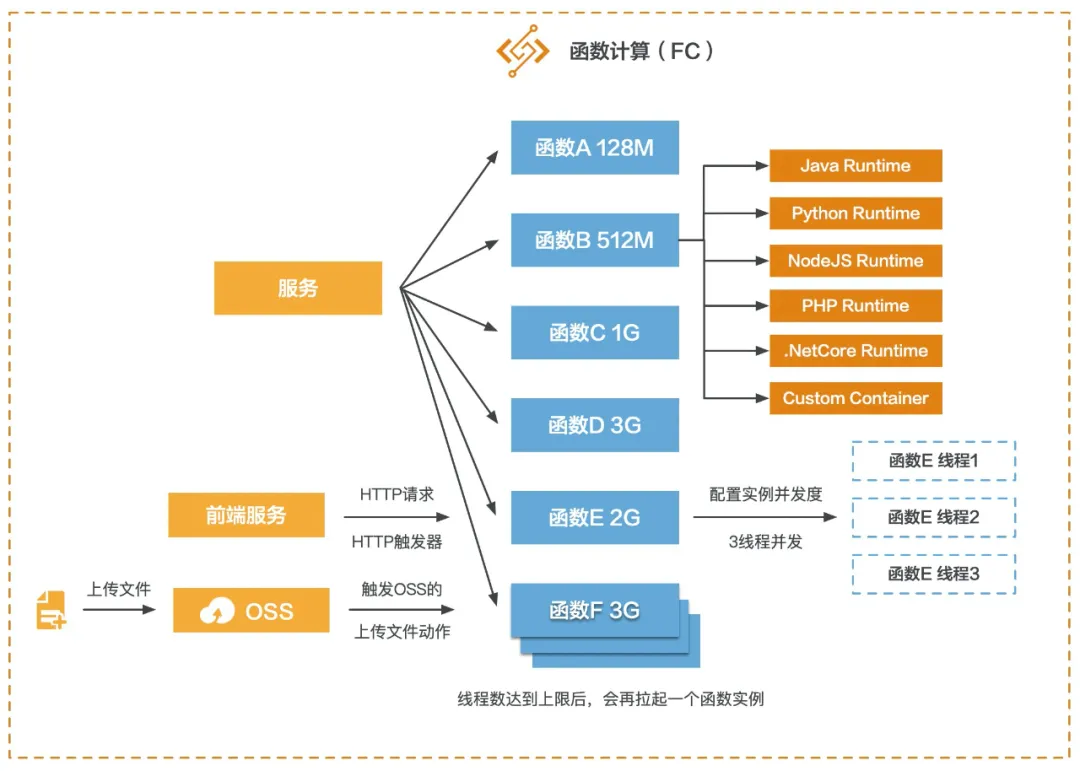
从上图可以看到,高可用有两种策略:
给函数设置并发实例数,假如设置为 3,那么有三个请求进来时,该函数只启一个实例,但是会启三个线程来运行逻辑。
线程数达到上限后,会再拉起一个函数实例。
大家看到这里,可能已经大概对基于 FC 实现在线编程教育系统的架构有了一个大概的轮廓。
上图是基于 FC 实现的在线编程教育系统的架构图,在这个架构下来看看上述那三个核心问题怎么解:
-
工作量和灵活性:我们只需要关注在如何执行代码的业务逻辑上,如果要加新语言,只需要创建一个对应语言 Runtime 的 FC 函数即可。
-
高可用:多线程运行业务逻辑和多实例运行业务逻辑两层高可用保障,并且函数实例的扩缩完全都是 FC 自动处理,不需要研发和运维同学做任何配置。
-
成本优化:当没有请求的时候,函数实例是不会被拉起的,此时也不会计费,所以在流量低谷期或者夜间时,整个 FC 的成本消耗是非常低的。可以做到函数实例个数、计费粒度和流量完美的贴合。
Python 编程语言示例
下面以运行 Python 代码为例来看看如何用 FC 实现 Python 在线编程 Demo 。
创建服务和函数
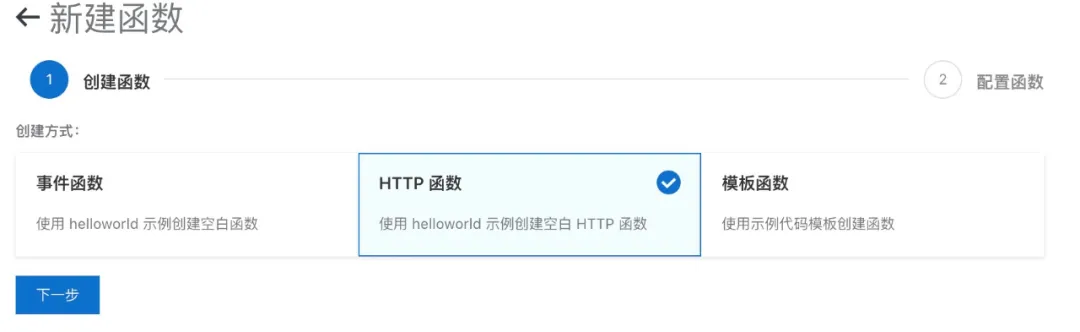
打开函数计算( FC )控制台,选择对应的 Region,选择左侧服务 /函数,然后新建服务:https://fc.console.aliyun.com/fc/overview/cn-hangzhou
输出服务名称,创建服务。
进入新创建的服务,然后创建函数,选择 HTTP 函数,即可配置 HTTP 触发器的函数:
设置函数的各个参数:
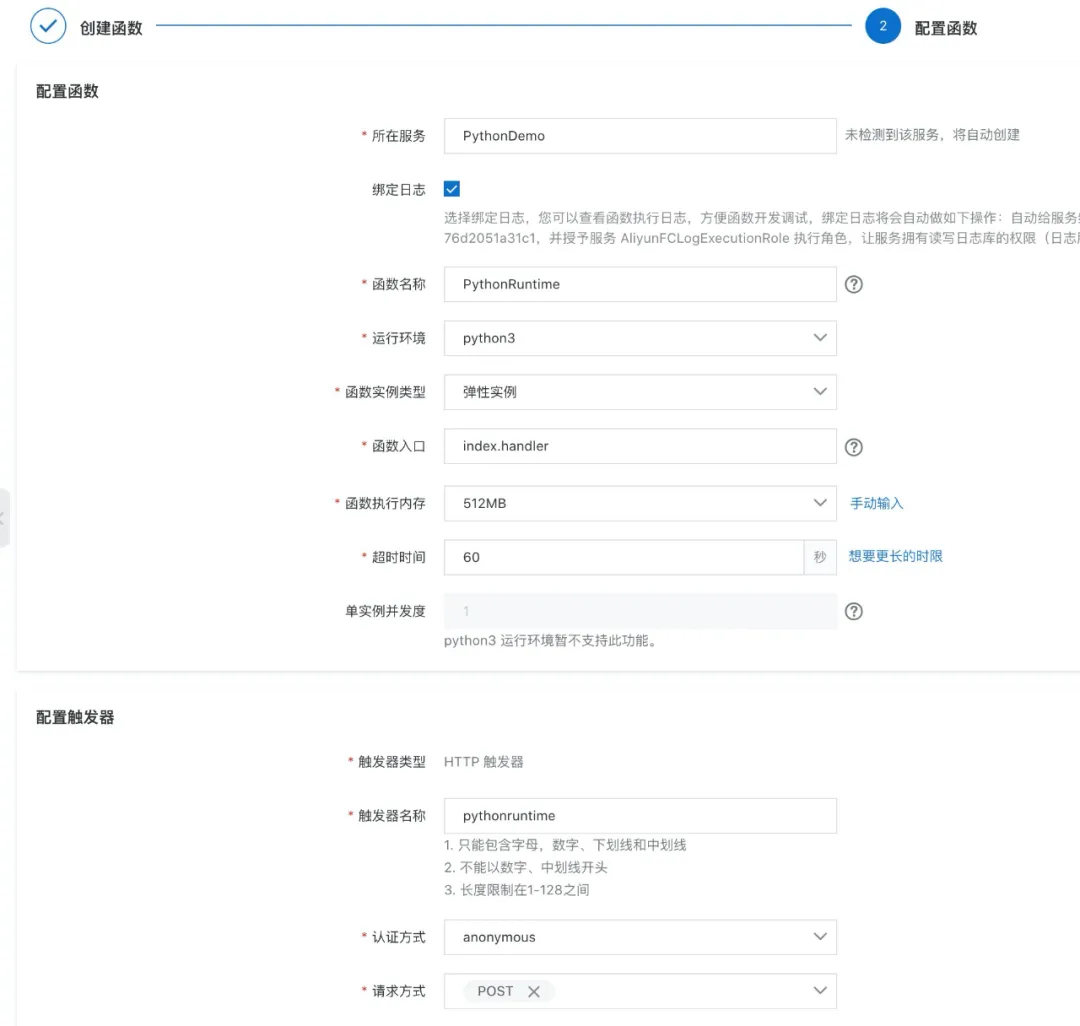
几个需要的注意的参数这里做以说明:
-
运行环境:这个很好理解,这里选择 P ython3
-
函数实例类型:这里有弹性实例和性能实例两种,前者最大支持 2C3G 规格的实例,后者支持更大的规格,最大到 8C16G 。
-
函数入口:详细参见文档 - HTTP 触发器认证方式:anonymous 为不需要鉴权,function 是需要鉴权的。https://help.aliyun.com/document_detail/74756.html?spm=a2c4g.11186623.6.572.195359cdselnzR
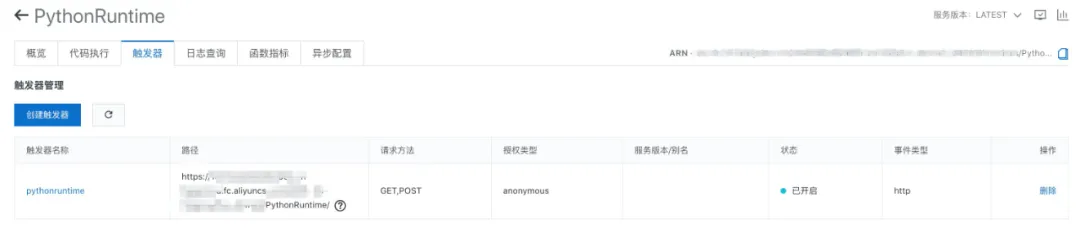
代码解析
函数创建好,进入函数,可以看到概述、代码执行、触发器、日志查询等页签,我们先看触发器,会看到这个函数自动创建了一个 HTTP 触发器,有调用该函数对应的 HTTP 路径:
然后我们选择代码执行,直接在线写入我们的代码:
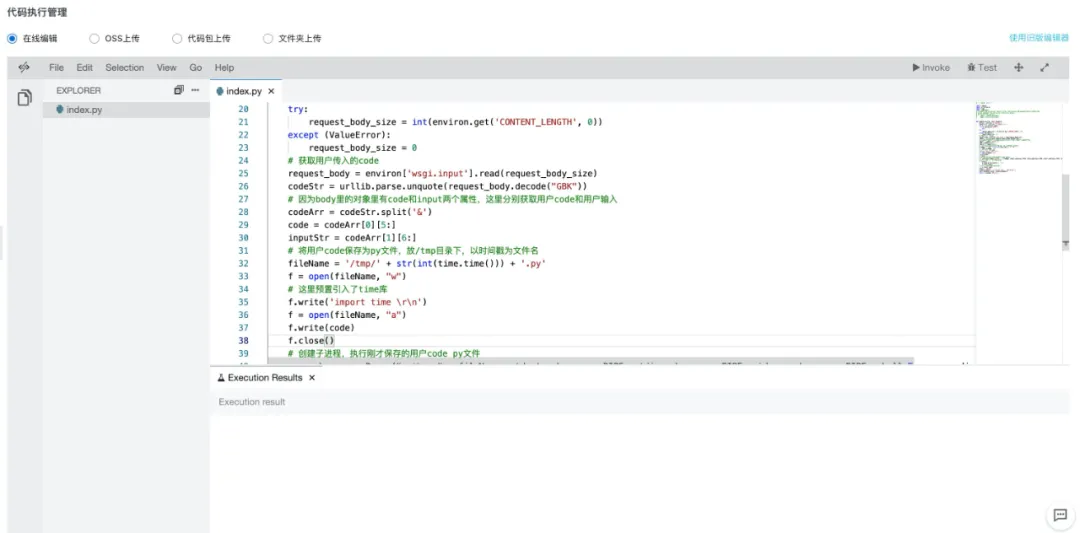
具体代码如下:
-- coding: utf-8 -- import logging import urllib.parse import time import subprocess def handler(environ, start_response): cOntext= environ['fc.context'] request_uri = environ['fc.request_uri'] for k, v in environ.items(): if k.startswith('HTTP_'): pass try: request_body_size = int(environ.get('CONTENT_LENGTH', 0)) except (ValueError): request_body_size = 0 # 获取用户传入的 code request_body = environ['wsgi.input'].read(request_body_size) codeStr = urllib.parse.unquote(request_body.decode("GBK")) # 因为 body 里的对象里有 code 和 input 两个属性,这里分别获取用户 code 和用户输入 codeArr = codeStr.split('&') code = codeArr[0][5:] inputStr = codeArr[1][6:] # 将用户 code 保存为 py 文件,放 /tmp 目录下,以时间戳为文件名 fileName = '/tmp/' + str(int(time.time())) + '.py' f = open(fileName, "w") # 这里预置引入了 time 库 f.write('import time \r\n') f = open(fileName, "a") f.write(code) f.close() # 创建子进程,执行刚才保存的用户 code py 文件 p = subprocess.Popen("python " + fileName, stdout=subprocess.PIPE, stdin=subprocess.PIPE, stderr=subprocess.PIPE, shell=True, encoding='utf-8') # 通过标准输入传入用户的 input 输入 if inputStr != '' : p.stdin.write(inputStr + "\n") p.stdin.flush() # 通过标准输出获取代码执行结果 r = p.stdout.read() status = '200 OK' response_headers = [('Content-type', 'text/plain')] start_response(status, response_headers) return [r.encode('UTF-8')] 整个代码思路如下:
- 从前端传入代码片段,格式是字符串。
- 在 FC 函数中获取到传入的代码字符串,截取 code 内容和 input 的内容。因为这里简单实现了 Python 中 input 交互的能力。
- 将代码保存为一个 Python 文件,以时间戳为文件名,保存在 FC 函数的 /tmp 目录下。(每个 FC 函数都有独立的 /tmp 目录,可以存放临时文件)
- 然后在文件中追加了引入 time 库的代码,应对 sleep 这种交互场景。
- 通过 subprocess 创建子进程,以 Shell 的方式通过 Python 命令执行保存在 /tmp 目录下的 Python 文件。如果有用户输入的信息,则通过标准输入输出写入子进程。
- 最后读取执行结果返回给前端。
前端代码
前端我使用 VUE 写了简单的页面,这里解析两个简单的方法:
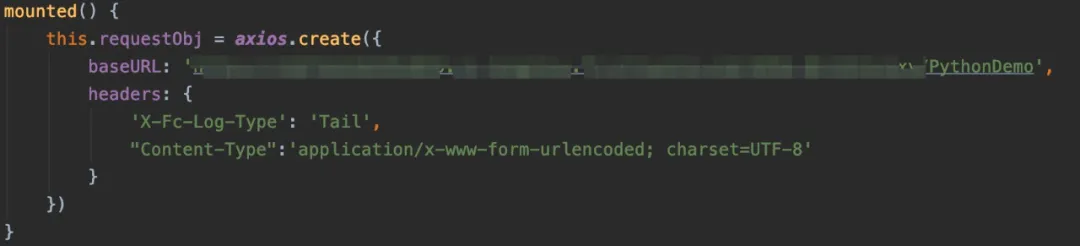
页面加载时初始化 HTTP 请求对象,调用的 HTTP 路径就是方才函数的 HTTP 触发器的路径。
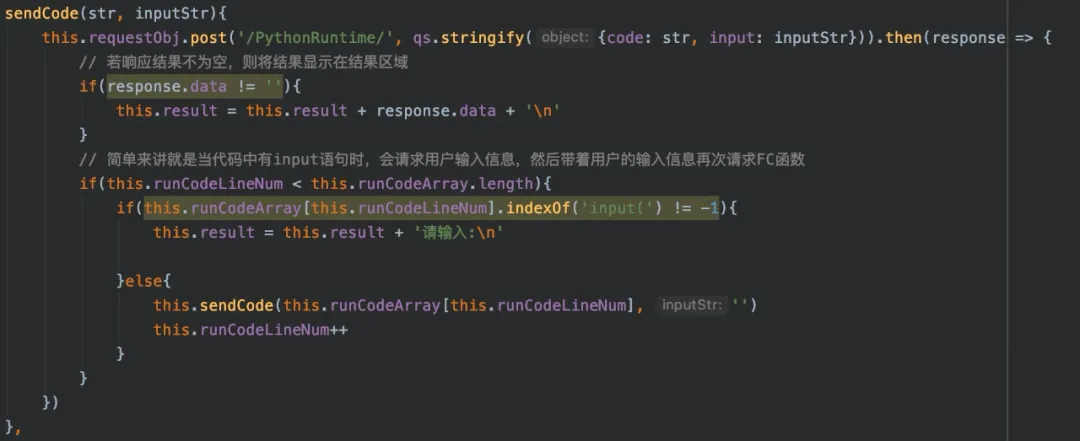
这个方法就是调用 FC 中的 PythonRuntime 函数,将前端页面的代码片段传给该函数。这里处理 input 交互的思路是,扫描整个代码片段,以包含 input 代码为标识将整个代码段分成多段。没有包含 input 代码的直接送给 FC 函数执行,包含 input 代码的,请求用户的输入,然后代码片段带着用户输入的信息一起送给 FC 函数执行。

演示如下:

结束语
这篇文章给大家介绍了 Serverless,阿里云的 Serverless 产品函数计算( FC )以及基于函数计算( FC )实现的在线编程系统的 Demo 。大家应该有所体感,基于函数计算( FC )实现在线编程系统时,研发同学只需要专注在如何执行由前端传入的代码即可,整个 Server 端的各个环节都不需要研发同学和运维同学去关心,基本体现了 Serverless 的精髓。
基于 Serverless 还有很多其他的应用场景,之后我会一一分享给大家,我们不见不散!
]]>
作者 | 许晓斌 阿里云高级技术专家
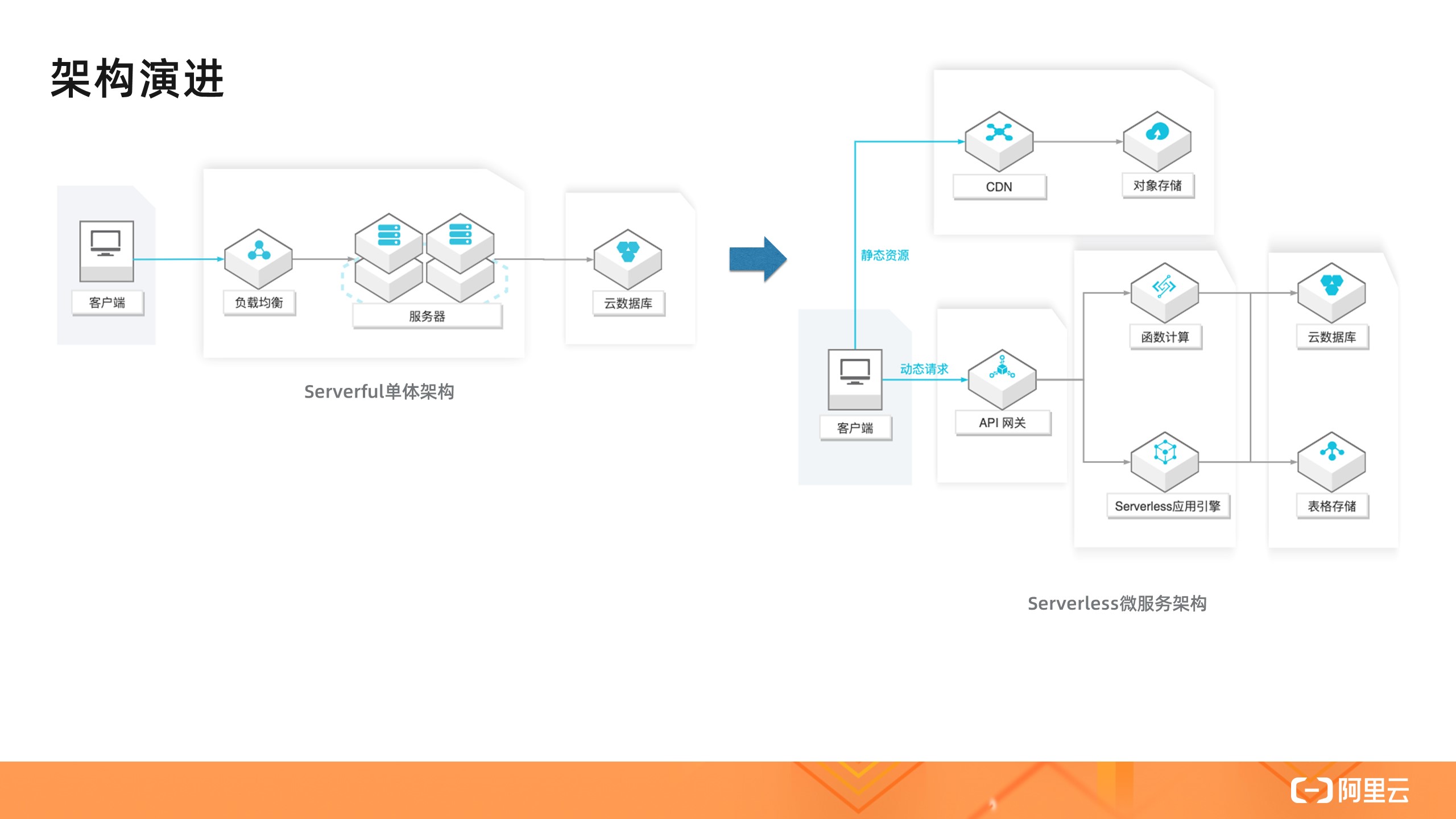
回顾架构的演进过程,我们不难发现,研发运维人员正在逐渐地把关注点从机器上移走,不再去管理机器。
其实我们都知道,虽然说是 Serverless,但 Server (服务器)是不可能真正消失的,Serverless 里这个 less 更确切地说,应该是开发者不用关心服务器的意思。这就好比现代编程语言 Java 和 Python,开发不用手工分配和释放内存,但内存依然在哪里,只不过交给垃圾收集器管理了。称一个能帮助你管理服务器的平台为 Serverless 平台,就好比称呼 Java 和 Python 为 Memoryless 语言一样。
但是,如果我们把目光放到今天这个云的时代,那么就不能狭义地把 Serverless 仅仅理解为不用关心服务器。云上的资源除了服务器所包含的基础计算、网络、存储资源之外,还包括各种类别的更上层的资源,例如数据库、缓存、消息等。
Serverless 的愿景
2019 年 2 月,UC 伯克利大学发表了一篇标题为《 Cloud Programming Simplified: A Berkeley View on Serverless Computing 》的论文,论文中也有一个非常清晰形象的比喻,文中这样描述:
在云的上下文中,Serverful 的计算就像使用低级的汇编语言编程,而 Serverless 的计算就像使用 Python 这样的高级语言进行编程。例如 c = a + b 这样简单的表达式,如果用汇编描述,就必须先选择几个寄存器,把值加载到寄存器,进行数学计算,再存储结果。这就好比今天在云环境下 Serverful 的计算,开发首先需要分配或找到可用的资源,然后加载代码和数据,再执行计算,将计算的结果存储起来,最后还需要管理资源的释放。
论文中所谓的 Serverful 计算,是我们今天主流的使用云的方式,但不应该是未来我们使用云的方式。我认为 Serverless 的愿景应该是 Write locally, compile to the cloud,即代码只关心业务逻辑,由工具和云去管理资源。
Serverless 的价值
在对 Serverless 有一个总体的抽象概念之后,也需要具体了解 Serverless 平台的主要特点,同时这些特点也是 Serverless 核心优势的体现。
1. 不用关心服务器
管理一两台服务器可能不是什么麻烦的事情,管理数千甚至数万台服务器就没那么简单了。任何一台服务器都可能出现故障,如何自动识别故障,摘除有问题的实例,这是 Serverless 平台必须具备的能力;此外,操作系统的安全补丁升级,需要做到不影响业务,自动完成;日志和监控系统需要默认打通;系统的安全策略需要自动配置好以避免风险;当资源不够时,需要能够自动分配资源并安装相关的代码和配置,等等。
2. 自动弹性
今天的互联网应用都被设计成可伸缩架构,当业务有比较明显的高峰和低谷时,或者业务有临时的容量需求时(比如营销活动),Serverless 平台都能够及时且稳定地实现自动弹性。为了实现这个能力,平台需要有非常强大的资源调度能力,以及对应用各项指标(如 load 、并发)非常敏锐的感知能力。
3. 按实际资源使用计费
Serverful 的方式使用云资源,是按占用而非使用计费的,例如用户在云上购买了三台 ECS,那么不管用户实际使用了这三台 ECS 多少的 CPU 和内存,他都需要支付这三台 ECS 整体的费用。而在 Serverless 模式下,用户是按实际使用的资源付费的,例如一个请求实际使用了一台 1core2g 规格资源 100ms 的时间,那么用户就只需要为该规格的单价乘以时间(即 100ms )付费。类似的,用户如果用的是 Serverless 数据库,那么就只需要为 query 实际消耗的资源,以及数据存储的资源付费。
4. 更少的代码,更快的交付速度
基于 Serverless 架构的代码通常会重度使用后端的服务,将数据、状态管理等内容从代码中分离出去;此外,更彻底的 FaaS 架构则把代码的 Runtime 也交给了平台管理。这就意味着,同样的应用,Serverless 模式下的代码相比 Serverful 模式会少很多,因此不论是从分发还是启动,都会更快。Serverless 平台也通常能够提供非常成熟的代码构建发布、版本切换等特性,提升交付速度。
作者简介
许晓斌,阿里云高级技术专家。目前负责阿里集团 Serverless 研发运维平台建设,在这之前负责 AliExpress 微服务架构、Spring Boot 框架、研发效率提升工作。《 Maven 实战》作者,曾经是 Maven 中央仓库的维护者。
]]>
作者 | 西流 阿里云技术专家
前言
当您第一次接触 Serverless 的时候,有一个不那么明显的新使用方式:与传统的基于服务器的方法相比,Serverless 服务平台可以使您的应用快速水平扩展,并行处理的工作更加有效。这主要是因为 Serverless 可以不必为闲置的资源付费,不用担心预留的资源不够。而在传统的使用范式中,用户必须预留成百上千的服务器来做一些高度并行化但执行时长较短的任务,而且必须为每一台服务器买单,即使有的服务器已经不再工作了。
以阿里云 Serverless 产品——函数计算为例,便可以完美解决您上述所有顾虑:
- 如果您的任务本身计算量不是很大,但是有大量的并发任务请求需要并行处理, 比如多媒体文件处理、文档转换等;
- 一个任务本身计算量很大,要求单个任务很快处理完,并且还能支持并行处理多个任务。
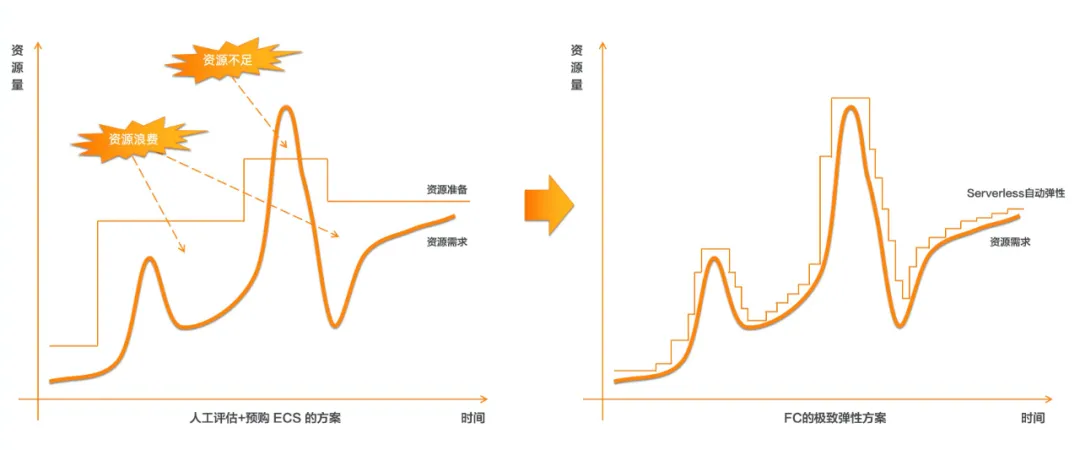
在这种场景下,用户唯一关注的就是:您的任务是可以分治拆解并且子任务是可以并行处理的,一个需要一个小时才能处理完的长任务,可以分解成 360 个独立的 10 秒长的子任务并行处理,这样,以前您要花一个小时才能处理完的任务,现在只需要 10 秒就可以搞定。由于采用的是按量计费的模型,完成的计算量和成本是大致相当的,而传统模型则因为预留资源肯定会存在浪费,浪费的费用也是需要您去承担的。
接下来,将详细阐述 Serverless 在大规模数据处理上的实践。
极致弹性扩缩容应对计算波动
在介绍相关的大规模数据处理示例之前, 这里先简单介绍一下函数计算。
1. 函数计算简介
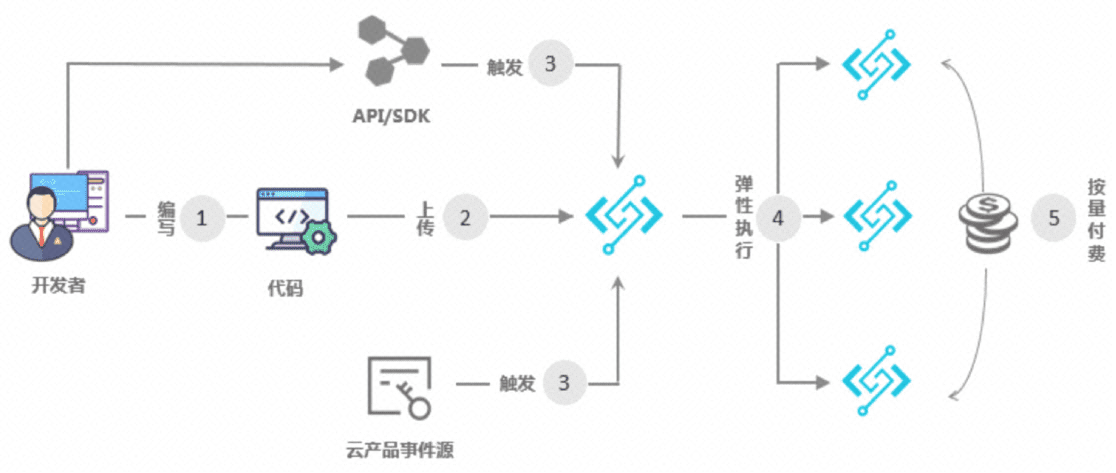
- 开发者使用编程语言编写应用和服务,函数计算支持的开发语言请参见开发语言列表;
- 开发者上传应用到函数计算;
- 触发函数执行:触发方式包括 OSS 、API 网关、日志服务、表格存储以及函数计算 API 、SDK 等;
- 动态扩容以响应请求:函数计算可以根据用户请求量自动扩容,该过程对您和您的用户均透明无感知;
- 根据函数的实际执行时间按量计费:函数执行结束后,可以通过账单来查看执行费用,收费粒度精确到 100 毫秒。
详情:函数计算官网
至此,您大约可以简单理解到函数计算是怎么运作的,接下来以大量视频并行转码的案例来阐述:假设一家在家教育或娱乐相关的企业,老师授课视频或者新的片源一般是集中式产生,而您希望这些视频被快速转码处理完以便能让客户快速看到视频回放。比如在当下疫情中,在线教育产生的课程激增,而出课高峰一般是 10 点、12 点、16 点、18 点等明显的峰值段,特定的时间内(比如半个小时)处理完所有新上传的视频是一个通用而且普遍的需求。
2. 弹性高可用的音视频处理系统
- OSS 触发器

如上图所示,用户上传一个视频到 OSS,OSS 触发器自动触发函数执行,函数计算自动扩容,执行环境内的函数逻辑调用 FFmpeg 进行视频转码,并且将转码后的视频保存回 OSS 。
- 消息触发器
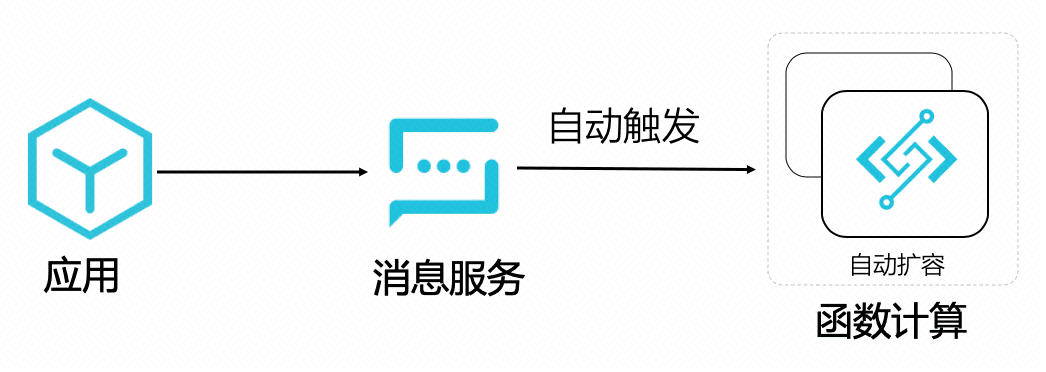
如上图所示,应用只需要发一个消息,自动触发函数执行音视频处理的任务即可,函数计算自动扩容,执行环境内的函数逻辑调用 FFmpeg 进行视频转码, 并且将转码后的视频保存回 OSS 。
- 直接手动调用 SDK 执行音视频处理任务
以 python 为例,大致如下:
python # -*- coding: utf-8 -*- import fc2 import json client = fc2.Client(endpoint="http://123456.cn-hangzhou.fc.aliyuncs.com",accessKeyID="xxxxxxxx",accessKeySecret="yyyyyy") # 可选择同步 /异步调用 resp = client.invoke_function("FcOssFFmpeg", "transcode", payload=json.dumps( { "bucket_name" : "test-bucket", "object_key" : "video/inputs/a.flv", "output_dir" : "video/output/a_out.mp4" })).data print(resp) 从上面我们也可以看出,触发函数执行的方式也很多,同时简单配置下 SLS 日志,就可以很快实现一个弹性高可用、按量付费的音视频处理系统,同时能提供免运维、具体业务数据可视化、强大自定义监控报警等超强功能的 dashboard 。

目前已经落地的音视频案例有 UC 、语雀、躺平设计之家、虎扑以及几家在线教育的头部客户等,其中有些客户高峰期间,弹性使用到了万核以上 CPU 计算资源,并行处理的视频达到 1700+,同时提供了极高的性价比。
详情可以参考:
任务分治,并行加速
这种将任务分而治之的思想应用在函数计算上是一件有趣的事情,在这里举一个例子,比如您有一个超大的 20G 的 1080P 高清视频需要转码,即使您使用一台高配机器,需要的时间可能还是要按小时计,如果中途出问题中断转码,您只能重新开始再重复一遍转码的过程,如果您使用分治的思想+函数计算,转码的过程衍变为 分片-> 并行转码分片-> 合并分片,这样就可以解决您上述的两个痛点:
- 分片和合成分片是内存级别的拷贝,需要的计算量极小,真正消耗计算量的转码,拆分成了很多子任务并行处理,在这个模型中,分片转码的最大时间基本等同于整个大视频的转码时间;
- 即使中途某个分片转码出现异常,只需要重试这个分片的转码即可,不需要整个大任务推倒重来。
通过将大任务合理的分解,配合使用函数计算,编写一点 code,就可以快速完成一个弹性高可用、并行加速、按量付费的大型数据处理系统。
在介绍这个方案之前,我们先简单介绍一下 Serverless 工作流,Serverless 工作流可以很好地将函数和其他云服务和自建服务有组织地编排起来。
1. Serverless 工作流简介
Serverless 工作流( Serverless Workflow )是一个用来协调多个分布式任务执行的全托管云服务。在 Serverless 工作流中,您可以用顺序、分支、并行等方式来编排分布式任务,Serverless 工作流会按照设定好的步骤可靠地协调任务执行,跟踪每个任务的状态转换,并在必要时执行用户定义的重试逻辑,以确保工作流顺利完成。Serverless 工作流简化了开发和运行业务流程所需要的任务协调、状态管理以及错误处理等繁琐工作,让您聚焦业务逻辑开发。
接下来以一个大视频快速转码的案例来阐述 Serverless 工作编排函数,实现大计算任务的分解,并行处理子任务,最终达到快速完成单个大任务的目的。
2. 大视频的快速多目标格式转码
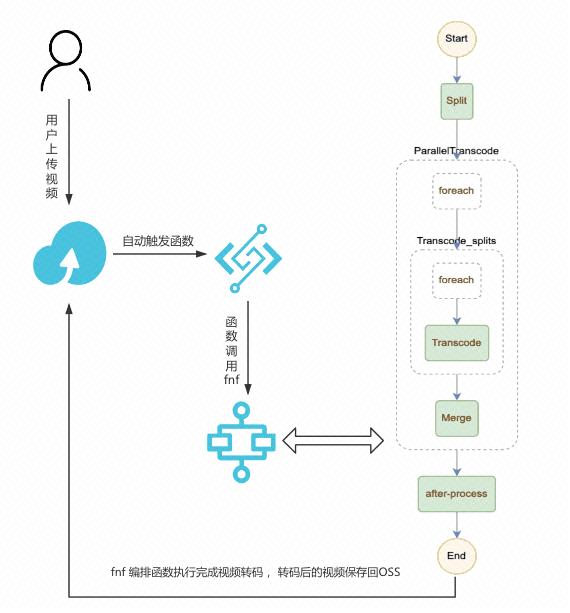
如下图所示,假设用户上传一个 mov 格式的视频到 OSS,OSS 触发器自动触发函数执行,函数调用 FnF 执行,FnF 同时进行 1 种或者多种格式的转码(由 template.yml 中的 DST_FORMATS 参数控制),假设配置的是同时进行 mp4 和 flv 格式的转码。
-
一个视频文件可以同时被转码成各种格式以及其他各种自定义处理,比如增加水印处理或者在 after-process 更新信息到数据库等;
-
当有多个文件同时上传到 OSS,函数计算会自动伸缩,并行处理多个文件,同时每次文件转码成多种格式也是并行;
-
结合 NAS + 视频切片,可以解决超大视频的转码,对于每一个视频,先进行切片处理,然后并行转码切片,最后合成,通过设置合理的切片时间,可以大大加快较大视频的转码速度;
-
fnf 可以跟踪每一步执行情况,并且可以自定义每一个步骤的重试,提高任务系统的鲁棒性,如:retry-example
详情可以参考:fc-fnf-video-processing
在任务分治,并行加速具体的案例中,上面分享的是 CPU 密集型任务分解,但也可以进行 IO 密集型任务分解,比如这个需求:上海的 region 的 OSS bucket 中的一个 20G 大文件,秒级转存回杭州的 OSS Bucket 中。这里也可以采用分治的思路,Master 函数在接到转存任务之后,将超大文件进行分片的 range 分配给每个 Worker 子函数,Worker 子函数并行转存属于自己那部分的分片,Master 函数待所有子 Worker 运行完毕之后,提交合并分片请求,完成整个转存任务。
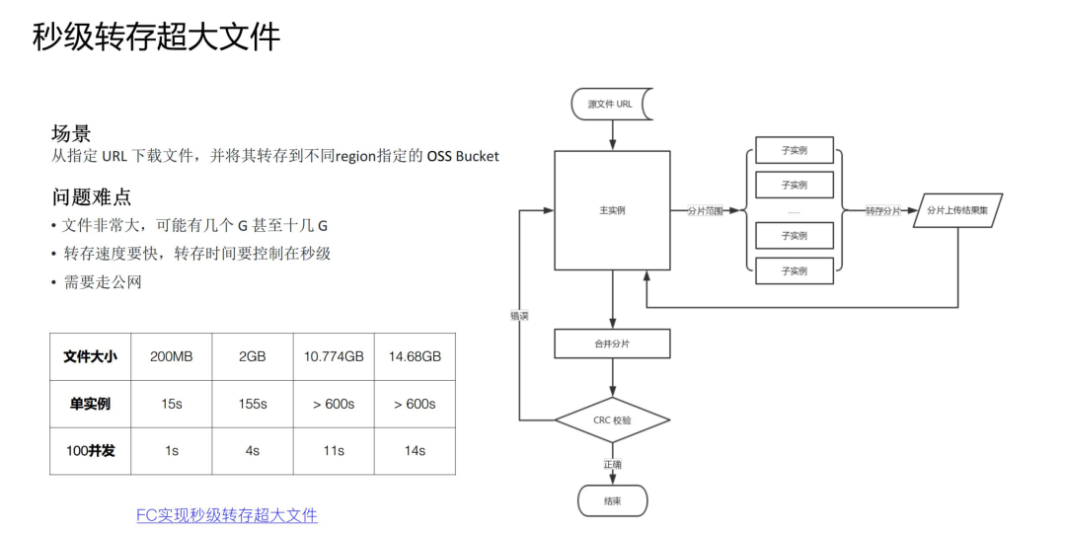
详情可以参考:利用函数计算多实例并发实现秒级转存超大文件
总结
本文探讨了 Serverless 服务平台可以使您的应用快速水平扩展,并行处理的工作更加有效,并给出了具体的实践案例,无论在 CPU 密集型还是 IO 密集型场景,函数计算 + Serverless 都能完美解决您以下顾虑:
- 不必为闲置的资源付费
- 不用担心计算资源预留不够
- 大计算量的任务需要快速处理完毕
- 更好的任务流程跟踪
- 完善的监控报警、免运维、业务数据可视化等
- ....
本文中对于 Serverless 音视频处理只是一个示例,它展示的是函数计算配合 Serverless 工作流在离线计算场景中的能力和独一无二的优势。我们可以用发散的方式去拓展 Serverless 在大规模数据处理实践的边界,比如 AI 、基因计算、科学仿真等。希望本篇文章能吸引您,开启您的 Serverless 奇妙之旅。
]]>
作者 | Hongqi 阿里云高级技术专家
究竟什么是 Serverless 架构?
什么是 Serverless 架构?按照 CNCF 对 Serverless 计算的定义,Serverless 架构应该是采用 FaaS (函数即服务)和 BaaS (后端服务)服务来解决问题的一种设计。这个定义让我们对 Serverless 的理解稍显清晰,同时可能也造成了一些困扰和争论。
- 随着需求和技术的发展,业界出现了一些 FaaS 以外的其它形态的 Serverless 计算服务,比如 Google Cloud Run,阿里云推出的面向应用的 Serverless 应用引擎服务以及 Serverless K8s,这些服务也提供了弹性伸缩能力和按使用计费的收费模式,具备 Serverless 服务的形态,可以说进一步扩大了 Serverless 计算的阵营;
- 为了消除冷启动影响,FaaS 类服务如阿里云的函数计算和 AWS 的 Lambda 相继推出了预留功能,变得不那么“按使用付费”了;
- 一些基于服务器( Serverful )的后端服务也推出了 Serverless 形态产品,比如 AWS Serverless Aurora,阿里云 Serverless HBase 服务。
这样看来,Serverless 的界线是有些模糊的,诸多云服务都向着 Serverless 方向演进。一个模糊的东西如何指导我们解决业务问题呢? Serverless 有一个根本的理念是一直没有改变的,即让用户最大化地专注业务逻辑,其它的特征如不关心服务器、自动弹性、按使用计费等,都是为了实现这个理念而服务。
著名的 Serverless 实践者 Ben Kehoe 这样描述 Serverless 原生心智,当我们在业务中考虑做什么时可以体会一下这种心智:
- 我的业务是什么?
- 做这件事情能不能让我的业务出类拔萃?
- 如果不能,我为什么要做这件事情而不是让别人来解决这个问题?
- 在解决业务问题之前没有必要解决技术问题。
在实践 Serverless 架构时,最重要的心智不是选择哪些流行服务和技术,攻克哪些技术难题,而是时刻将专注业务逻辑铭记在心,这样更容易让我们选择合适的技术和服务,明确如何设计应用架构。人的精力是有限的,组织的资源是有限的,Serverless 的理念可以让我们更好地用有限的资源解决真正需要解决的问题,正是因为我们少做了一些事情,转而让别人做这些事情,我们才可以在业务上做的更多。
接下来我们介绍一些常见的场景,并探讨如何使用 Serverless 架构支持这些场景。我们主要会采用计算、存储和消息通信等技术来设计架构,从可运维性、安全性、可靠性、可扩展性、成本几个角度来衡量架构的优劣。为了让这种讨论不过于抽象,我们会用一些具体的服务作为参考,但是这些架构的思想是通用的,可以用其它类似产品实现。
场景 1: 静态 Web 站点

假如我们要做一个信息展示的网站,需求很简单,就像早年的中国黄页那样,信息更新很少,大概有以下几种主要选择:
- 买台服务器放在 IDC 机房里托管,运行站点;
- 去云厂商上买台云服务器运行站点,为了解决高可用的问题又买了负载均衡服务和多个服务器;
- 采用静态站点方式,直接由对象存储服务(如 OSS )支持,并使用 CDN 回源 OSS 。
这三种方式由云下到云上,由管理服务器到无需管理服务器,即 Serverless 。这一系列的转变给使用者带来了什么变化呢?前两种方案需要预算,需要扩展,需要实现高可用,需要自行监控等,这些都不是马老师当年想要的,他只想去展示信息,让世界了解中国,这是他的业务逻辑。Serverless 正是这样一种理念,最大化地让人去专注业务逻辑。第三种方式就是采用了 Serverless 架构去构建一个静态站点,它有其它方案无法比拟的优势,比如:
- 可运维性:无需管理服务器,比如操作系统的安全补丁升级、故障升级、高可用性,这些云服务( OSS,CDN )都帮着做了;
- 可扩展性:无需对资源做预估和考虑未来的扩展,因为 OSS 本身是弹性的,使用 CDN 使得系统延迟更小、费用更低、可用性更高;
- 成本:按实际使用的资源付费,包括存储费用和请求费用,没有请求时不收取请求费用;
- 安全性:这样一个系统甚至看不到服务器,不需要通过 SSH 登录,DDoS 攻击也交给云服务来解决。
场景 2: 单体和微服务应用
静态页面和站点适合用于内容少、更新频率低的场景,反之,就需要动态站点了。比如淘宝的商品页面,采用静态页面方式管理商品信息是不现实的。如何根据用户请求动态地返回结果呢?我们来看两种常见的解决方案:
- Web 单体应用:所有的应用逻辑都在一个应用中完成,结合数据库,这种分层架构可以快速实现一些复杂度较低的应用;
- 微服务应用:随着业务发展,功能多了,访问量高了,团队大了,这时候一般就需要将单体应用中的逻辑拆分成多个执行单元,比如商品页面上的评论信息、售卖信息、配送信息等,都可以对应一个单独的微服务。这种架构的好处是每个单元是高度自治的,易于开发(比如使用不同技术)、部署和扩展。但是这种架构也引入了分布式系统的一些问题,如服务间通信的负载均衡、失败处理等。
处在不同阶段不同规模的组织可以选择适合自身的方式,来解决它面临的首要业务问题,淘宝最初被人们接受一定不是因为它使用了哪种技术架构。但是无论选择哪种架构,上面提到的 Serverless 原生心智都有助于我们专注业务。比如:
- 是否需要自己购置服务器安装数据库,实现高可用、管理备份、升级版本等,还是可以把这些事情交给托管的服务如 RDS ;是否可以使用表格存储、Serverless HBase 等 Serverless 数据库服务,实现按使用的弹性扩容缩容和付费;
- 单体应用是需要自己购置服务器运行,还是可以交给托管服务,如函数计算和 Serverless 应用引擎;
- 是否可以通过函数来实现轻量级微服务,依赖函数计算提供的负载均衡、自动伸缩、按需付费、日志采集、系统监控等能力;
- 基于 Spring Cloud 、Dubbo 、HSF 等实现的微服务应用是否需要自己购置服务器部署应用,管理服务发现,负载均衡,弹性伸缩,熔断,系统监控等,还是可以将这些工作交给诸如 Serverless 应用引擎服务。
上图右侧的架构引入了 API 网关、函数计算或者 Serverless 应用引擎来实现计算层,将大量的工作交给了云服务完成,让用户最大程度上专注实现业务逻辑。其中系统内部多个微服务的交互如下图所示,通过提供一个商品聚合服务,将内部的多个微服务统一呈现给外部。这里的微服务可以通过 SAE 或者函数实现。

这样的架构还可以继续扩展,比如如何支持不同客户端的访问,如上图右侧所示。现实中这种需求是常见的,不同的客户端需要的信息可能是不同的,手机可以根据位置信息做相关推荐。如何让手机客户端和不同浏览器都能受益于 Serverless 架构呢?这又牵扯出了另一个词——Backend for fronted ( BFF ),即为前端定做的后端,这受到了前端开发工程师的推崇,Serverless 技术让这个架构广泛流行,因为前端工程师可以从业务角度出发直接编写 BFF,而无需管理服务器相关的令前端工程师更加头疼的事情。更多实践可以参见:基于函数计算的 BFF 架构。
场景 3: 事件触发
前面提到的动态页面生成是同步请求完成的,还有一类常见场景,其中请求处理通常需要较长时间或者较多资源,比如用户评论中的图片和视频内容管理,涉及到如何上传图片和处理图片(缩略图、水印、审核等)及视频,以适应不同客户端的播放需求。
如何对上传多媒体文件实时处理呢?这个场景的技术架构大体经历了以下演变:
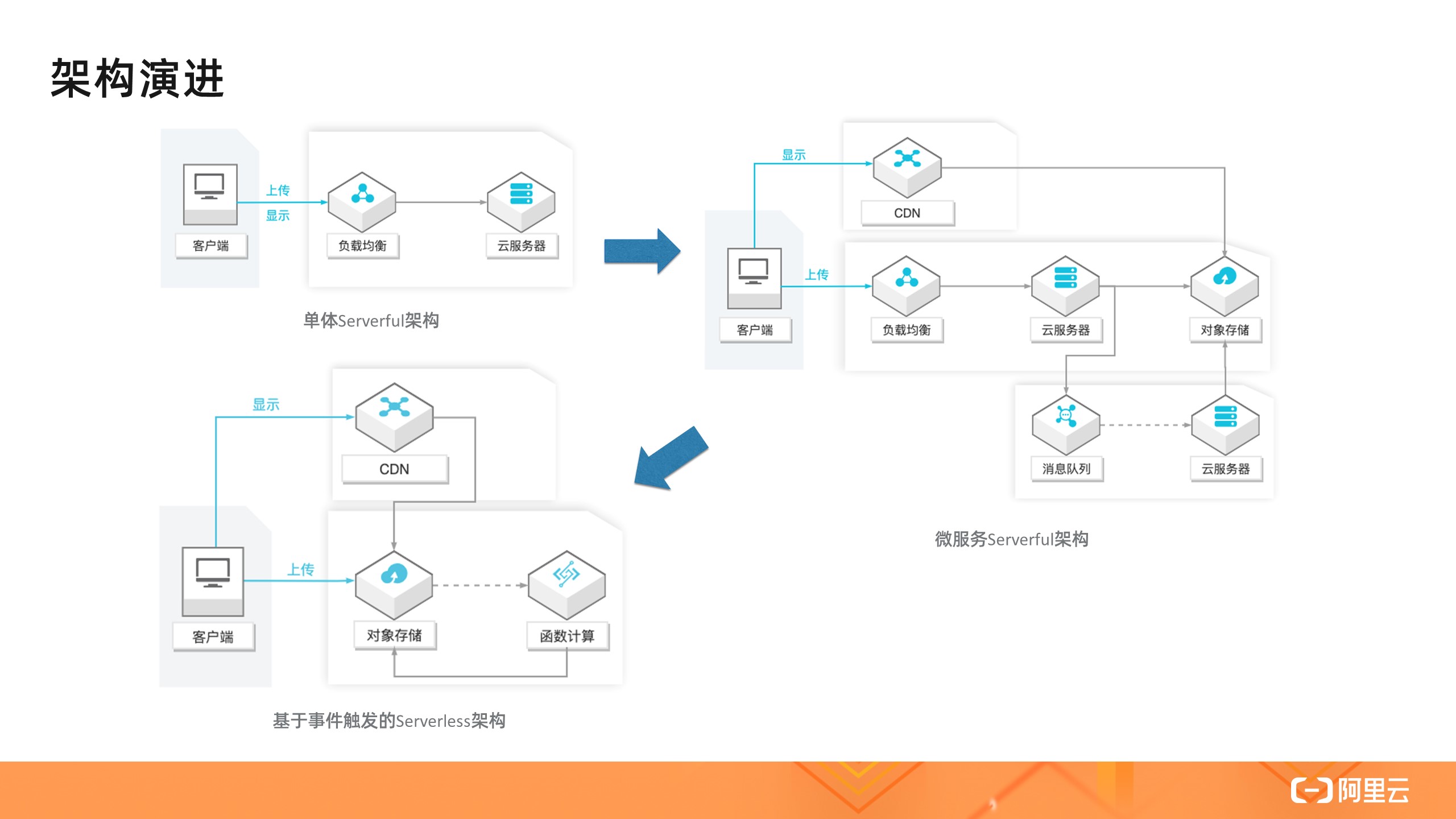
- 基于服务器的单体架构:多媒体文件被上传到服务器,由服务器处理,对多媒体的显示请求也由服务器完成;
- 基于服务器的微服务架构:多媒体文件被上传到服务器,服务器处理转存到 OSS,然后将文件地址加入消息队列,由另一组服务器处理文件,将处理结果保存到 OSS,对多媒体的显示请求由 OSS 和 CDN 完成;
- Serverless 架构:多媒体直接上传到 OSS,由 OSS 的事件触发能力直接触发函数,函数处理结果保存到 OSS,对多媒体的显示请求由 OSS 和 CDN 完成。
基于服务器的单体架构面临以下问题:
- 如何处理海量文件?单台服务器空间有限,购买更多的服务器;
- 如何扩展 Web 应用服务器? Web 应用服务器是否适合 CPU 密集型任务?
- 如何解决上传请求的高可用?
- 如果解决显示请求的高可用?
- 如何应对请求负载的波峰波谷?
基于服务器的微服务架构很好地解决了上述的大部分问题,但是仍然面临一些问题:
- 管理应用服务器的高可用性和弹性;
- 管理文件处理服务器的弹性;
- 管理消息队列的弹性。
而第三种 Serverless 架构很好地解决了上述所有问题。开发人员原来需要做的负载均衡、服务器的高可用和弹性伸缩、消息队列都转移到了服务内部。我们可以看到随着架构的演进,开发人员做的事情越来越少,系统更加成熟,业务上更加聚焦,大大提升了交付速度。
这里的 Serverless 架构主要体现的价值是:
- 事件触发能力:函数计算服务与事件源( OSS )的原生集成让使用者无需管理队列资源,队列自动扩展,实时处理上传的多媒体文件;
- 高弹性和按需付费:图片和视频(不同大小的视频)需要的计算资源规格是不同的,流量的波峰波谷对资源的需求是不同的,现在这种弹性由服务提供,按照用户的真实使用去扩容缩容,让用户 100% 地利用资源,无需为闲置资源付费。
事件触发能力是 FaaS 服务的一个重要特性,这种 Pub-Sub 事件驱动模式不是一个新的概念,但是在 Serverless 流行之前,事件的生产者、消费者以及中间的连接枢纽都是用户负责的,就像前面架构演进中的第二个架构。
Serverless 让生产者发送事件,维护连接枢纽都从用户职责中省略了,而只需关注消费者的逻辑,这就是 Serverless 的价值所在。
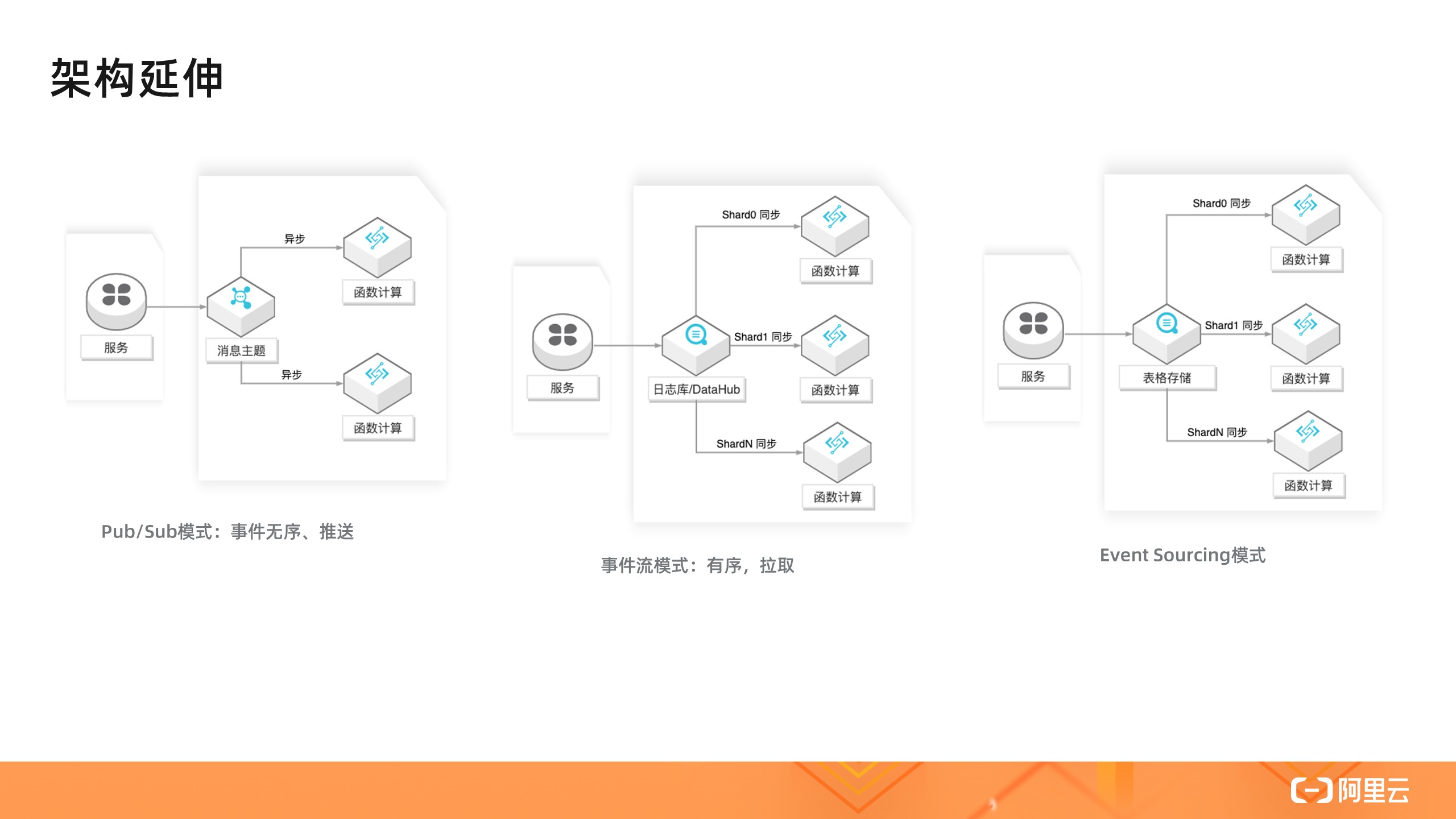
函数计算服务还集成其它云服务事件源,让你更方便地在业务中使用一些常见的模式,如 Pub/Sub 、事件流模式、Event Sourcing 模式。关于更多的函数组合模式可以参见:函数组合的 N 种方式。
场景 4: 服务编排
前面的商品页面虽然复杂,但是所有的操作都是读操作,聚合服务 API 是无状态、同步的。我们来看一下电商中的一个核心场景——订单流程。
这个场景涉及到多个分布式写的问题,这是引入微服务架构导致的最麻烦的一个问题。单体应用在一定程度上可以比较容易地处理这个流程,因为使用了一个数据库,可以通过数据库事务保持数据一致性。但是现实中可能不得不去跟一些外部服务打交道,需要一定的机制保证流程的前进和回退顺利完成,解决这个问题的一个经典模式是 Saga 模式,而实现这种模式有两种不同架构:
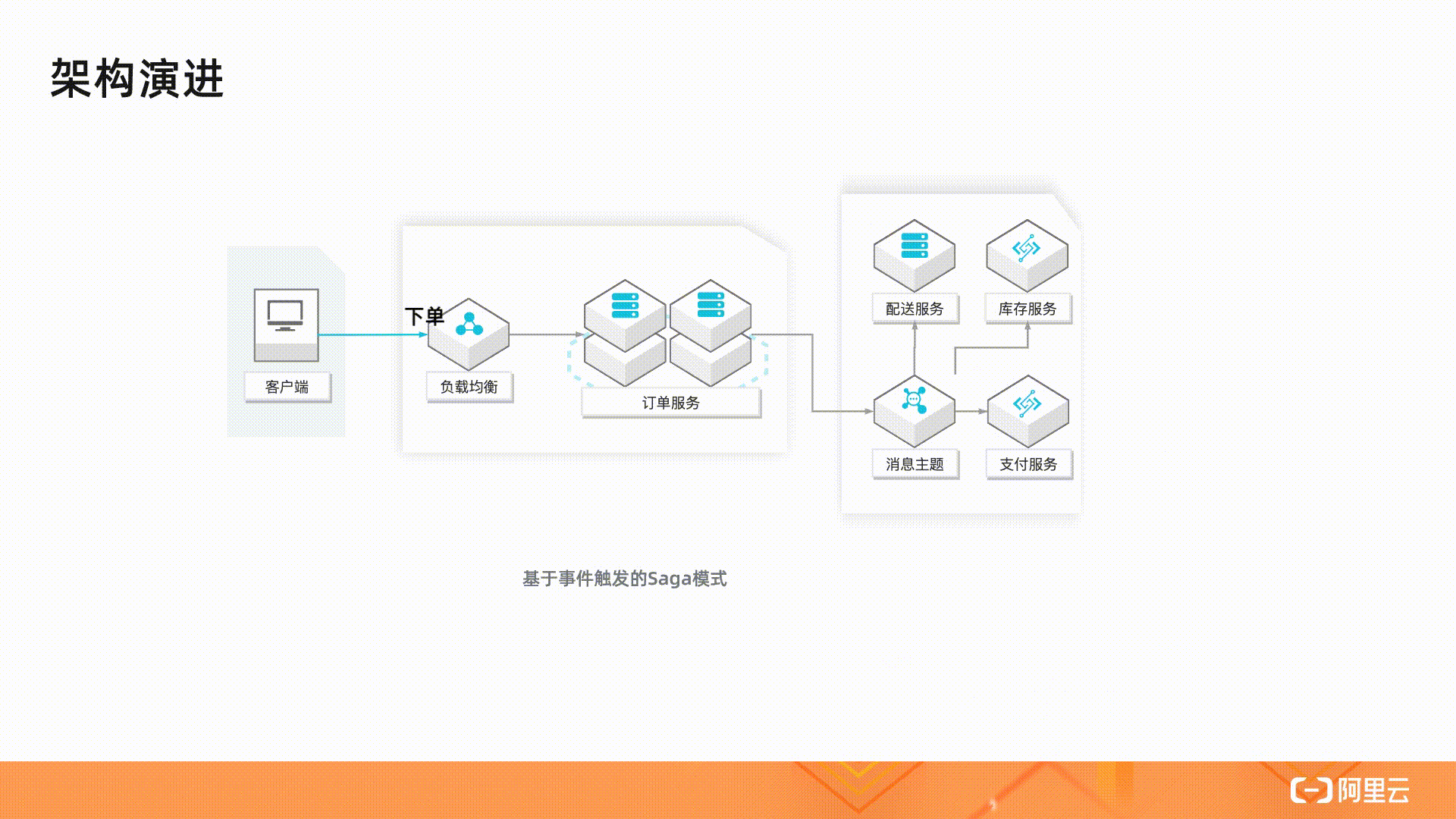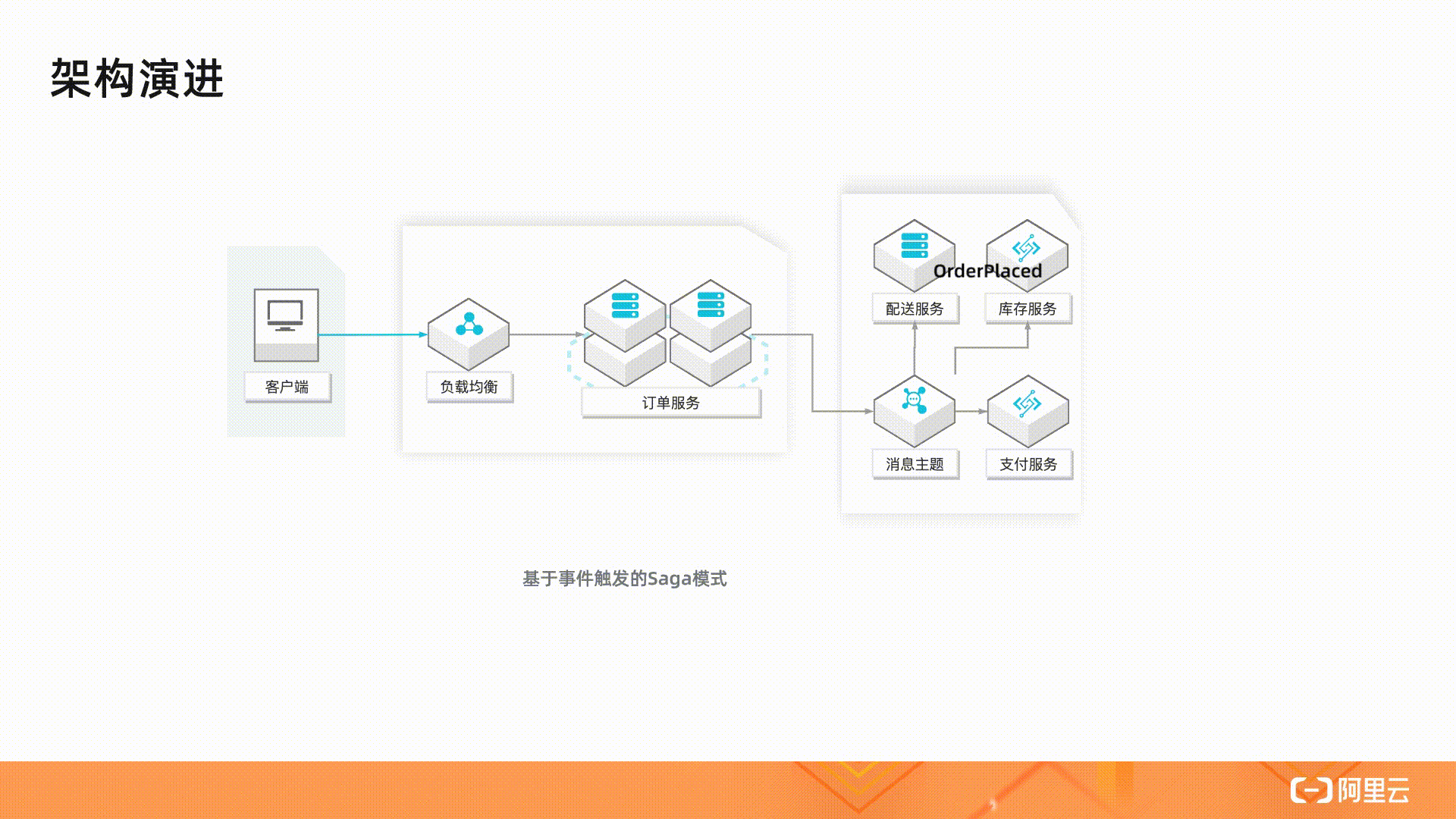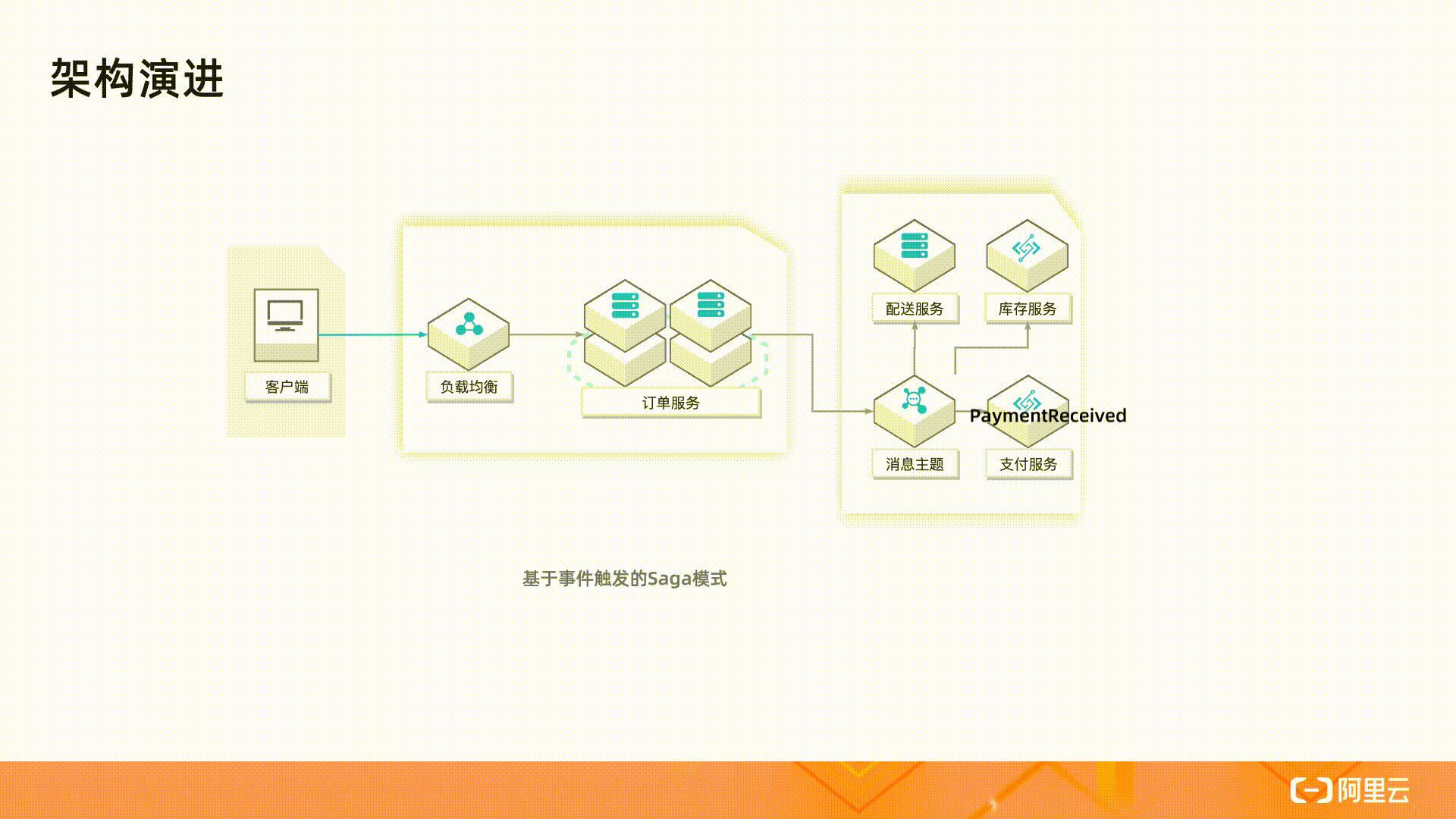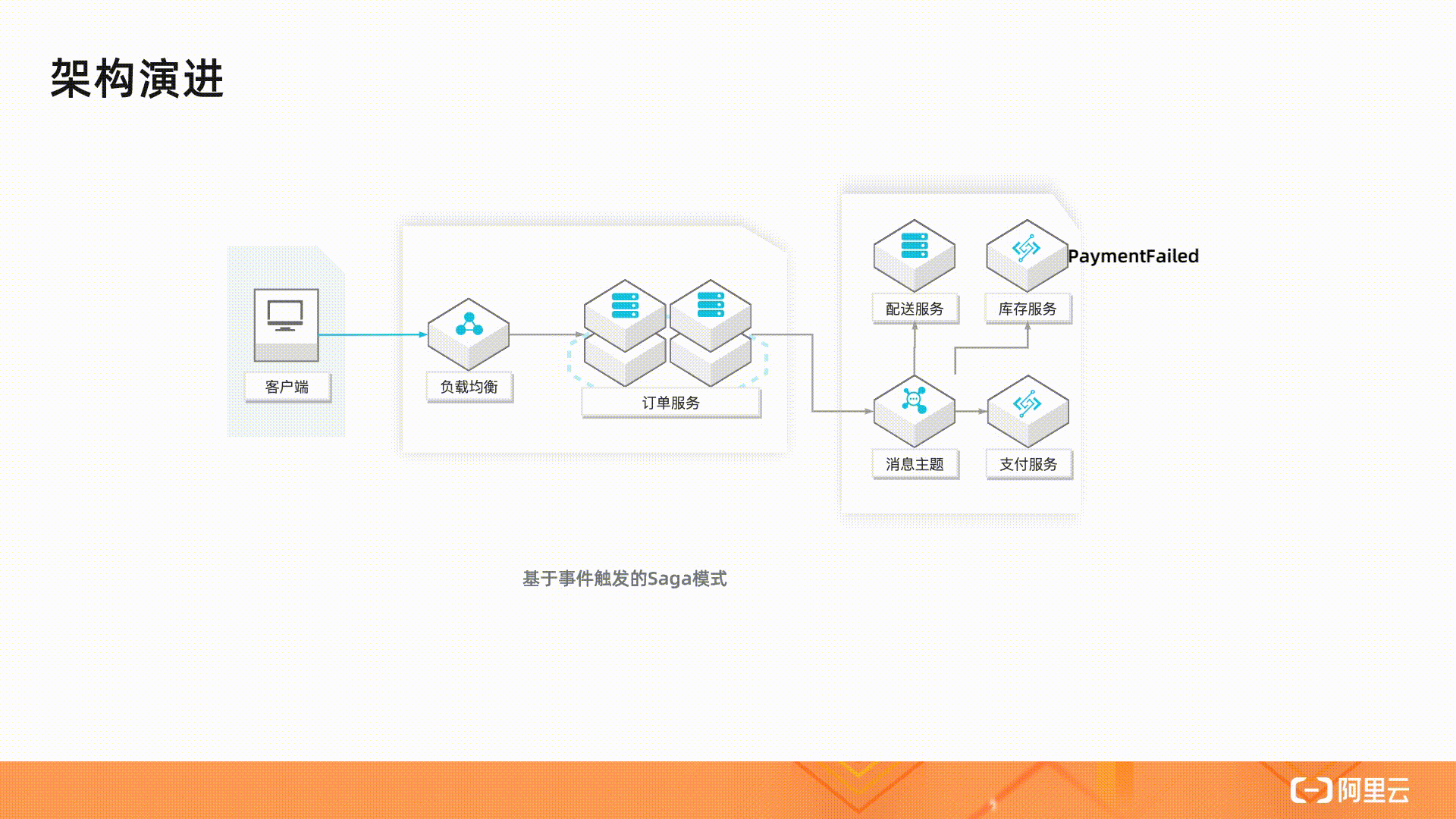
一种做法是采用事件驱动模式,驱动流程完成。在这个架构里,有一个消息总线,感兴趣的服务如库存服务监听事件,监听者可以使用服务器或者函数。借助于函数计算和消息主题的集成,这个架构也可以完全不使用服务器。
这个架构模块是松耦合的,职责清晰。不足之处是随着流程变得更长更加复杂,这个系统变得难以维护。比如很难直观地了解业务逻辑,执行时的状态也不宜跟踪,可运维性比较差。
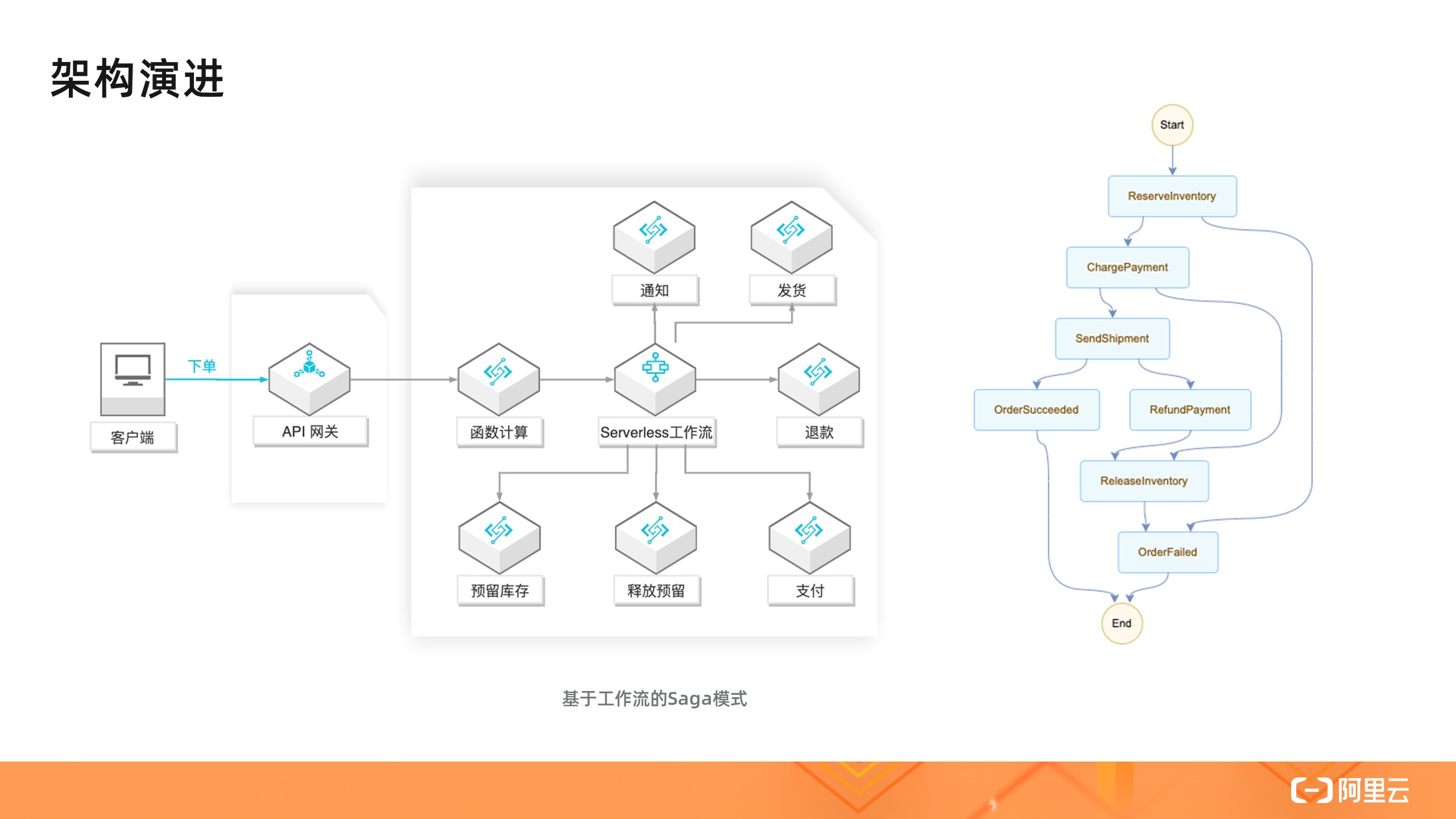
另外一种架构是基于工作流的 Saga 模式。在这个架构里,各个服务之间是独立的,也不通过事件传递信息,而是有一个集中的协调者服务来调度单个业务服务,业务逻辑和状态由集中协调者维护。而实现这个集中的协调者通常面临以下问题:
- 编写大量代码来实现编排逻辑、状态维护和错误重试等功能,而这些实现又很难被其它应用重用;
- 维护运行编排应用的基础设施,以确保编排应用的高可用性和可伸缩性;
- 考虑状态持久性,以支持多步骤长时间运行流程并确保流程的事务性。
依赖于云服务,比如阿里云的 Serverless 工作流服务,这些事情都可以交给平台来做,用户又回到了只需关注业务逻辑的状态。
下图右侧是流程定义,我们可以看到这实现了前面基于事件的 Saga 模式的效果,并且流程大大简化,提升了可观测性。
场景 5: 数据流水线
随着业务的进一步发展,数据变得越来越多,这时候就可以挖掘数据的价值。比如,分析用户对网站的使用行为并做相应的推荐。一个数据流水线包括数据采集、处理、分析等多个环节。这样的服务如果从头搭建虽然是可行的,但是也是复杂的,我们这里讨论的业务是电商,而不是去提供一个数据流水线服务。有了这样一个目标,我们做选择时就会变得简单明确。
- 日志服务( SLS )提供了数据采集、分析和投递功能;
- 函数计算( FC )可以对日志服务的数据进行实时处理,将结果写入其它服务,如日志服务、OSS ;
- Serverless 工作流服务可以定时批量处理数据,通过函数定义灵活的数据处理逻辑,构建 ETL 作业;
- 数据湖分析( DLA )提供了 Serverless 化的交互式查询服务,它使用标准 SQL 分析对象存储(OSS)、数据库( PostgreSQL / MySQL 等)、NoSQL ( TableStore 等)等多个数据源的数据。
总结
限于篇幅,我们只讨论了 Serverless 架构在几个场景中的应用,但是在实践中我们可以看出一种共性,即如何将业务逻辑中与业务不相关的工作剥离出去,交给平台和服务完成。这种各司其职、分工协作的做法在其它场合并不陌生,但是 Serverless 的思想让这种形态更为明确。Less is more,少的不只是 Server 和围绕 Server 相关的负担,还可以是业务以外的方方面面,多的是专注的业务和产品的核心竞争力。
]]>
作者 | 万佳 嘉宾 | 杨皓然(不瞋)
导读:云的下一波浪潮是什么?杨皓然称“是 Serverless”。作为一名阿里老兵,他早在 2010 年即加入阿里云,曾深度参与阿里云飞天分布式系统研发和产品迭代的全过程。如今,杨皓然是阿里云 Serverless 负责人。Serverless 有哪些典型的应用场景? Serverless 在研发效能上可以发挥怎样的作用? Serverless 在阿里内部有哪些实践?它的发展趋势是什么?带着这些问题,InfoQ 记者近日采访了阿里云 Serverless 负责人杨皓然。
Serverless 走向繁荣
Serverless 首次出现于 2012 年,中文即“无服务器架构”。它的出现将主机管理、操作系统管理、资源分配、扩容,甚至应用逻辑的全部组件都集成为服务,开发者可以更直接地将大部分后台能力作为一个能力接口来使用。将开发过程中的能力使用改为服务使用,通过构建或使用一个微服务或微功能来响应事件。
从理念空谈到实践落地,Serverless 开始走向繁荣。
根据 O'Reilly 2019 年 12 月发布的 Serverless 使用调研报告显示,已有 40% 的受访者所在的组织采用了 Serverless,并且使用 Serverless 技术的行业也十分广泛。尤其值得关注的是,有超过 50% 的受访者在一至三年内采用 Serverless,而 15% 的受访者在三年前就已经开始使用 Serverless 。
在杨皓然看来,“Serverless 的繁荣”是必然的:
-
首先,从用户需求角度看,在数字化转型时代,企业面临巨大的竞争压力和不确定性,“产品 time-to-market 的能力比任何时候都重要”。
-
其次,从技术发展的趋势看,云的产品体系及其生态正在迅速 Serverles 化。云服务商在存储、数据库、中间件、大数据、AI 等领域提供了大量全托管、Serverless 形态的云服务。同时,API 经济也驱使开发者提供了大量 Serverless 形态的 API 后端服务。
杨皓然说,“在这样的背景下,Serverless 计算应运而生,借助云的 Serverless 产品体系的能力,屏蔽基础设施的复杂度,帮助用户以搭积木的方式构建弹性、可靠、低成本的系统或应用。”
Serverless 的优势在于,它将同质化的、负担繁重的基于服务器等基础设施的开发和运维等工作从应用开发中移除,让用户聚焦于业务创新。相比传统的开发模式,Serverless 模式基于大量成熟的云服务能力构建应用,客户的决策点更少,实施复杂度更低。
因此,对企业而言,Serverless 架构有着巨大的应用潜力。杨皓然称,“随着云产品的完善,产品的集成和被集成能力的加强,软件交付流程自动化能力的提高,我们相信在 Serverless 架构下,企业的敏捷性有 10 倍提升的潜力。”
此外,Serverless 还能帮助用户大幅度提升资源利用率,降低成本,并实现更好的可靠性。

不过,他也坦然指出:
Serverless 最大的挑战在于工具链不够成熟,产品限制较多和适用场景不够广泛。但是,这些问题会随着产品能力的提升而不断改善。在垂直领域,比如前端全栈场景,已经出现针对 Serverless 架构优化的应用框架,进一步降低用户的使用门槛,提高研发效率。
Serverless 的典型应用场景
1. 小程序 /Web/Mobile/API 后端服务
在小程序 /Web/Mobile/API 场景中,业务逻辑复杂多变,迭代上线速度要求高,并且这类在线应用资源利用率通常小于 30%,尤其是小程序等长尾应用,资源利用率更是低于 10%。Serverless 计算的免运维、按需付费的特点非常适合构建小程序 /Web/Mobile/API 后端系统,通过预留计算资源 + 实时自动伸缩,开发者能够快速构建延时稳定、能承载高频访问的在线应用。
据杨皓然介绍,在阿里内部,使用 Serverless 构建后端服务是落地最多的场景,包括前端全栈领域的 Serverless For Frontends 、机器学习算法服务、小程序平台实现等等。
2. 执行大规模批处理任务
典型的离线任务批处理任务系统,例如大规模音视频文件转码服务,包含计算资源管理、任务优先级调度、任务编排、任务可靠执行、任务数据可视化等一系列功能。如果从机器或容器层次开始构建,用户通常使用消息队列进行任务信息的持久化和计算资源的分配,使用 K8s 等容器编排系统实现资源的伸缩和容错,自动搭建或集成监控报警系统。
如果任务涉及多个步骤,还需要整合工作流服务实现可靠步骤执行,而通过 Serverless 计算平台,用户只需要专注于实现任务处理逻辑。同时,Serverless 计算的极致弹性能很好地满足突发任务对算力的需求。
3. 基于事件驱动架构的在线应用和离线数据处理
Serverless 计算服务通过事件驱动方式广泛的与云端各种类型服务集成,用户无需管理服务器等基础设施和编写集成多个服务的“胶水代码”,轻松构建松耦合、分布式的事件驱动架构的应用。
以阿里云函数计算为例,通过 API 网关和函数计算的集成,用户可以快速实现 API 后端服务。通过对象存储和函数计算的事件集成,函数能实时响应对象创建、删除等事件,实现以对象存储为中心的大规模数据处理。通过消息中间件和函数计算的事件集成,用户能快速实现海量消息的处理。通过和阿里云 EventBridge 的集成,无论是一方云服务,还是三方的 SaaS 服务,或者是用户自建的系统,所有的事件都可以快速便捷的被函数计算处理。
4. 运维自动化
通过定时触发器,用户能够用函数快速实现定时任务,而无需管理执行任务的底层服务器。通过云监控触发器,用户可以接收 ECS 重启 / 宕机、OSS 对象存储流控等 IaaS 层服务的运维事件,并自动触发函数处理。
Serverless 对研发效能的变革和创新
Serverless 为用户提供了一种新的应用构建方式。基于大量成熟云服务,用户可以像搭积木一样构建弹性高可用的应用。比如,借助对象存储和函数计算的集成,用户能快速实现大规模数据的并行处理,而无需从头构建和运维底层计算和存储平台,从而大大减少了研发人员的心智负担,提高效率。
此外,Serverless 计算很好地支撑了“基础设施即代码”的模式,提供了大量配套工具,让软件交付流水线的每个环节都高度自动化,帮助开发人员能够聚焦更具创新性的工作,提高研发效能。
Serverless 在阿里内部的实践
据杨皓然介绍,阿里目前已经在前端全栈、大规模批处理任务执行、机器学习算法服务、运维自动化等领域广泛采用 Serverless 架构,成本和研发效能收益明显。
前端全栈领域
阿里提出 SFF ( Serverless For Frontends )架构。SFF 可以利用 Serverless 的弹性扩缩容能力,减少研发对基础设施和运维的关注。对前端开发者而言,他们只需写几个函数即可实现后端业务逻辑,推动业务快速上线。
以淘宝为例,淘宝的内容导购频道使用 SFF 架构平稳支撑双十一大促。此前,导购业务面临的问题有两个:
一是导购业务更新迭代频繁,每次更新后都需要前后端同学的共同配合,这就带来很大的沟通成本;二是导购频道承载淘宝业务核心链路流量,每次大促前都要提前预留大量计算资源,带来很大的运维代价。
淘宝使用 SFF 架构后,频道的业务逻辑由函数承接,每个业务对应独立的入口函数,函数调用下层中间件获取数据,通过数据组装与裁剪计算业务数据,并返回给前端。Serverless 弹性免运维的特性让前端工程师有能力独立负责整条业务链路,全程不需要后端工程师参与,降低了前后端的联调成本,消除了运维代价。
据悉,淘宝在使用 SFF 架构后,项目人力节省 50%,研发效能提升 40%。
杨皓然称,“阿里巴巴经济体前端委员会也在积极探索针对 Serverless 优化的新框架、新工具,增强的 Nodejs 运行时等,推动更多业务场景落地。今年,Serverless 无疑将成为前端全栈领域的热点。”
除了前端全栈领域,阿里内部还大量使用 Serverless 架构实现负载有明显波峰波谷的计算密集型应用,包括音视频处理、基于 headless chrome 的前端自动化测试等,“每天的资源用量达到数万核小时规模”。
此外,阿里云数据库自治服务( DAS )要完成几十万数据库实例的指标分析和预测,对资源的弹性和可靠性有极高的要求。它使用函数计算运行在线和离线的机器学习算法应用,能够轻松应对流量洪峰。而开发人员专注于算法的设计、实现和调优,大幅提高产品的迭代速度。
针对 Serverless 的发展,杨皓然认为:Serverless 近年来一直在高速发展,呈现出越来越大的影响力。同时,主流的云服务商也在不断丰富云产品体系,提高更好的开发工具、更高效的应用交付流水线、更好的可观测性和更细腻的产品间集成。
Serverless 的未来发展
在谈到 Serverless 的发展趋势,杨皓然提到了四个方面:
1. Serverless 将无处不在
任何足够复杂的技术方案都将被实现为全托管、Serverless 化的后端服务。对于任何以 API 作为功能透出方式的平台型产品或组织,例如钉钉、微信、滴滴等,Serverless 都将是其平台战略中最重要的部分。
2. Serverless 将和容器生态有更加紧密的融合
容器在应用的可移植性和交付流程敏捷性上实现了颠覆式创新,它是现代应用构建和交付的一次重要变革。当今,全世界的开发人员都习惯将容器作为应用交付和分发的方式。围绕容器,已经有了完整的应用交付工具链。未来,容器镜像也将成为函数计算等更多 Serverless 应用的分发方式,容器庞大的工具生态和 Serverless 免运维、极致弹性结合在一起,为用户带来全新的体验。
3. Serverless 将通过事件驱动的方式连接云及其生态中的一切
无论是用户自己的应用,还是合作伙伴的服务;无论是 on-premise 环境,还是公有云,所有的事件都能以 Serverless 的方式处理。云服务及其生态将更紧密的连接在一起,成为用户构建弹性高可用应用的基石。
4. Serverless 计算将持续提高计算密度,实现最佳的性能功耗比和性能价格比
Serverless 计算平台一方面要求最高的安全性和最小的资源开销,鱼与熊掌必须兼得;另一方面要保持对原有程序执行方式的兼容,比如支持任意二进制文件,这使得适用于特定语言 VM 的方案不可行。因此 AWS Firecracker,Google gVisor 这样新的轻量虚拟化技术应运而生。以 AWS Firecracker 为例,通过对设备模型的裁剪和 kernel 加载流程的优化,实现了百毫秒的启动速度和极小的内存开销。
实现最佳性能功耗比和性能价格比的另一个重要方向是支持异构硬件。长期以来,X86 处理器的性能越来越难以提升。而在 AI 等对算力要求极高的场景,GPU 、FPGA 、TPU ( Tensor Processing Units ) 等架构的处理器的计算效率更具优势。随着异构硬件虚拟化、资源池化、异构资源调度、应用框架支持的成熟,异构硬件的算力也能通过 Serverless 的方式释放,大幅降低用户使用门槛。
]]>
作者 | 孔德慧(夏莞) 阿里云函数计算开发工程师
什么是函数计算
大家都了解,Serverless 并不是没有服务器,而是开发者不再需要关心服务器。下图是一个应用从开发到上线的对比图:

在传统 Serverful 架构下,部署一个应用需要购买服务器,部署操作系统,搭建开发环境,编写代码,构建应用,部署应用,配置负载均衡机制,搭建日志分析与监控系统,应用上线后,继续监控应用的运行情况。而在 Serverless 架构下,开发者只需要关注应用的开发构建和部署,无需关心服务器相关操作与运维,在函数计算架构下,开发者只需要编写业务代码并监控业务运行情况。这将开发者从繁重的运维工作中解放出来,把精力投入到更有意义的业务开发上。
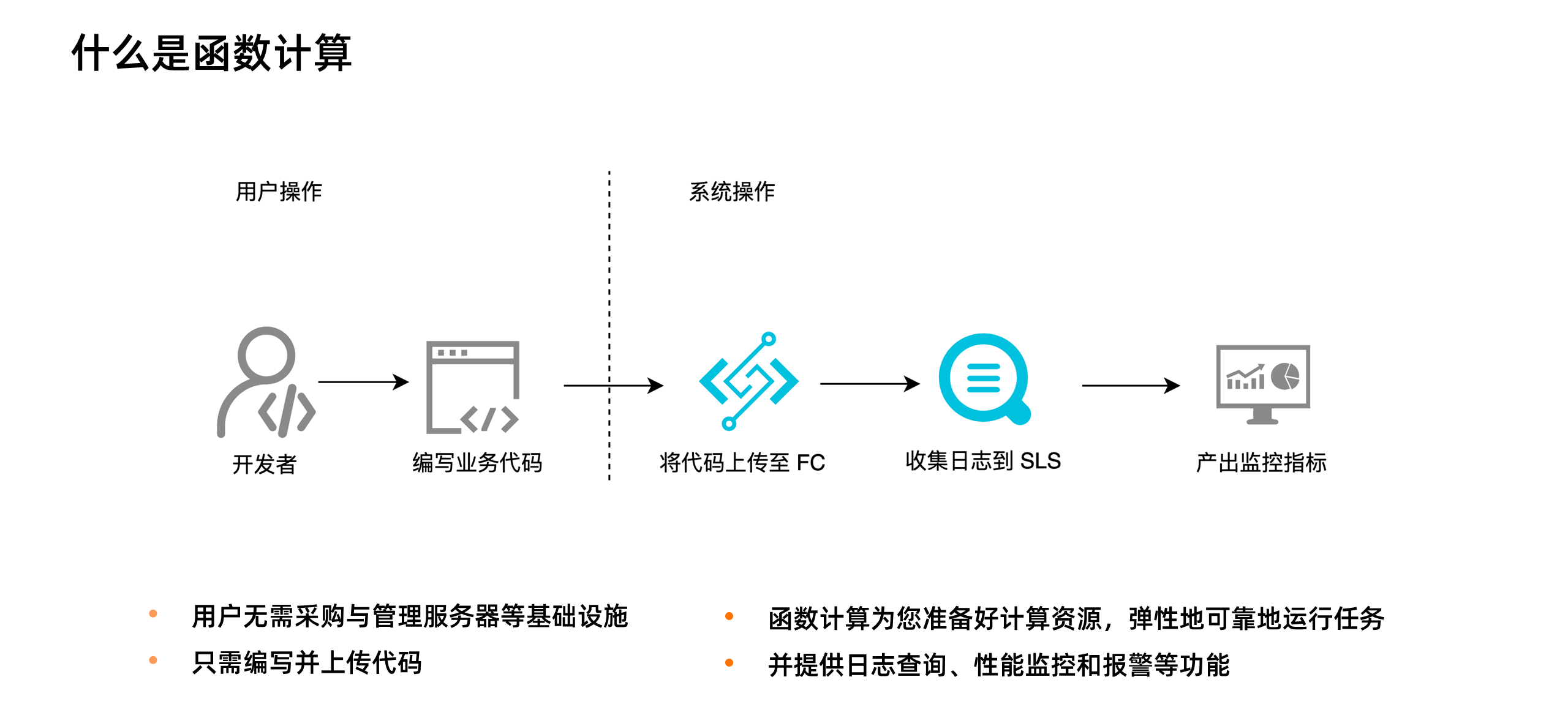
上图展示了函数计算的使用方式。从用户角度,他需要做的只是编码,然后把代码上传到函数计算中。上传代码就意味着应用部署。当有高并发请求涌入时,开发者也无需手动扩容,函数计算会根据请求量毫秒级自动扩容,弹性可靠地运行任务,并内置日志查询、性能监控、报警等功能帮助开发者发现问题并定位问题。
函数计算核心优势

1. 敏捷开发
- 使用函数计算时,用户只需聚焦于业务逻辑的开发,编写最重要的 “核心代码”;
- 不再需要关心服务器购买、负载均衡、自动伸缩等运维操作;
- 极大地降低了服务搭建的复杂性,有效提升开发和迭代的速度。
2. 弹性扩容
- 函数计算根据请求量自动进行弹性扩容,无需任何手动配置;
- 毫秒级调度计算资源,轻松应对业务洪峰。
3. 稳定高可用
- 函数计算分布式集群化部署,支持多可用区;
- 如果某个可用区因自然灾害或电力故障导致瘫痪,函数计算会迅速切换到同区域其他可用区的基础设施运行函数,确保服务高可用。
4. 有竞争力的成本
- 函数计算提供了丰富的计量模式,帮助您在不同场景获得显著成本优势;
- 后付费模型按实际使用计算资源计费,不占用计算资源则不计费,资源利用率高达 100% ;
- 预付费模型根据业务负载估算提前预购计算力,单价更低,组合使用后付费和预付费方式将有效降低成本。
函数计算使用场景

从使用场景来说,主要有三类:
- Web 应用:可以是各种语言写的,这种可以是使用 Serverless 框架新编写的程序,也可以是已有的应用。比如可能是小程序后端,也可能是 Web API 。
- 对计算能力有很强的弹性诉求的应用:比如 AI 推理、音视频处理、图文转换等。
- 事件驱动型的应用:比如通过其他阿里云产品驱动的场景,Web Hook 、定时任务等。
函数计算已经与很多产品进行了打通,比如对象存储、表格存储、定时器、CDN 、日志服务、云监控等十几个产品,可以非常快速地组装出一些业务逻辑。
函数计算工作原理
1. 函数计算调用链路
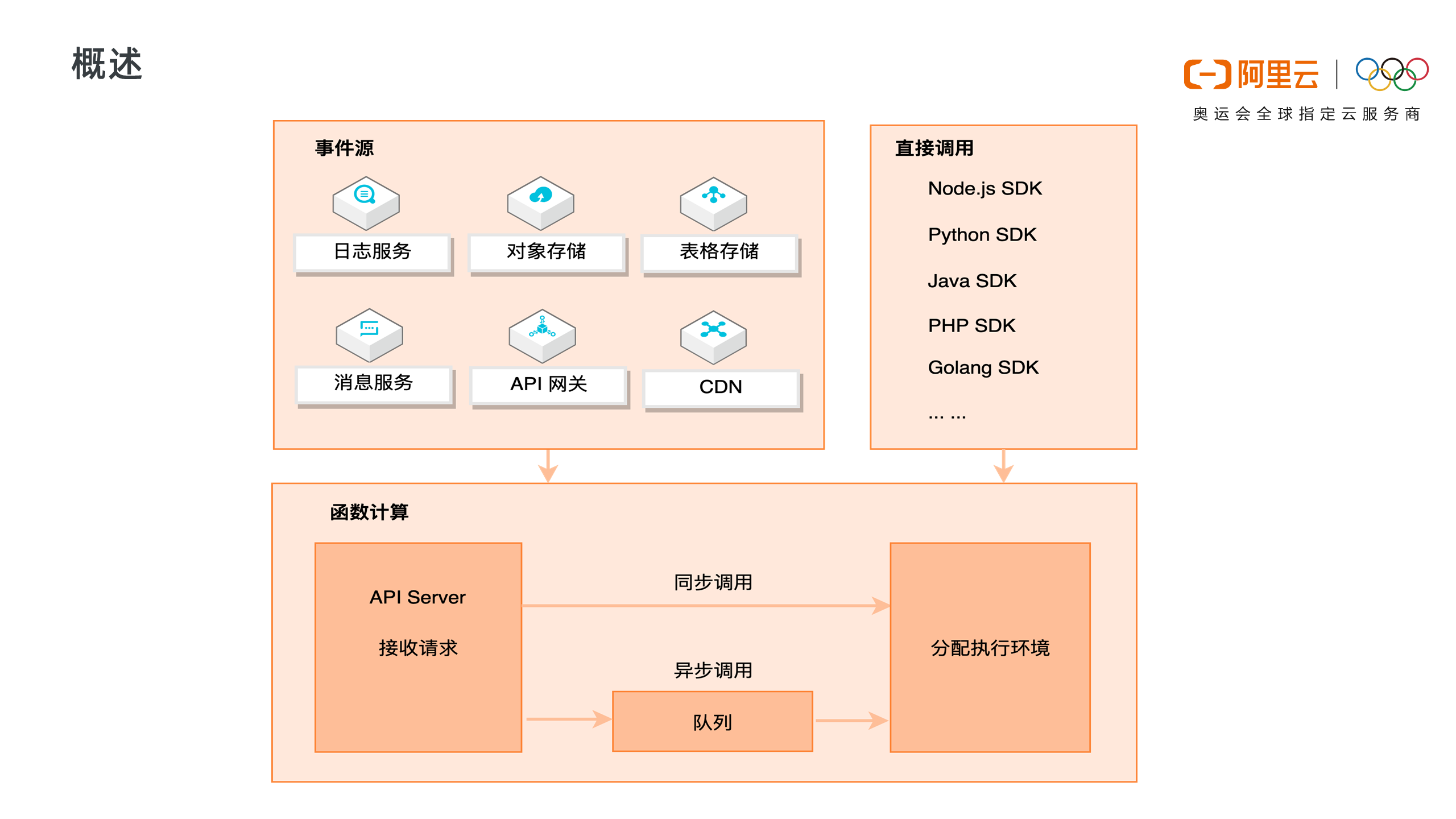
上图展示了函数计算完整的请求和调用链路。函数计算是事件驱动的无服务器应用,事件驱动是说可以通过事件源自动触发函数执行,比如当有对象上传至 OSS 中时,自动触发函数,对新上传的图片进行处理。函数计算支持丰富的事件源类型,包括日志服务、对象存储、表格存储、消息服务、API 网关、CDN 等。
除了事件触发外,也可以直接通过 API/SDK 直接调用函数。调用可以分为同步调用与异步调用,当请求到达函数计算后,函数计算会为请求分配执行环境,如果是异步调用,函数计算会将请求事件存入队列中,等待消费。
2. 函数计算调用方式

同步调用的特性是,客户端期待服务端立即返回计算结果。请求到达函数计算时,会立即分配执行环境执行函数。
以 API 网关为例,API 网关同步触发函数计算,客户端会一直等待服务端的执行结果,如果执行过程中遇到错误, 函数计算会将错误直接返回,而不会对错误进行重试。这种情况下,需要客户端添加重试机制来做错误处理。

异步调用的特性是,客户端不急于立即知道函数结果,函数计算将请求丢入队列中即可返回成功,而不会等待到函数调用结束。
函数计算会逐渐消费队列中的请求,分配执行环境,执行函数。如果执行过程中遇到错误,函数计算会对错误的请求进行重试,对函数错误重试三次,系统错误会以指数退避方式无限重试,直至成功。
异步调用适用于数据的处理,比如 OSS 触发器触发函数处理音视频,日志触发器触发函数清洗日志,都是对延时不敏感,又需要尽可能保证任务执行成功的场景。如果用户需要了解失败的请求并对请求做自定义处理,可以使用 Destination 功能。
3. 函数计算执行过程
函数计算是 Serverless 的,这不是说无服务器,而是开发者无需关心服务器,函数计算会为开发者分配实例执行函数。

如上图所示,当函数第一次被调用的时候,函数计算需要动态调度实例、下载代码、解压代码、启动实例,得到一个可执行函数的代码环境。然后才开始在系统分配的实例中真正地执行用户的初始化函数,执行函数业务逻辑。这个调度实例启动实例的过程,就是系统的冷启动过程。
函数逻辑执行结束后,不会立即释放掉实例,会等一段时间,如果在这段时间内有新的调用,会复用这个实例,比如上图中的 Request 2,由于执行环境已经分配好了,Request 2 可以直接使用,所以 Request 2 就不会遇到冷启动。
Request 2 执行结束后,等待一段时间,如果这段时间没有新的请求分配到这个实例上,那系统会回收实例,释放执行环境。此实例释放后,新的请求 Request 3 来到函数计算,需要重新调度实例、下载代码、解压代码,启动实例,又会遇到冷启动。
所以,为了减小冷启动带来的影响,要尽可能避免冷启动,降低冷启动带来的延时。
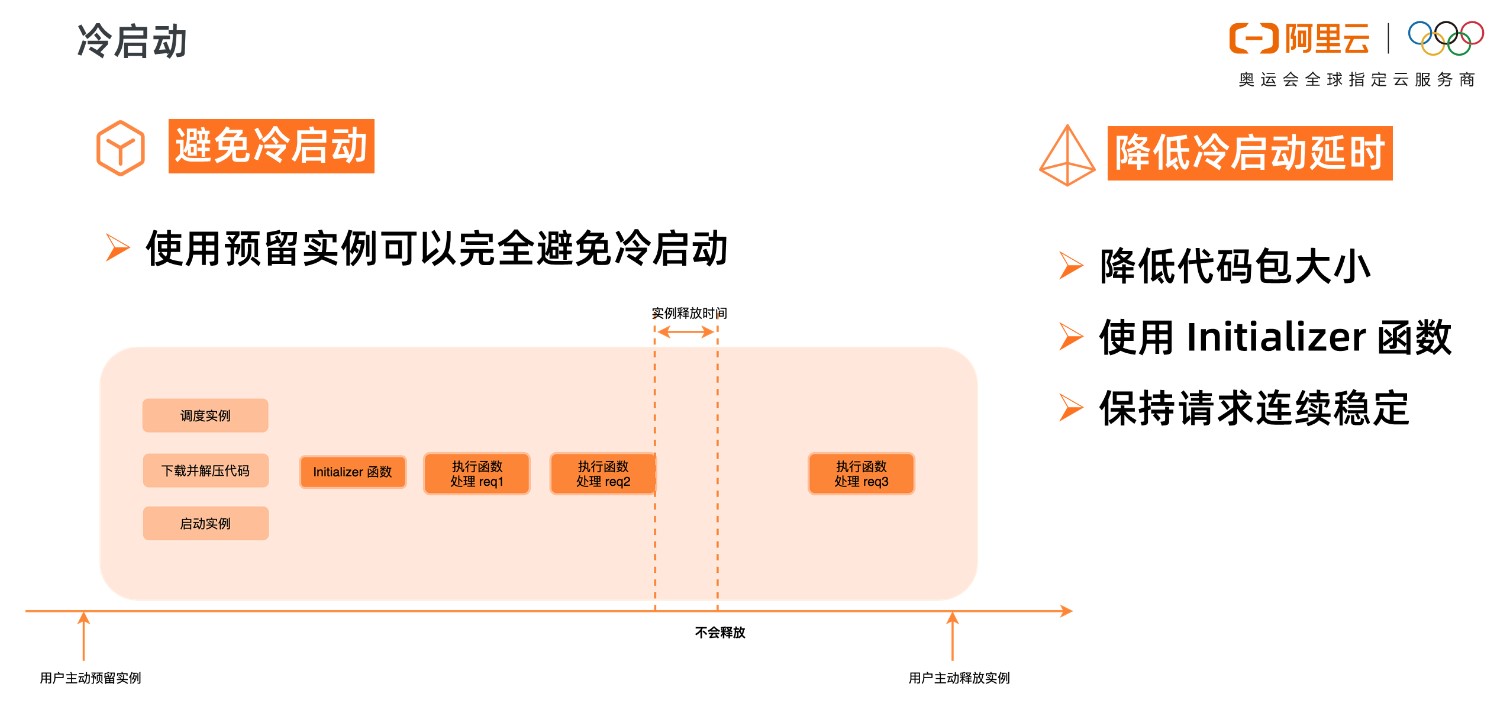
使用预留实例可以完全避免冷启动,预留实例是在用户预留后就分配实例,准备执行环境;请求结束后系统也不会自动回收实例。
预留实例不由系统自动分配与回收,由用户控制实例的生命周期,可以长驻不销毁,这将彻底消除实例冷启动带来的延时毛刺,提供极致性能,也为在线应用迁移至函数计算扫清障碍。
如果业务场景不适合使用预留实例,那就要设法降低冷启动的延时,比如降低代码包大小,可以降低下载代码包、解压代码包的时间。Initializer 函数是实例的初始化函数,Initializer 在同一实例中执行且只执行一次,所以可以将一些耗时的公共逻辑放到 Initializer 中,比如在 NAS 中加载依赖、建立连接等等。另外要尽量保持请求连续稳定,避免突发的流量,由于系统已启动的实例不足以支撑大量的突发流量,就会带来不可避免的冷启动。
]]>
作者 | 不瞋
导读:Serverless 是如何产生的?当前有哪些落地场景? Serverless 的未来又将如何?本文分享了阿里云高级技术专家不瞋对于 Serverless 的看法,回顾其发展历程,并对 Serverless 的发展趋势做出预测。
源起
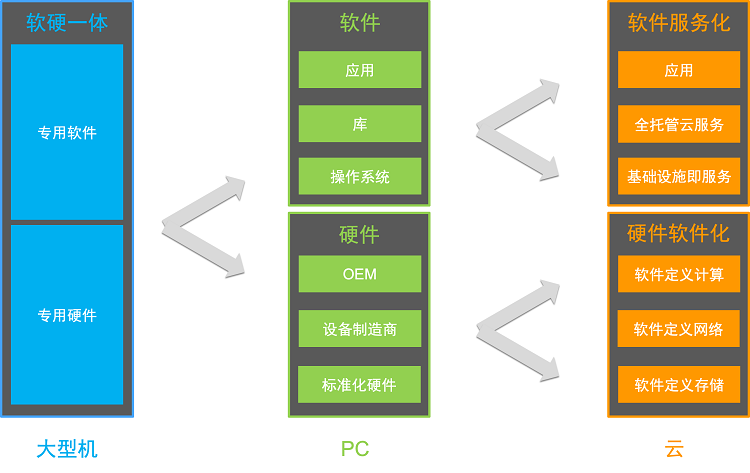
回望整个计算机技术发展史,我们会发现 “抽象、解耦、集成” 的主题贯穿其中。产业每一次的抽象、解耦、集成,都将创新推向新的高度,也催生出庞大的市场和新的商业模式。
大型机时代,硬件和软件都是定制化的,使用专有的硬件、操作系统和应用软件。
PC 时代,硬件被抽象解耦成 CPU 、内存、硬盘、主板、USB 设备等标准化的部件,不同厂商生产的部件可以自由组合,组装成整机。软件被抽象解耦为操作系统、库等可复用组件。硬件和软件的抽象解耦,创造了新的商业模式,释放了生产力,造就了 PC 时代的繁荣。
云的时代,硬件软件化和软件服务化成为最显著的两个趋势。
硬件软件化的核心在于硬件功能中越来越多的部分由软件来呈现,从而在迭代效率、成本等方面获得显著优势。以软件定义存储( Software Defined Storage,SDS )为例,SDS 是位于物理存储和数据请求之间的一个软件层,允许用户操控数据的存储方式和存储位置。通过硬件与软件解耦,SDS 可运行于行业标准系统或者 X86 系统上,意味着用户可以无差别的使用任何标准的商用服务器来满足不断增长的存储需求。硬件与软件解耦也让 SDS 能够横向扩展,消除容量规划,成本管理等方面的复杂性。
云时代的另一趋势是软件服务化。应用软件的功能通过网络以远程调用的模式被海量用户使用。服务成为应用构建的基础,API 被实现为服务提供给开发者,微服务架构获得广泛的成功。服务也成为云产品的基本形态。过去 10 年,云已经证明了它的成功。用户只需要通过调用 API 就能获取服务器,而无需自己建设数据中心。算力以前所未有简洁的方式提供给用户。
还记得 Google 那篇著名的 “Datacenter as a computer” 论文吗?如果我们把云看作是 DT 时代的计算机,那么一个很自然的问题是:随着云的 API (全托管服务)越来越丰富,什么才是适合于云的编程模型?我们应当以何种 “抽象、解耦、集成” 的方式构建基于云的应用?
在回答上述问题之前,让我们首先将目光转向 SaaS 领域。Salesforce 是 SaaS 领域的明星企业,在平台化能力建设方面的布局为我们提供了一个绝佳的案例。早期的 SaaS 产品采用标准化的交付模式,通过开放 API 接口实现被集成的能力。随着 Salesforce 产品越来越丰富,客户规模日益增长,企业开始面临新的挑战:
- 如何更快地推出新产品,加强产品间的整合和协同?
- 客户迅速增长,需求多样。如何高效地满足客户的定制化需求,增加客户粘性?
- 如何提高产品被集成的能力,更好的衔接上下游资源?
- 当产品能力和 API 完整度到达一定水准后,如何让开发者快速整合 API,围绕 Salesforce 能力便捷地开发应用?
- 如何设计好的商业模式,让客户、企业和开发者共赢?
Salesforce 的策略是让整个业务、技术和组织平台化。平台放大了企业的价值,让企业、客户、开发者三方受益。通过不断提升平台的应用交付能力,对内大幅提高产品的研发效率,加强产品的集成和整合;对外则大幅提高了产品的被集成能力,建立开发者生态。
从 2006 年开始,Salesforce 在平台化能力建设上大力投资,推出了 Apex,Visualforce 等编程语言,允许客户、合作伙伴和开发者在多租户环境下编写和运行自定义的逻辑代码。在此基础上,2008 年推出自研 Force.com PaaS 平台,客户能够在该平台上围绕 Salesforce 的能力构建自己的应用程序。2010 年收购了流行的 PaaS 服务商 Heroku,2019 年推出 Serverless 计算平台 Evergreen,进一步加强应用构建和集成与被集成能力。除了应用的构建能力,Salesforce 近几年来也在应用的移动化、数据化和智能化方面进行了大量的投资,延伸平台在相关领域的能力,帮助客户实现管理流程的数据化和智能化,并通过数据分析和交易撮合为客户带来增量业务。
总结 Salesforce 的发展历程,我们可以得出一些观点:
- API 已成为价值交付最重要的形式。
- 把 API 作为价值交付形式的产品或组织,当 API 丰富度和能力完整度达到一定水准后,会升级为平台,通过平台突破能力瓶颈,实现业务、产品和技术新的进化。
- 平台能力高低体现在其编程模型上,即是否能帮助用户高效、低成本的构建新一代应用。
- 平台除了大幅提升企业价值交付的能力,更重要的是建立起应用开发生态。
虽然云远比上述 SaaS 案例复杂,但遵循着类似的发展逻辑。几乎所有云服务的产品功能都通过 API 体现,云服务商也把发展平台编程模型,提升用户价值交付能力和建立应用开发生态作为最重要的目标。当我们从编程模型的视角去审视云的产品体系,纷繁复杂的云服务各自的定位逐渐清晰。
基础设施即服务( IaaS )和容器技术是云的基础设施,以 K8S 为代表的容器编排服务是云原生应用的操作系统,面向特定领域的后端服务( BaaS )则是云的 API 。为了实现更高的生产力,在存储、数据库、中间件、大数据、AI 等领域,大量的 BaaS 服务是全托管、Serverless 的形态,这一趋势已持续多年。例如现在客户已经非常习惯使用 Serverless 化的对象存储,而不是自己基于服务器搭建数据存储系统。当云提供了丰富的 Serverless BaaS 服务后,需要一种新的通用计算服务,能够屏蔽基础设施的复杂度,基于云服务快速构建应用。因此 Serverless 计算应运而生,它包含了以下要素:
- Serverless 计算是全托管的计算服务,客户编写代码构建应用,无需管理和运维服务器等底层基础设施。
- Serverless 计算是通用、普适的,结合云 API ( BaaS 服务)的能力,能够支撑云上所有重要类型的应用。
- Serverless 计算不但实现了最纯粹的按需付费(为代码实际运行消耗的资源付费),也应当支持预付费等计量模式,使得客户成本在各种场景下,与传统方式相比都极具竞争力。
- 不同于虚拟机或容器等面向资源的计算平台,Serverless 计算是面向应用的。要能整合和联动云的产品体系及其生态,帮助用户在价值交付方式上实现颠覆式创新。
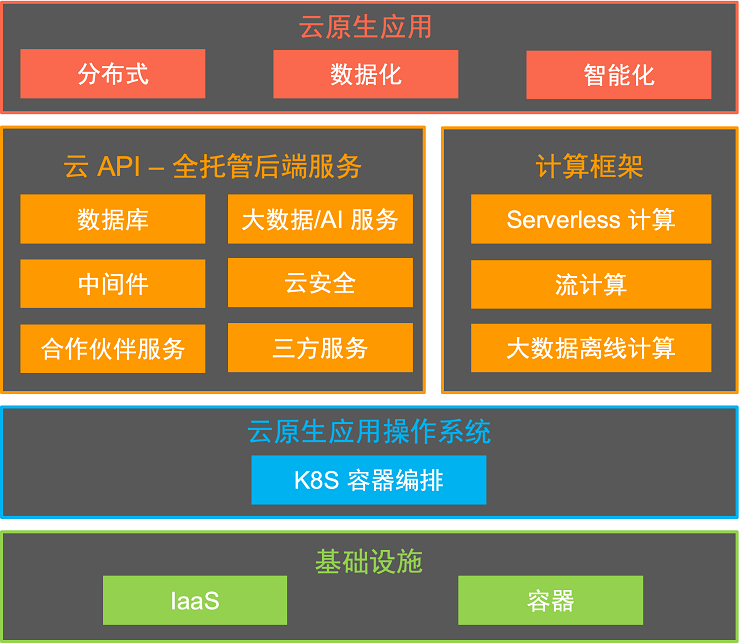
现状
当下 Serverless 在哪些场景落地?
随着用户心智的建立,产品本身能力的完善,Serverless 近年来呈加速发展的趋势。我们看到在很多场景下,用户使用 Serverless 架构在可靠性、成本和研发运维效率等方面获得显著的收益。
1. 小程序 /Web/Mobile/API 后端服务
在小程序、Web/Moible 应用、API 服务等场景中,业务逻辑复杂多变,迭代上线速度要求高,而且这类在线应用,资源利用率通常小于 30%,尤其是小程序等长尾应用,资源利用率更是低于 10%。Serverless 计算的免运维,按需付费的特点非常适合构建小程序 /Web/Mobile/API 后端系统,通过预留计算资源+实时自动伸缩,开发者能够快速构建延时稳定、能承载高频访问的在线应用。在阿里内部,使用 Serverless 构建后端服务是落地最多的场景,包括前端全栈领域的 Serverless For Frontends,机器学习算法服务,小程序平台实现等等。
2. 大规模批处理任务处理
典型的离线任务批处理系统,例如大规模音视频文件转码服务,包含计算资源管理、任务优先级调度、任务编排、任务可靠执行、任务数据可视化等一系列功能。如果从机器或者容器层次开始构建,用户通常使用消息队列进行任务信息的持久化和计算资源的分配,使用 K8S 等容器编排系统实现资源的伸缩和容错,自行搭建或集成监控报警系统。如果任务涉及多个步骤,还需要整合工作流服务实现可靠步骤执行,而通过 Serverless 计算平台,用户只需要专注于实现任务处理逻辑,而且 Serverless 计算的极致弹性能很好的满足突发任务对算力的需求。

3. 基于事件驱动架构的在线应用和离线数据处理
典型的 Serverless 计算服务通过事件驱动的方式广泛的与云端各种类型服务集成,用户无需管理服务器等基础设施和编写集成多个服务的胶水代码,轻松构建松耦合、分布式的事件驱动架构的应用。
以阿里云函数计算为例,通过 API 网关和函数计算的集成,用户可以快速实现 API 后端服务。通过对象存储和函数计算的事件集成,函数能实时响应对象创建、删除等事件,实现以对象存储为中心的大规模数据处理。通过消息中间件和函数计算的事件集成,用户能快速实现海量消息的处理。通过和阿里云 EventBridge 的集成,无论是一方云服务,还是三方的 SaaS 服务,或者是用户自建的系统,所有的事件都可以快速便捷的被函数计算处理。
4. 运维自动化
通过定时触发器,用户能够用函数快速实现定时任务,而无须管理执行任务的底层服务器。通过云监控触发器,用户可以接收 ECS 重启 /宕机,OSS 对象存储流控等 IaaS 层服务的运维事件,并自动触发函数处理。
未来
Serverless 将向何处去?
近年来,Serverless 一直在高速发展,呈现出越来越大的影响力。主流的云服务商也在不断地丰富云产品体系,提供更好的开发工具,更高效的应用交付流水线,更好的可观测性,更细腻的产品间集成,但一切才刚刚开始。
趋势 1:Serverless 将无处不在
任何足够复杂的技术方案将被实现为全托管、Serverless 化的后端服务。不只是云产品,也包括合作伙伴和三方服务。云及其生态的能力将通过 API + Serverless 来体现。事实上,对于任何以 API 作为功能透出方式的平台型产品或组织,例如钉钉、微信、滴滴等等,Serverless 都将是其平台战略中最重要的部分。
趋势 2:和容器生态将更加紧密融合
容器在应用的可移植性和交付流程敏捷性上实现了颠覆式创新,是现代应用构建和交付的一次重要变革。
- 绝佳的可移植性。通过操作系统虚拟化技术,应用及其运行环境被虚拟化为容器,实现了 build once,run anywhere 。容器化的应用能够无差别的运行在开发机,on-premise,以及公有云的环境中。
- 敏捷的交付流程。容器镜像已经成为应用封装和分发事实上的标准。今天全世界的开发人员都习惯将容器作为应用交付和分发的方式。围绕容器,已经建立了完整的应用交付工具链。
容器已经成为现代应用运行的基础,但用户仍然需要负责服务器等基础设施的管理,包括水位预估、机器运维等等。因此业界出现了 AWS Fargate,阿里云 ECI 等 Serverless container 服务,帮助用户专注于容器化应用的构建,而无需负担基础设施的管理成本。从 Serverless 视角来看,函数计算等 Serverless 计算服务为用户带来了全自动的伸缩模式、极致弹性以及完全按需的计量方式,却在用户开发习惯的兼容性、可移植性、完工具链和生态等方面面临挑战,而这正是容器的优势。相信随着技术的发展,未来容器镜像也将成为函数计算等更多 Serverless 应用的分发方式,容器庞大的工具生态和 Serverless 免运维、极致弹性结合在一起,为用户带来全新的体验。
趋势 3:Serverless 将通过事件驱动的方式连接云及其生态中的一切
我们已经在前述章节中讨论了函数计算通过事件驱动和云服务连接的意义,这样的能力也会扩展到整个云的生态。无论是用户自己的应用,还是合作伙伴的服务;无论是 on-premise 环境,还是公有云,所有的事件都能以 Serverless 的方式处理。云服务及其生态将更紧密的连接在一些,成为用户构建弹性高可用的应用的基石。
趋势 4:Serverless 计算将持续提高计算密度,实现最佳的性能功耗比和性能价格比
虚拟机和容器是两种取向不同的虚拟化技术。前者安全性强,开销小,后者则相反。Serverless 计算平台一方面要求最高的安全性和最小的资源开销,鱼与熊掌必须兼得;另一方面要保持对原有程序执行方式的兼容,比如支持任意二进制文件,这使得适用于特定语言 VM 的方案不可行。因此 AWS Firecracker,Google gVisor 这样新的轻量虚拟化技术应运而生。以 AWS Firecracker 为例,通过对设备模型的裁剪和 kernel 加载流程的优化,实现了百毫秒的启动速度和极小的内存开销。一台裸金属实例支持数以千计的实例运行。结合应用负载感知的资源调度算法,云服务商有望在保持稳定性能的前提下,将超卖率提升一个数量级。
当 Serverless 计算的规模和影响力变得越来越大,从应用框架、语言、硬件等层面,根据 Serverless 的负载特点进行端对端优化就变得非常有意义。新的 Java 虚拟机技术大幅提高 Java 应用的启动速度,非易失性内存帮助实例更快被唤醒,CPU 硬件和操作系统协作对高密环境下性能扰动实现精细隔离,所有新技术正在创造崭新的计算环境。
实现最佳性能功耗比和性能价格比的另一个重要方向是支持异构硬件。长期以来,X86 处理器的性能越来越难以提升。而在 AI 等对算力要求极高的场景,GPU 、FPGA 、TPU ( Tensor Processing Units ) 等架构的处理器的计算效率更具优势。随着异构硬件虚拟化、资源池化、异构资源调度、应用框架支持的成熟,异构硬件的算力也能通过 Serverless 的方式释放,大幅降低用户使用门槛。
后记
2009 年,UC Berkeley 发表了一篇著名的论文 “Above the Clouds: A Berkeley View of Cloud Computing”,讨论了云及其价值、挑战和演进路径,其中的真知灼见在云的十年发展历程中陆续被验证,今天已没有人怀疑云的价值和对各行各业深刻的影响。2019 年,他们发表了新的论文,“Cloud Programming Simplified: A Berkeley View on Serverless Computing”,预言 Serverless 将主导下一个十年云的发展,产业的发展是螺旋式上升,Serverless 的诞生和兴起逻辑早已蕴含其中。相信下一个十年,Serverless 将重塑企业创新的方式,帮助云成为社会发展的强大动力。
]]>
作者 | 唐慧芬(黛忻) 阿里云产品专家
导读:毫无疑问,Serverless 能够在效率和成本上给用户带来巨大收益。那具体到落地又应该怎么做呢?本文就给大家详细解读 Serverless 的落地实践。
Serverless 落地企业级应用的挑战
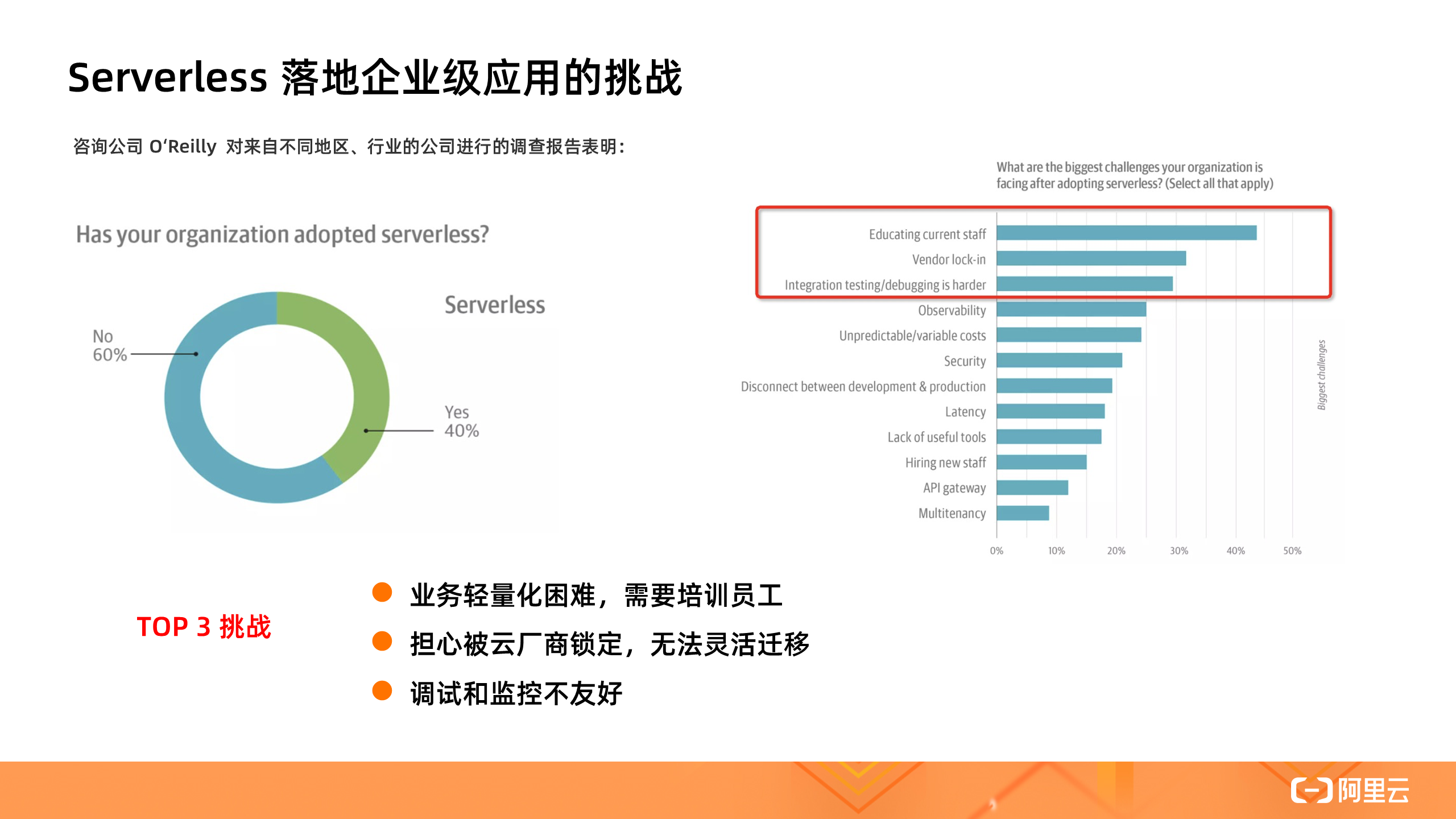
Serverless 技术是继虚拟机、容器之后的第三代通用计算技术。相对于传统后台架构,Serverless 具有免运维、省成本、快速部署交付、灵活弹性等优点,近年来获得越来越多企业和开发者的关注和青睐。但对于企业级应用落地来说,仍存在一些挑战。
根据咨询公司 O ‘Reilly 2019 年底的一份统计报告表明:已有 40% 的组织正在使用 Serverless 技术,剩下的 60% 中认为最大的 TOP 3 挑战是:
- 开发难度和入门门槛高,业务轻量化困难,不能平滑地迁移现有应用 ;
- 担心被云厂商锁定,如 FaaS 形态的 Serverless 产品,每个厂商都希望推出自己的标准,缺乏开源的规范和开源的生态支持。相似的一幕曾经在容器领域上演,直到后来 Kubernetes 成为事实标准,Serverless 还在寻找自己的事实标准;
- 如何方便地本地开发调试、监控,和现有业务做深度整合。
SAE 产品介绍
那么摆在 Serverless 技术落地面前的三座大山该如何解决呢?给大家分享一款低门槛,无需任何代码改造就能直接使用的 Serverless PaaS 平台( SAE ),是企业在线业务平滑上云的最佳选择。
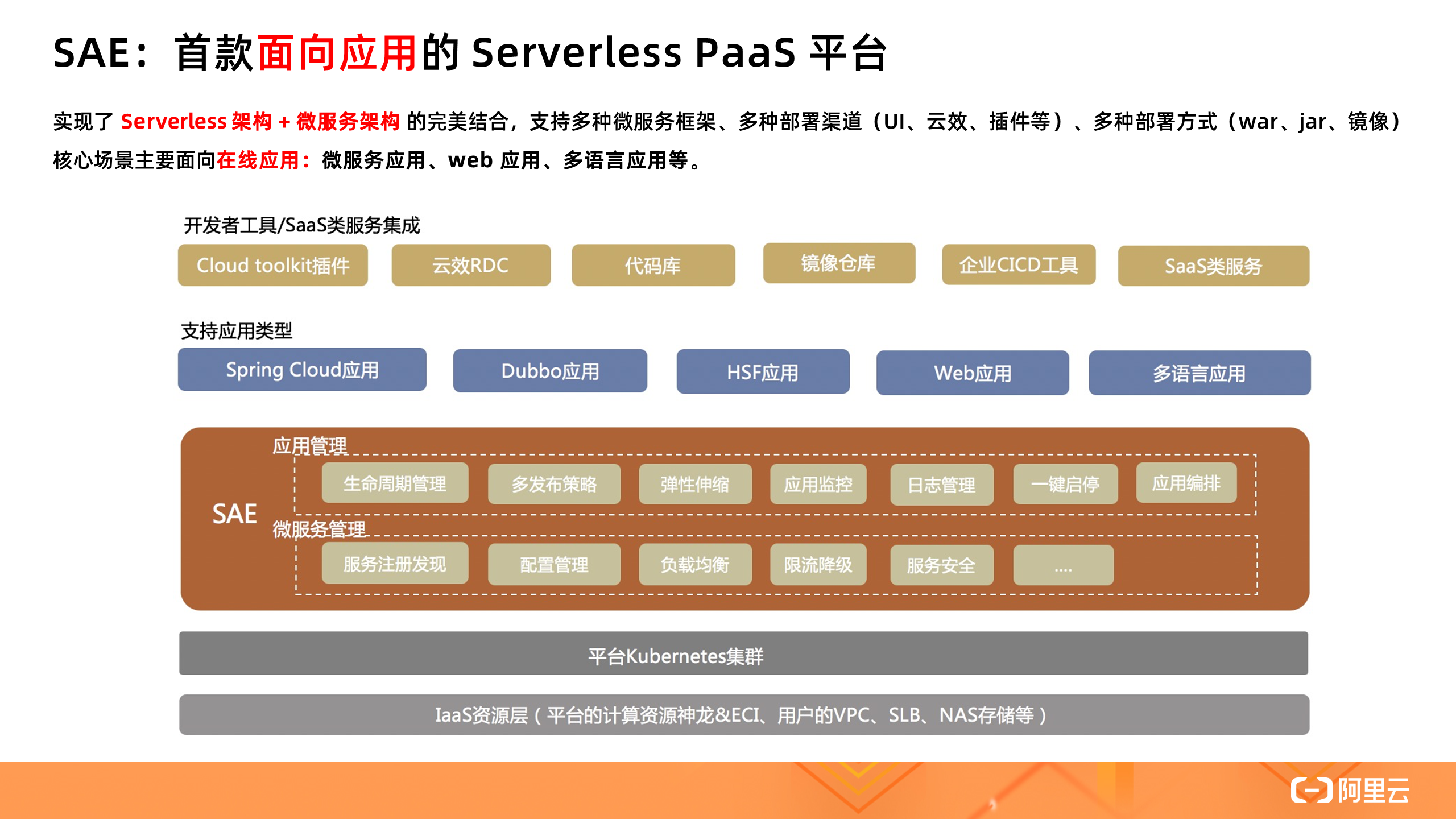
SAE 提供了成本更优、效率更高的应用托管方案。底层基于统一的 K8s 技术底座,帮用户屏蔽复杂的 IaaS 层和 K8s 集群运维,提供计算资源、弹性、隔离性等能力,用户只需关心应用实例的规格和实例数。
在应用层,除提供了生命周期管理、多发布策略外,还提供监控、日志、微服务治理能力,解决应用可观测性和治理需求。同时提供一键启停、应用编排等高级能力,进一步提效和降本。核心场景主要面向在线应用:微服务应用、Web 应用、多语言应用等。
在开发者工具方面,和 CI/CD 工具做了良好的集成,无论是 Jenkins 还是云效,都能直接部署应用到 SAE,也可以通过 Cloud Toolkit 插件工具实现本地一键部署应用到云端,可以说 SAE 覆盖了应用上云的完整场景。

SAE 除了 Serverless 体验本身所带来的极致弹性、免运维、省成本等特性之外,重点在应用层给用户提供了全栈的能力,包括对微服务的增强支持,以及整合了和应用息息相关能力,包括配置、监控、日志、流量控制等。再加上用户零代码的改造,这也是 SAE 区别其它 Serveless 产品的重要优势,平滑迁移企业在线应用。

SAE 有几个典型的使用场景:一个是存量业务上云,特别是微服务、Java 应用,同时也支持其他语言的单体应用快速上云 /搬站,满足极致交付效率和开箱即用的一站式体验。在行业方面,SAE 特别适合有比较大的流量波动的在线业务,比如电商大促、在线教育等行业的场景。另外 SAE 作为应用 PaaS 也可以被上层的行业 SaaS 所集成,帮助用户更快地构建行业 SaaS 。
产品核心指标

SAE 三个核心的指标:容器启动时长 20s (指标定义是从 pull image 到容器启动的耗时,不包括应用启动时间),接下来我们会通过各种技术优化把它优化到 5s 内,保证用户在突发场景下的快速扩容效率。最小规格支持 0.5core 1GiB,满足更细粒度的资源诉求。相比 ECS,SAE 部署一套开发测试环境的成本可以节省 47%~ 57%。
最佳实践
通过前文介绍, 我们了解了产品的特性、优势、适用场景,最后给大家详细介绍几个 Serverless 落地的最佳实践案例。
1. 低门槛微服务架构转型的解决方案
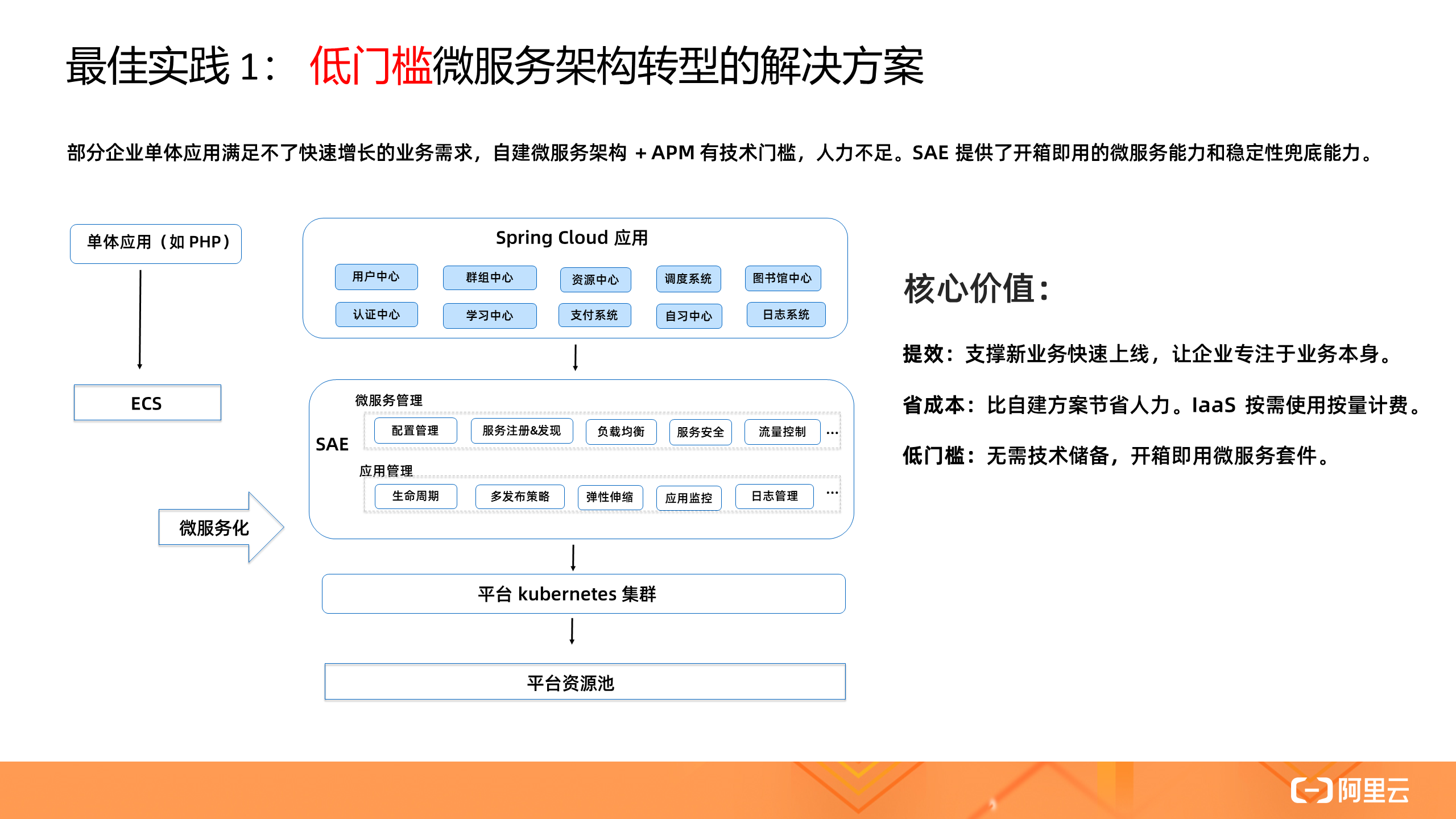
随着业务的快速增长,很多企业都面临单体向微服务架构改造转型的难题,或者开源自建的微服务框架( Spring Cloud / Dubbo )能力不再能满足企业稳定性和多样化的需求。通过 SAE 提供开箱即用的微服务能力和稳定性兜底能力,已让这些企业低门槛快速完成微服务架构转型,支撑新业务快速上线,让企业专注于业务本身。
可以说,SAE 是 Serverless 行业最佳的微服务实践,同时也是微服务行业最佳的 Serverless 实践。
2. 免运维、一键启停开发测试环境的降本方案

中大型企业多套环境,往往开发测试、预发环境都不是 7*24 小时使用,长期保有应用实例,闲置浪费很高,有些企业 CPU 利用率都快接近 0,降本诉求明显。通过 SAE 一键启停能力,让这些企业得以灵活按需释放资源,只开发测试环境就能节省 2/3 的机器成本,非常可观。
3. 精准容量、极致弹性的解决方案
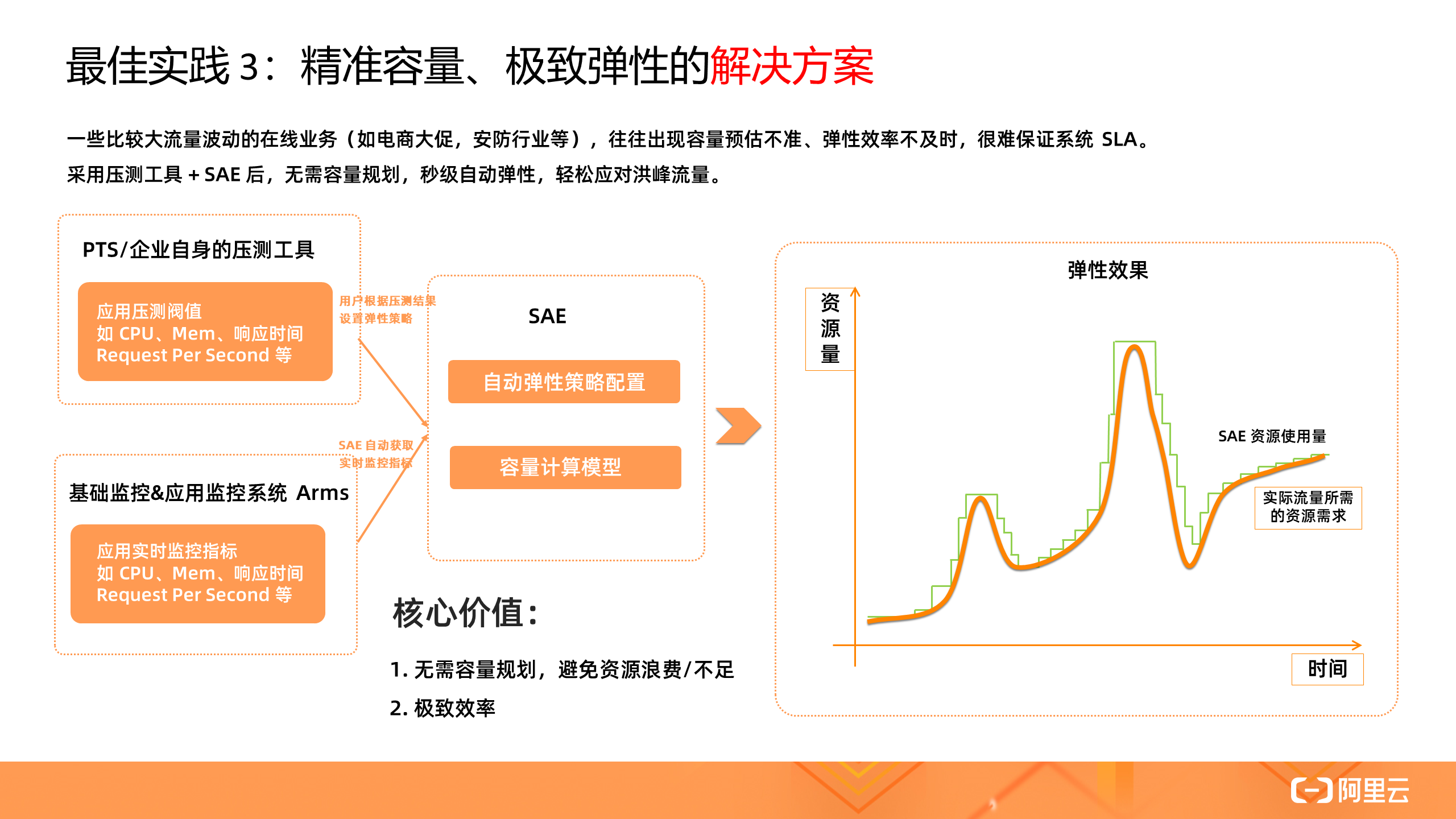
电商类、安防行业等往往会有一些不可预期的突发流量高峰,之前他们都是提前预估峰值,按照峰值保有 ECS 资源,但经常出现容量预估不准(资源浪费 or 不足),更严重的甚至会影响系统的 SLA 。
采用压测工具 + SAE 的方案后,根据压测结果精准设置弹性策略期望值,然后和实时的监控指标比对,系统自动进行扩缩操作,再也无需容量规划,并且弹性效率能做到秒级,轻松应对峰值大考。
4. 构建高效闭环的 DevOps 体系
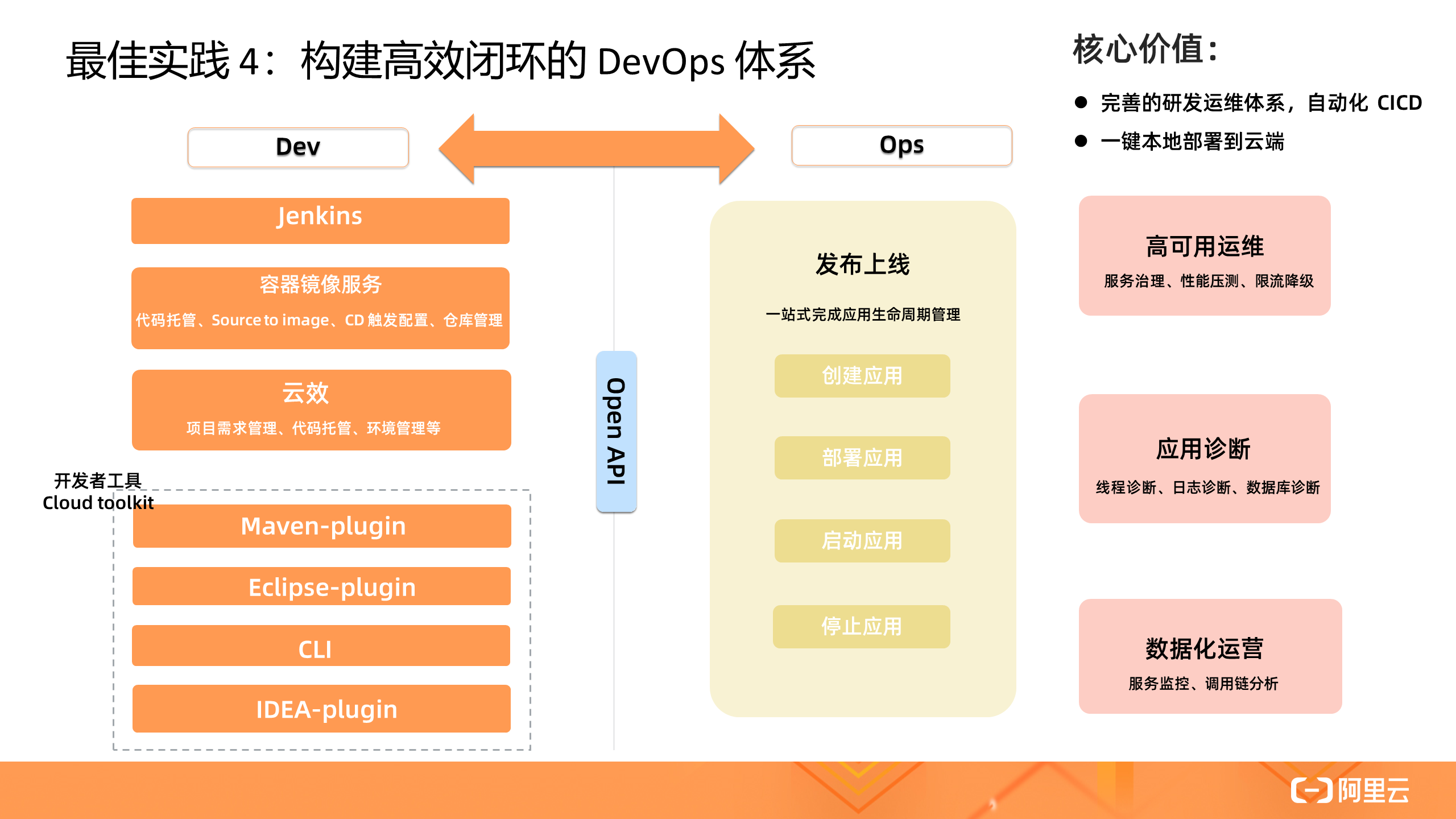
SAE 构建了高效闭环的 DevOps 体系,覆盖了应用的开发态、部署态、运维态的整个过程。中大型企业往往都使用企业级 CI/CD 工具 Jenkis / 云效部署 SAE 应用,完成从 Source Code - 构建 - 部署全链路。中小企业 /个人开发者往往选择开发者工具 Maven 插件、IDEA 插件一键部署应用到云端,方便本地调试,提升开发者体验。完成部署后,即可进行运维态的治理和诊断,如限流降级、应用诊断,数据化运营分析等。
总结
总结一下,本文主要是围绕在线应用的 Serverless 落地实践展开的。开篇提到的几个落地挑战在 SAE 产品中基本都能得到很好的解决:
- 不用修改编程模型,零代码改造,对开发者来说零门槛平滑迁移企业存量应用;
- 底座基于 K8s (容器界的事实标准),上层提供的应用层全栈能力对用户零侵入,因此不用担心厂商锁定问题,而是让用户更关注应用视角,获得一站式 PaaS 层的体验;
- 调试、监控、可观测性方面,SAE 和开发者工具做了良好的集成打通,接下来会越来越逼近开发者熟知的 ECS 运维体验。总体来讲,SAE 是企业在线业务平滑上云的最佳选择。

作者 | 张维(贤维) 阿里云函数计算开发工程师
导读:Serverless Kubernetes 是以容器和 kubernetes 为基础的 Serverless 服务,它提供了一种简单易用、极致弹性、最优成本和按需付费的 Kubernetes 容器服务,其无需节点管理和运维,无需容量规划,让用户更关注应用而非基础设施的管理。我们可以把 Serverless Kubernetes 简称为 ASK 。
Serverless 容器
首先从 Serverless 开始讲起,相信我们已经熟知 Serverless 理念的核心价值,其中包括无需管理底层基础设施,无需关心底层 OS 的升级和维护,因为 Serverless 可以让我们更加关注应用开发本身,所以应用的上线时间更短。同时 Serverless 架构是天然可扩展的,当业务用户数或者资源消耗增多时,我们只需要创建更多的应用资源即可,其背后的扩展性是用户自己购买机器所无法比拟的。Serverless 应用一般是按需创建,用户无需为闲置的资源付费,可以降低整体的计算成本。

以上所讲的几种都是 Serverless 理念的核心价值,也是 Serverless 容器与其他 Sererless 形态的相同之处。然而,Serverless 容器和其他 Serverless 形态的差异,在于它是基于容器的交付形态。
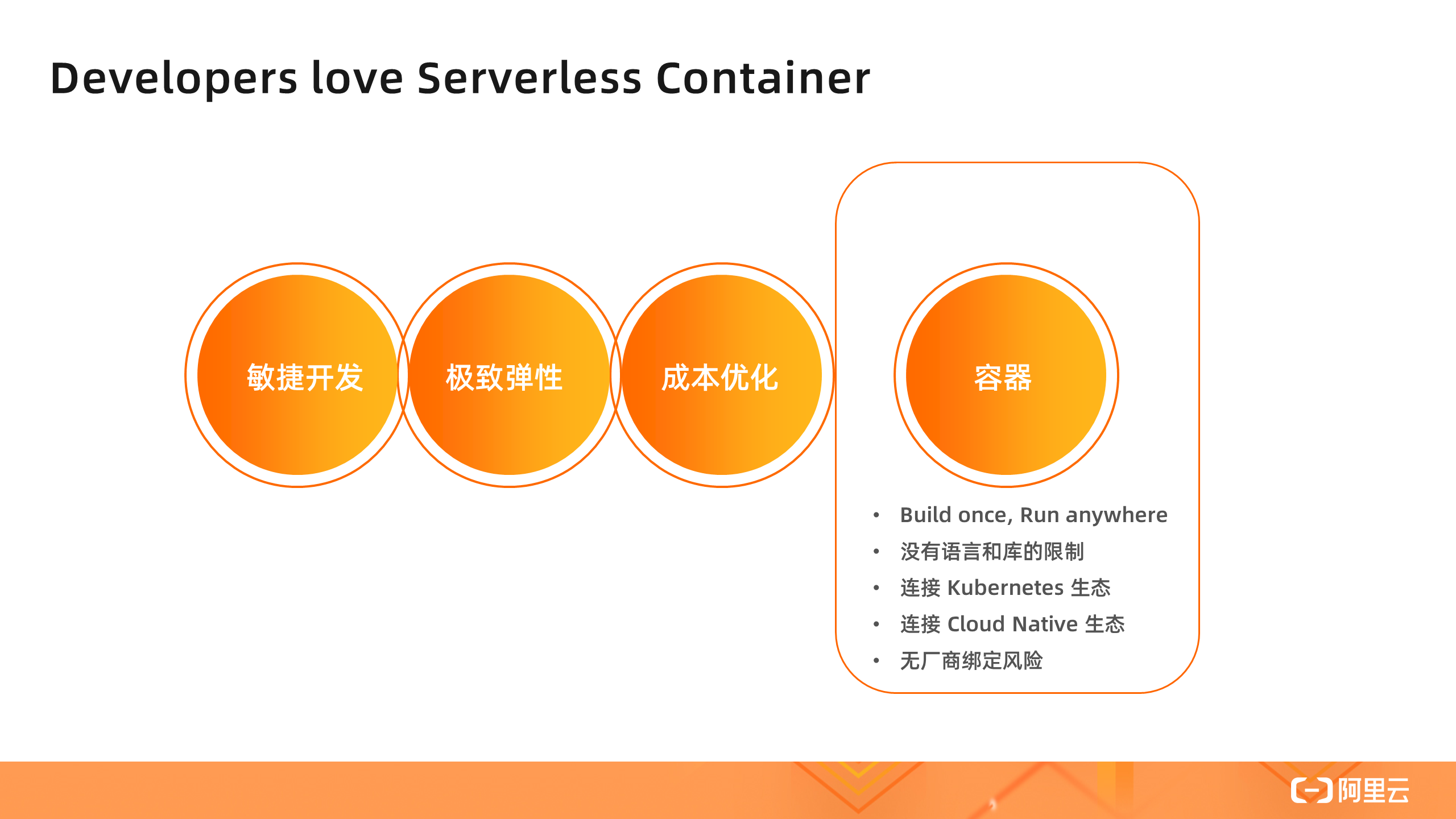
基于容器意味着通用性和标准性,我们可以 Build once and Run anywhere,容器不受语言和库的限制,无论任何应用都可以制作成容器镜像,然后以容器的部署方式启动。基于容器的标准化,开源社区以 Kubernetes 为中心构建了丰富的云原生 Cloud Native 生态,极大地丰富了 Serverless 容器的周边应用框架和工具,比如可以非常方便地部署 Helm Chart 包。基于容器和 Kubernetes 标准化,我们可以轻松地在不同环境中(线上线下环境),甚至在不同云厂商之间进行应用迁移,而不用担心厂商锁定。这些都是 Serverless 容器的核心价值。
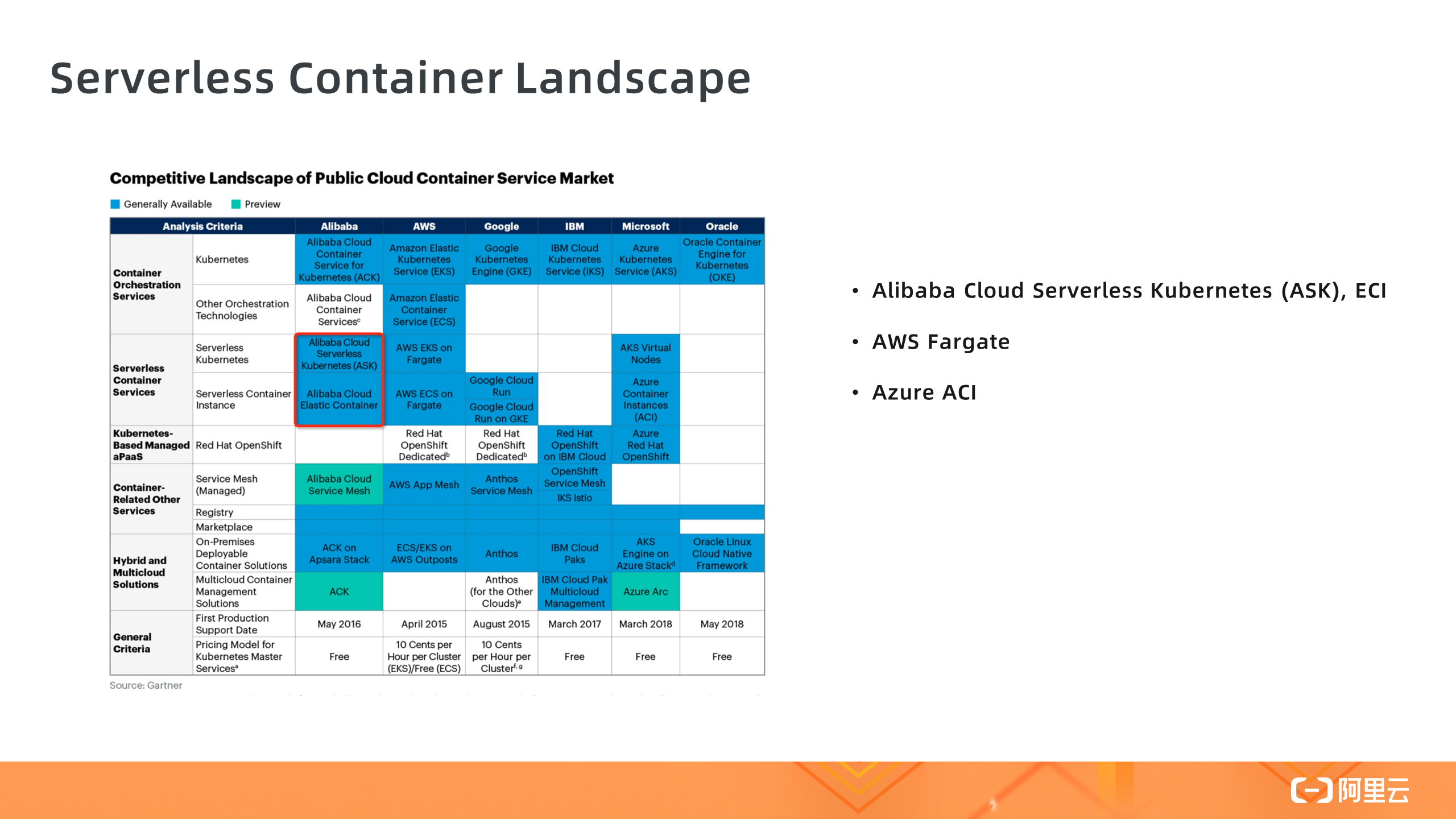 ▲ Serverless 容器产品 Landscape
▲ Serverless 容器产品 Landscape
当下各大云厂商都推出了自己的 Serverless 容器服务,上图为 Gartner 评估机构整理的 Serverless 容器产品 Landscape,其中阿里云有 Serverless Kubernetes ASK 和 ECI ; AWS 有 Fargate,基于 Fargate 有 EKS on Fargate 和 ECS on Fargate 两种形态; Azure 有 ACI 。另外 Gartner 也预测,到 2023 年,将有 70% 的 AI 应用以容器和 Serverless 方式运行。
ASK/ACK on ECI 容器服务
下面介绍阿里云 Serverless 容器产品家族:ECI 、ACK on ECI 和 Serverless Kubernetes 。
1. ECI
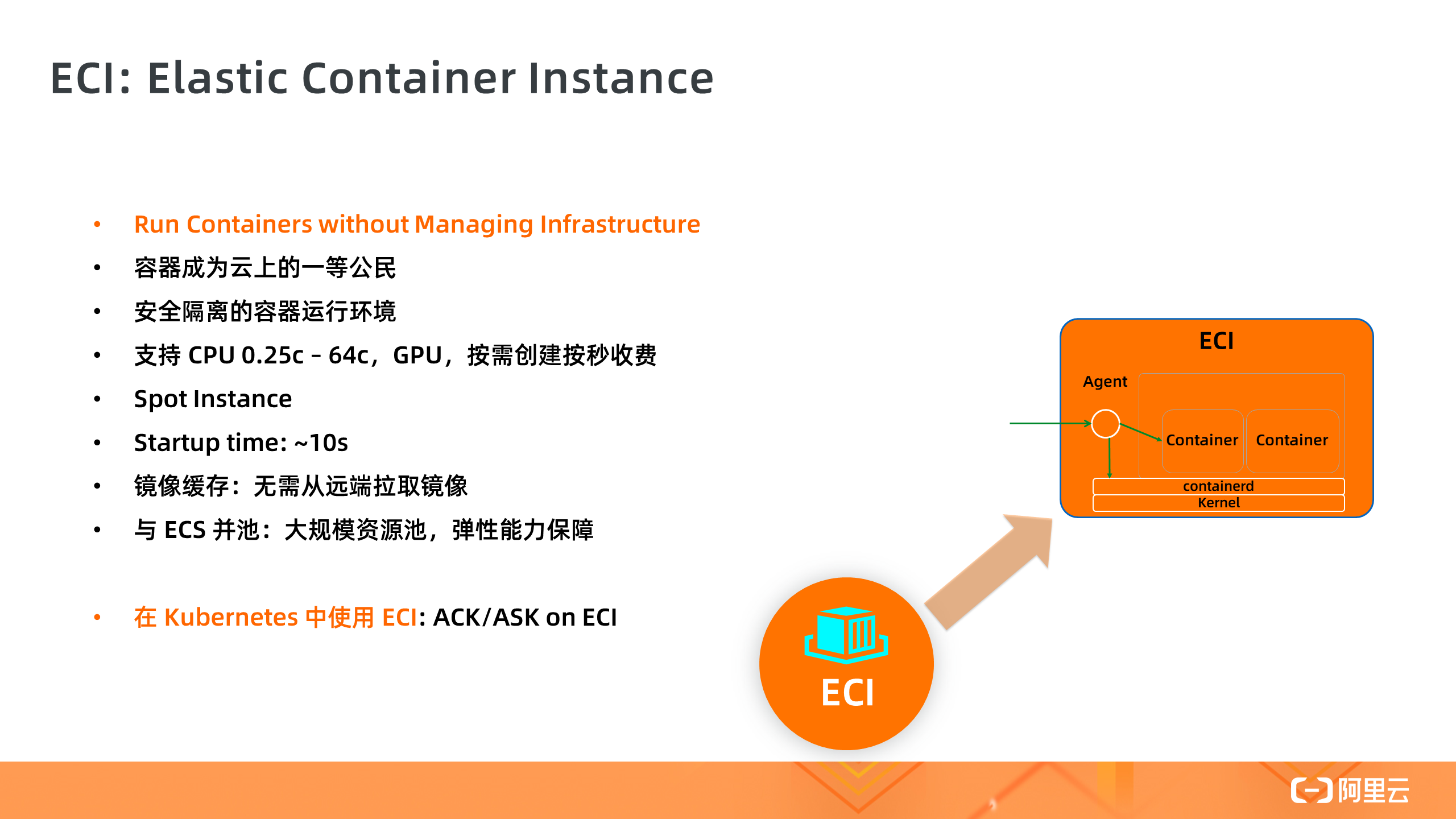
ECI 全称是“Elastic Container Instance 弹性容器实例”,是 Serverless 容器的底层基础设施,实现了容器镜像的启动。ECI 让容器成为和 ECS 一样的云上一等公民。ECI 底层运行环境基于安全容器技术进行强隔离,每个 ECI 拥有一个独立的 OS 运行环境,保证运行时的安全性。ECI 支持 0.25c 到 64c 的 CPU 规格,也支持 GPU,按需创建按秒收费。和 ECS 一样,ECI 也支持 Spot 可抢占式实例,在一些场景中可以节省 90% 的成本。ECI 实例的启动时间目前约是 10s 左右,然后开始拉取容器镜像。我们也提供了镜像快照功能,每次容器启动时从快照中读取镜像,省去远端拉取的时间。值得强调的是,ECI 和 ECS 共用一个弹性计算资源池,这意味着 ECI 的弹性供给能力可以得到最大程度的充分保障,让 ECI 用户享受弹性计算资源池的规模化红利。
ECI 只可以做到单个容器实例的创建,而没有编排的能力,比如让应用多副本扩容,让 SLB 和 Ingress 接入 Pod 流量,所以我们需要在编排系统 Kubernetes 中使用 ECI,我们提供了两种在 Kubernetes 中使用 ECI 的方式。一个是 ACK on ECI,另外一个是 ASK 。
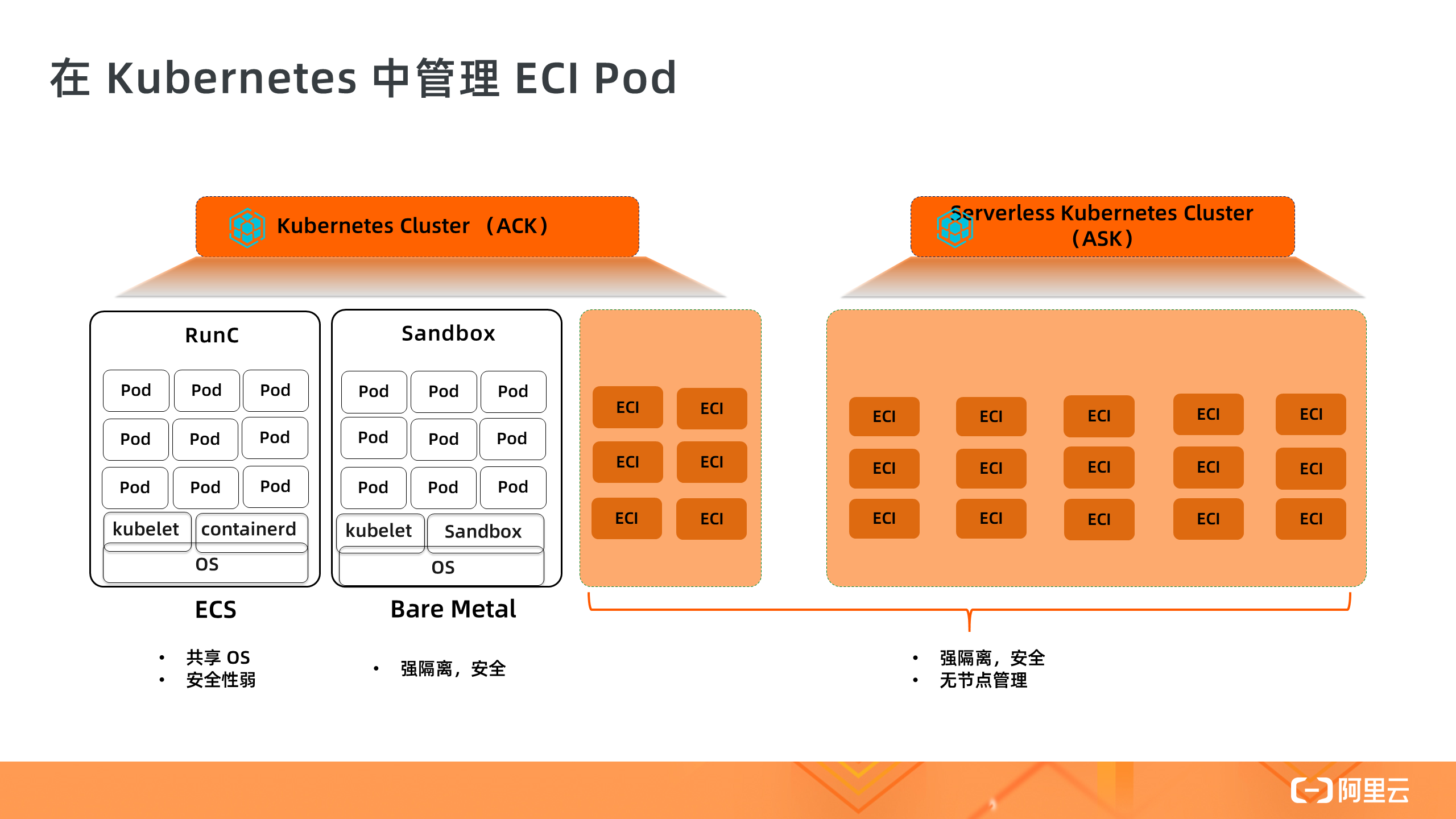
在与 Kubernetes 编排系统的集成中,我们以 Pod 的形式管理每个 ECI 容器实例,每个 Pod 对应一个 ECI 实例,ECI Pod 之间相互隔离,一个 ECI Pod 的启动时间约是 10s 。因为是在 Kubernetes 集群中管理 ECI Pod,所以完全连接了 Kubernetes 生态,有以下几点体现:
- 很方便地用 Kubectl 管理 ECI Pod,可以使用标准的 Kubernetes 的 API 操作资源;
- 通过 Service 和 Ingress 连接 SLB 和 ECI Pod ;
- 使用 Deployment / Statefulset 进行容器编排,使用 HPA 进行动态扩容;
- 可以使用 Proms 来监控 ECI Pod ;
- 运行 Istio 进行流量管理,Spark / Presto 做数据计算,使用 Kubeflow 进行机器学习;
- 部署各种 Helm Chart 。
这些都是使用 Kubernetes 管理容器实例的价值所在。
需要留意的是 Kubernetes 中的 ECI Pod 是 Serverless 容器,所以与普通的 Pod 相比,不支持一些功能(比如 Daemonset ),不支持 Prividge 权限,不支持 HostPort 等。除此之外,ECI Pod 与普通 Pod 能力一样,比如支持挂载云盘、NAS 和 OSS 数据卷等。
2. ACK on ECI
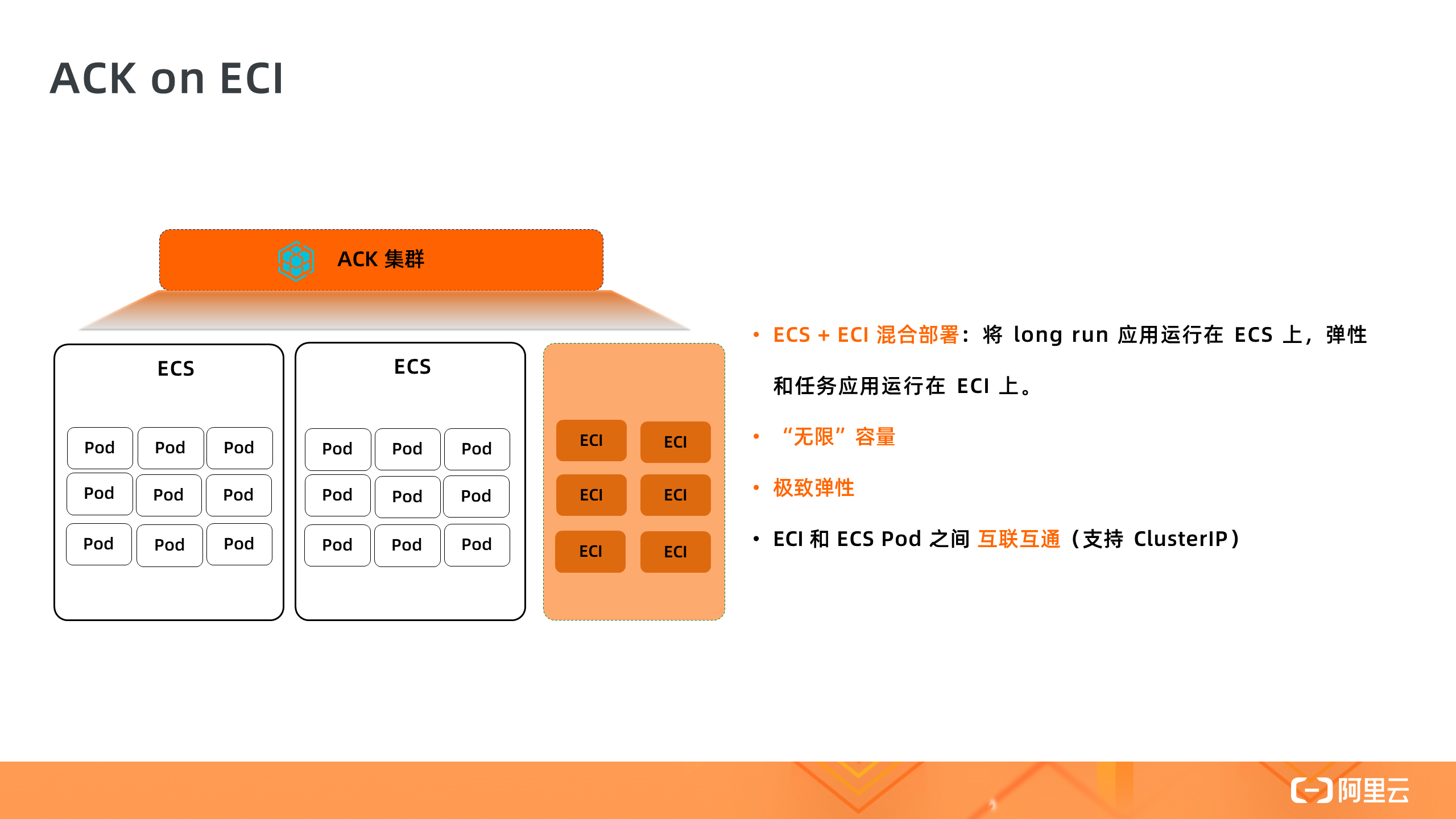
接下来我们看下在 ACK Kubernetes 集群中使用 ECI 的方式。这种方式适合于用户已经有了一个 ACK 集群,集群中已经有了很多 ECS 节点,此时可以基于 ECI 的弹性能力来运行一些短时间 Short-Run 的应用,以解决元集群资源不足的问题,或者使用 ECI 来支撑应用的快速扩容,因为使用 ECI 进行扩容的效率要高于 ECS 节点扩容。
在 ACK on ECI 中,ECS 和 ECI Pod 可以互联互通,ECI Pod 可以访问集群中的 Coredns,也可以访问 ClusterIP Service 。
3. Serverless Kubernetes

与 ACK on ECI 不同的是,ASK Serverless Kubernetes 集群中没有 ECS 节点,这是和传统 Kubernetes 集群最主要的差异,所以在 ASK 集群中无需管理任何节点,实现了彻底的免节点运维环境,是一个纯粹的 Serverless 环境,它让 Kubernetes 的使用门槛大大降低,也丢弃了繁琐的底层节点运维工作,更不会遇到节点 Notready 等问题。在 ASK 集群中,用户只需关注应用本身,而无需关注底层基础设施管理。
ASK 的弹性能力会优于普通 Kubernetes 集群,目前是 30s 创建 500 个 Pod 到 Running 状态。集群中 ECI Pod 默认是按量收费,但也支持 Spot 和预留实例劵来降低成本。在兼容性方面,ASK 中没有真实节点存在,所以不支持 Daemonset 等与节点相关的功能,像 Deployment / Statefulset / Job / Service / Ingress / CRD 等都是无缝支持的。
ASK 中默认的 Ingress 是基于 SLB 7 层转发实现,用户无需部署 Nginx Ingress,维护更加简单。
同时基于 SLB 7 层我们实现了 Knative Serving 能力,其中 Knative Controller 被 ASK 托管,用户无需负担 Controller 的成本。
与 ACK 一样,ASK 和 Arms / SLS 等云产品实现了很好的集成,可以很方便地对 Pod 进行监控,把 Pod 日志收集到 SLS 中。
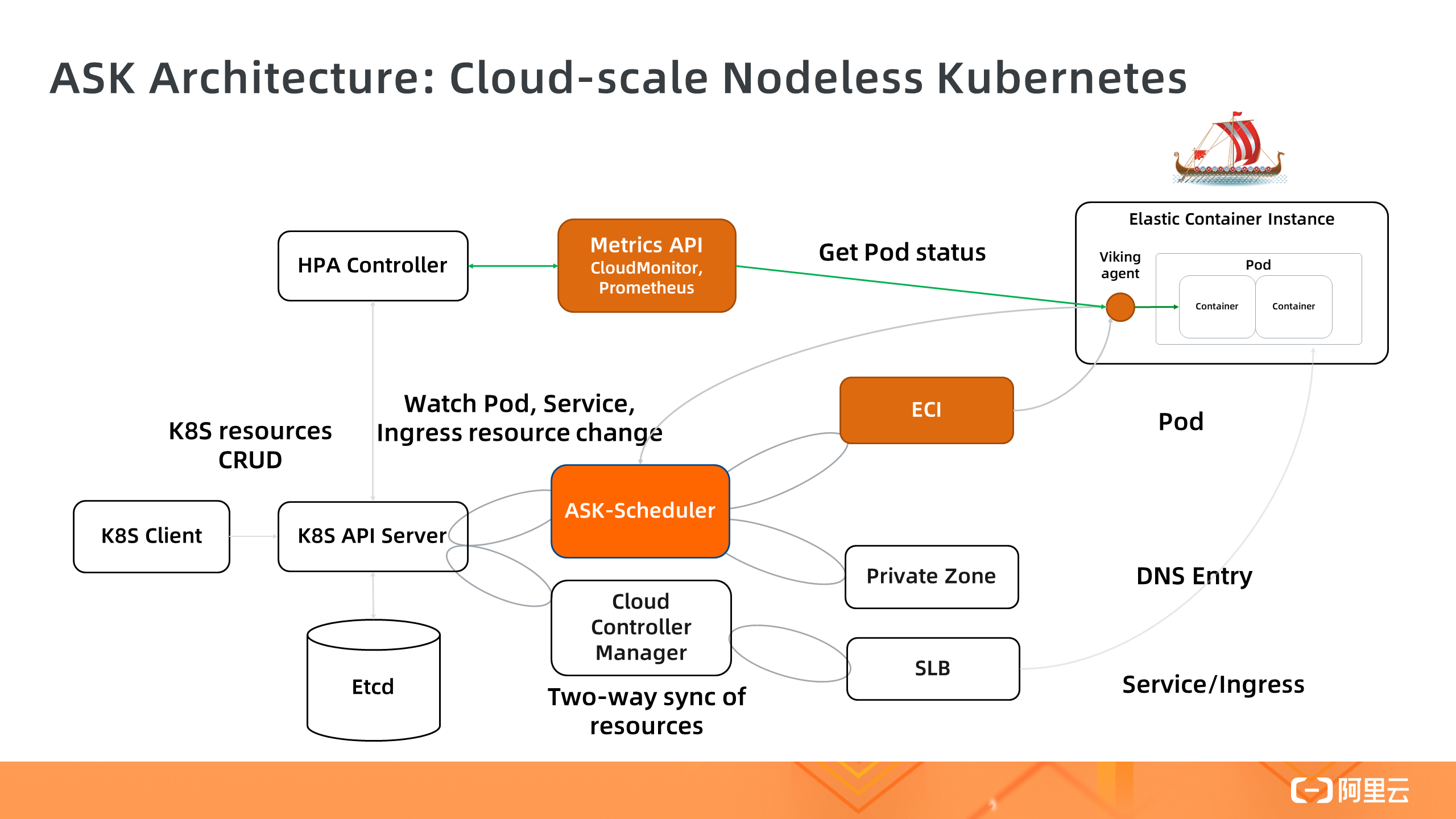
这是 ASK 的整体架构,核心部分是 ASK-Schduler,它负责 Watch Pod 的变化,然后创建对应的 ECI 实例,同时把 ECI 实例状态同步到 Pod 。集群中没有真实 ECS 节点注册到 Apiserver 。这个 Nodeless 架构解耦了 Kubernetes 编排层和 ECI 资源层,让 Kubernetes 彻底摆脱底层节点规模导致的弹性和容量限制,成为面向云的 Nodeless Kubernetes 弹性架构。
ASK 典型功能
下面介绍 ASK 的几个典型功能:
1. GPU 实例
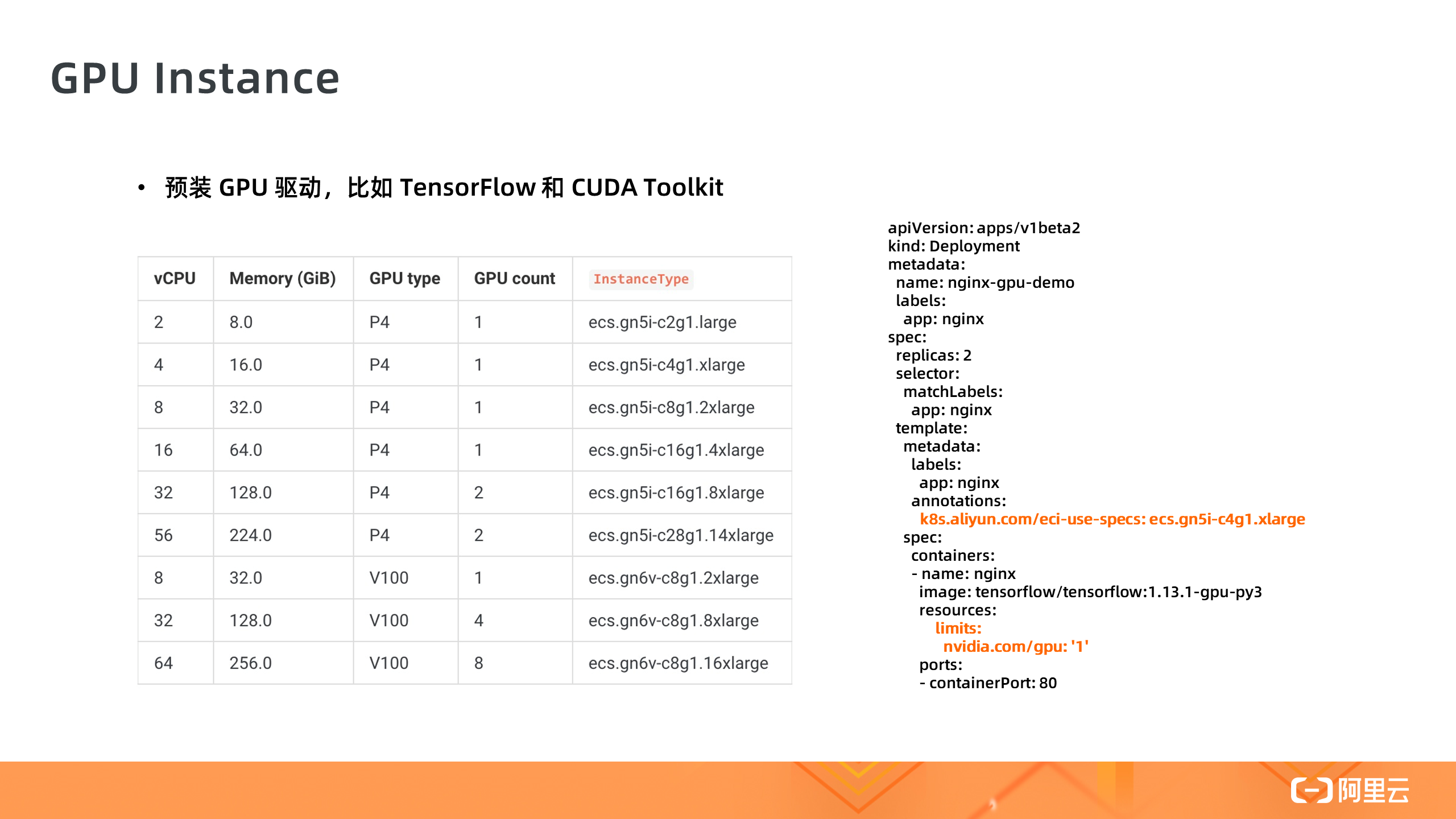
第一个是 GPU 实例,在 Serverless 集群中使用 GPU 容器实例是一件非常简单的事情,不需要安装 GPU 驱动,只需要指定 GPU Pod 规格,以及容器需要的 GPU 卡数,然后就可以一键部署,这对于机器学习场景可以极大提高开发和测试的效率。
2. Spot 抢占式实例

第二个是 Spot 抢占式实例。抢占式实例是一种按需实例,可以在数据计算等场景中降低计算成本。抢占式实例创建成功后拥有一小时的保护周期。抢占式实例的市场价格会随供需变化而浮动,我们支持两种 Spot 策略,一种是完全根据市场出价,一种是指定价格上限,我们只需要给 Pod 加上对应的 Annotation 即可,使用方法非常简单。
3. 弹性负载 Elastic Workload
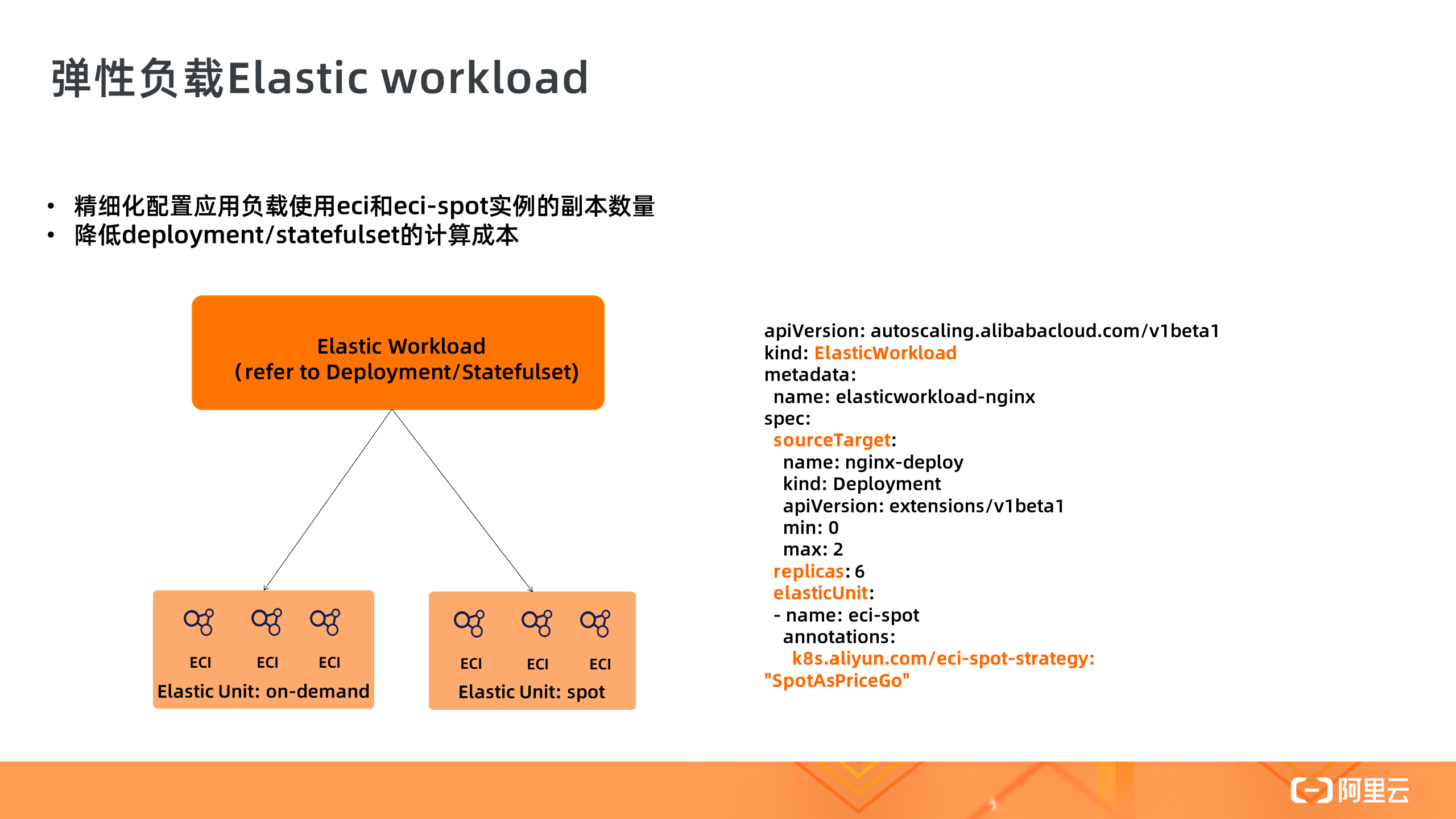
第三个重要功能是弹性负载 Elastic Workload,弹性负载实现了 Deployment 多个副本调度在不同的单元上,比如 ECS 、ECI 和 ECI-Spot 上,通过这种混合调度的模式,可以降低负载的计算成本。在这个示例中,Deployment 是 6 个副本,其中 2 个为正常的 ECI Pod,其他副本为 ECI-Spot 实例。
ASK 使用场景
上面我们已经对 Serverless Kubernetes 做了基本的产品和功能介绍,那么 ASK 适合在哪些场景中使用呢?
1. 免运维应用托管
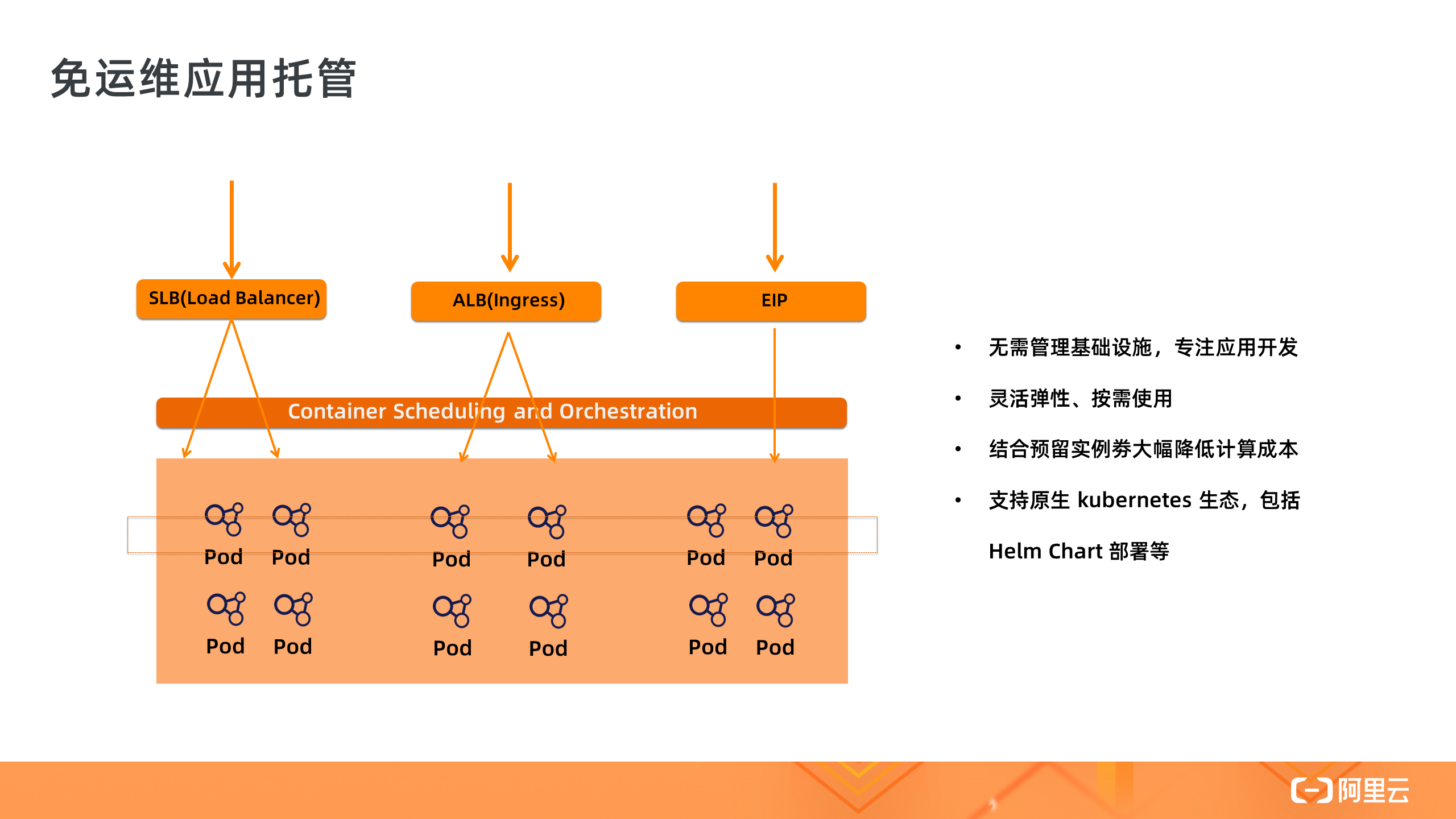
Serverless 集群最大的特点是解决了底层节点资源的运维问题,所以其非常适合对应用的免运维托管,让用户关注在应用开发本身。在传统 K8s 集群中的应用可以无缝部署在 Serverless 集群中,包括各种 Helm Chart 。同时结合预留实例劵可以降低 Pod 的长计算成本。
2. ECI 弹性资源池
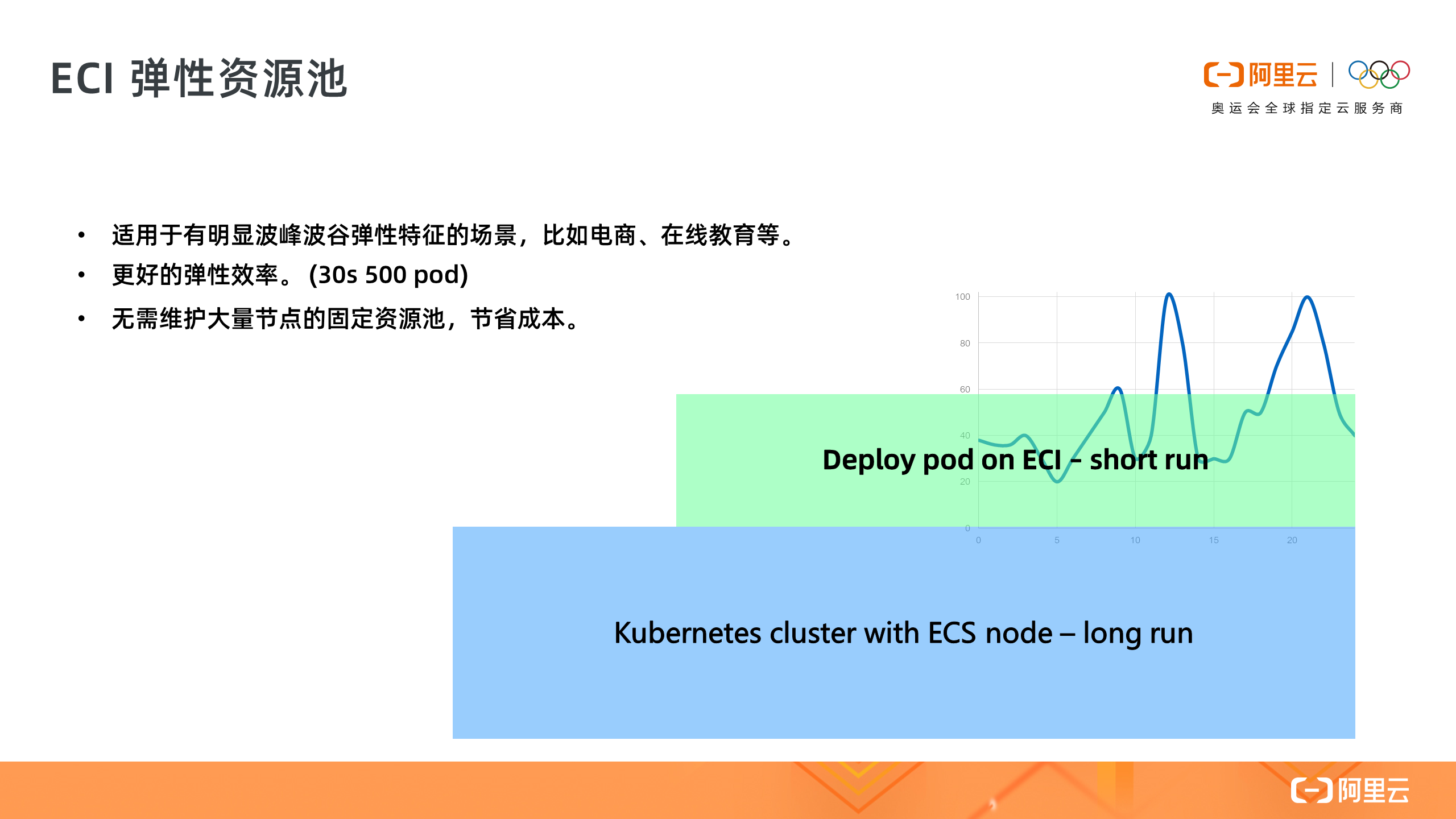
第二个场景是 ACK on ECI 的优势,我们可以选择把 ECI 作为弹性资源池,加到已有的 Kubernetes 集群中,当应用业务高峰来临时,通过 ECI 动态灵活地扩容,相比 ECS 节点扩容更有效率,这种比较适合电商或者在线教育这类有着明显波峰波谷的业务场景,用户无需管理一个很大的节点资源池,通过 ECI 弹性能力来降低整体计算成本。
3. 大数据计算
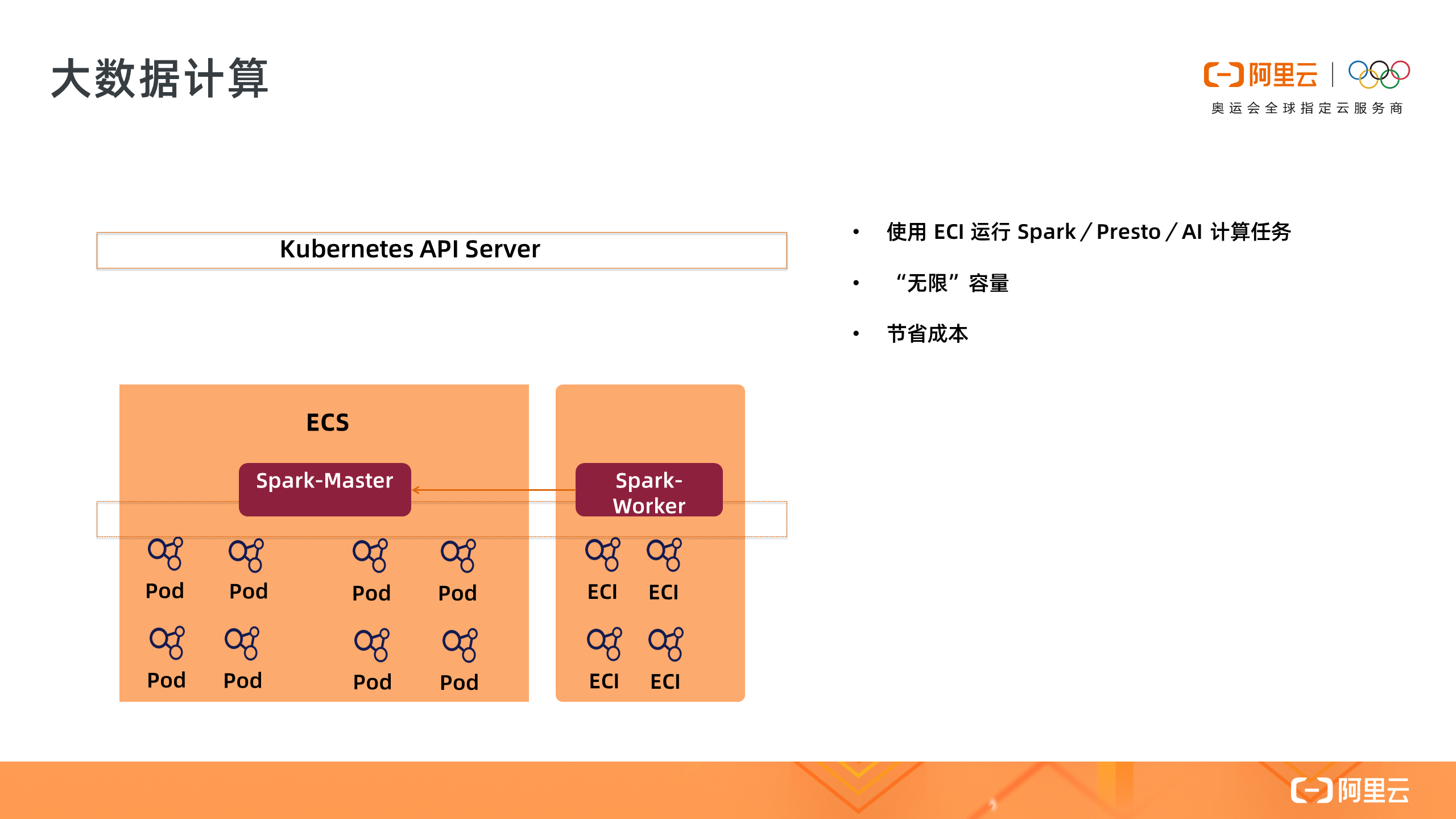
第三个场景是大数据计算,很多用户使用 Serverless 集群或者 ACK on ECI 来进行 Spark / Presto / AI 等数据计算或者机器学习,利用 ECI 可以轻松解决资源规划和不足的问题。
4. CI/CD 持续集成
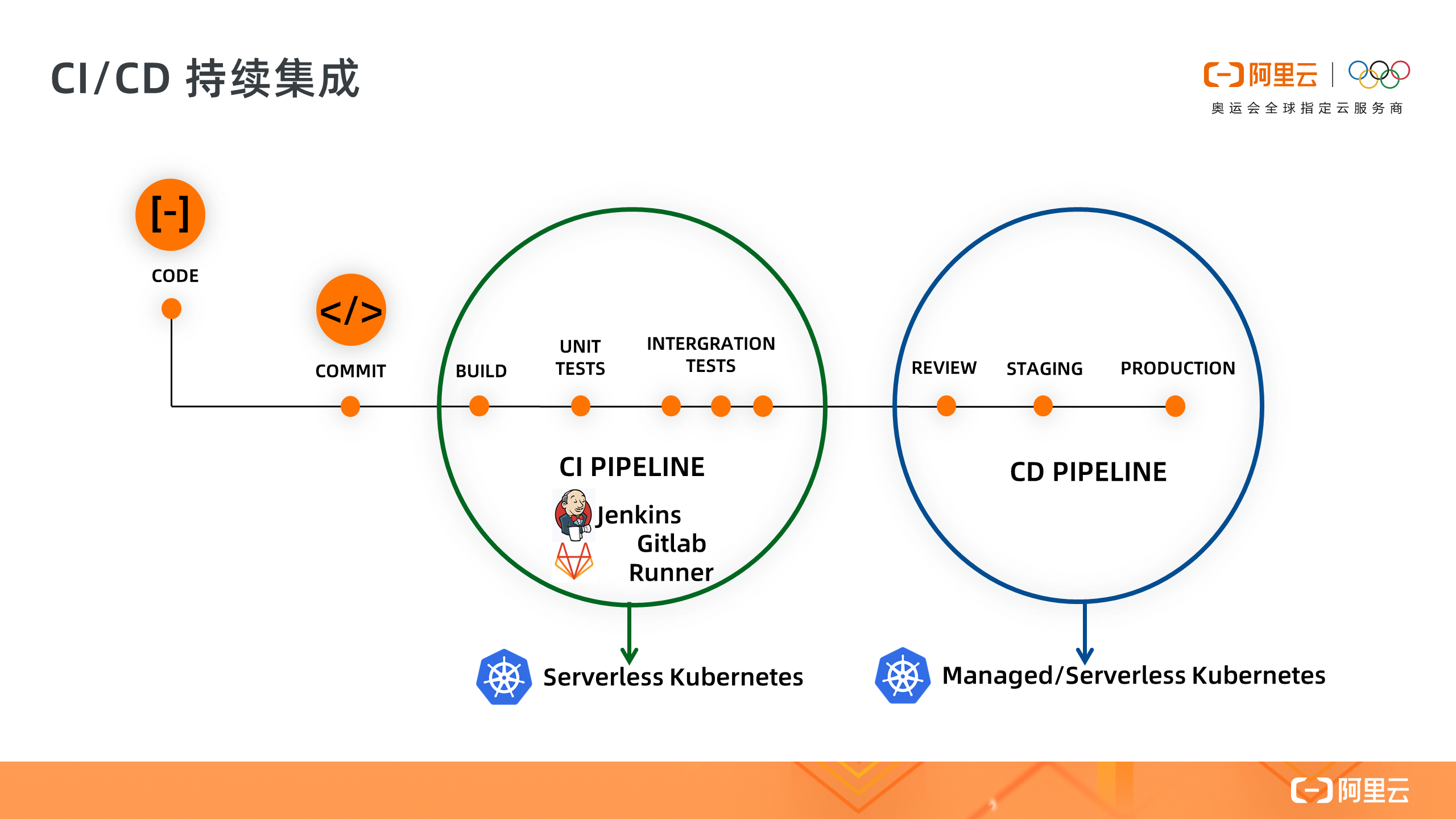
第四个场景是 CI/CD 持续集成,将 Jenkins 和 Gitlab-Runner 对接 ASK 集群,按需创建 CI/CD 构建任务,构建完成后直接部署到 ASK 测试环境进行验证,这样我们无需为 Job 类任务维护一个固定资源池,按需创建极大降低成本,另外如果结合 Spot 实例还能进一步降低成本。
以上就是 Serverless Kubernetes 集群的典型场景,另有快速使用链接、产品文档以及使用示例,供大家学习:
控制台: https://cs.console.aliyun.com/ask 产品文档: https://www.alibabacloud.com/help/doc-detail/86366.htm 示例: https://github.com/AliyunContainerService/serverless-k8s-examples
]]>
Github:https://github.com/midwayjs/midway
开源为了前端和 Node.js 的发展,点 Star!
去年阿里提出 Serverless 架构,并利用其新一代研发架构,减少了大量研发人员对基础设施和运维的关注。对前端开发者而言,他们只需写几个函数即可实现后端业务逻辑,推动业务快速上线,让整个前端研发效能提升 50%。
在过去的半年里,Midway FaaS 收获了很多同学的关注,也有不少大企业已经直接开始使用,在此感谢你们。今天,Midway FaaS 将演进为 Midway Serverless,并正式成为 Midway 体系的核心场景,同时正式发布 v1.0 版本。
v1.0 版本代表着一个正式的版本,可以放心的使用。通过整个 Midway Serverless 新体系,我们将阿里的 Serverless 能力逐步开放,前端将进入一个崭新的时代。就像两年前说的一样,开源只是开始,终态远没有到来。
如今的 Serverless,是云厂商各自开疆拓土的黄金时代,也是各位尝试的最好年代,如今 Node.js 在这个时候成为了最佳选择,Midway 体系也当仁不让地站在这十字路口,去朝着引领的方向去行。
什么是 Midway Serverless
就像前面提到的一样,Midway Serverless 是套面向 Serverless 的解决方案,它包括框架,运行时,工具链,配置规范几个部分,这几部分的组合之后,提供了一些面向 Serverless 体系的特有能力:
1. 平台间迁移更容易
- 通过提供统一的配置规范以及入口抹平机制,让代码在每个平台基本相同;
- 扩展不同云平台的运行时 API,不仅能加载通用的平台间扩展,也能接入公司内部的私有化部署方案。
2. 让应用更易维护和扩展
- 提供了标准的云平台函数出入参事件定义;
- 提供了多套和社区前端 React 、Vue 等融合一体化开发的方案;
- 使用了 TypeScript 作为基础语言,方便应用扩展和定义;
- 提供了完善的 Midway 体系标志性的依赖注入解决方案。
3. 生态更轻量和自由
- 函数体系复用 koa 的生态和 Web 中间件能力,在处理传统 Web 时更加得心应手;
- 提供 egg 组件复用 egg 插件的生态链,企业级开发链路更简单顺畅;
- Midway 体系的装饰器能力统一,让传统 Web 迁移到 Serverless 体系更快更好。
上面提到的全部能力,都已经在 Midway Serverless 仓库开源,欢迎跳转点 Star。
Github:https://github.com/midwayjs/midway
Serverless 和 FaaS
FaaS 是 Serverless 架构的其中一种形态,也是这一次 Midway 希望解决的场景,在 v1.0 之前,我们在 FaaS 上投入了许多,但是事实上 Serverless 架构非常庞大,FaaS 只是其中的一小部分,基于事件驱动的模型,从微服务( MicroService )这种专注于单一职责与功能的小型功能块演进而来。如今这种更加“代码碎片化”的软件架构范式,相比微服务更加细小的程序单元,给业务代码提供了无与伦比的灵活性。
今天按照《福布斯》杂志的统计,在商业和企业数据中心的典型服务器仅提供 5%~ 15% 的平均最大处理能力的输出,这无疑是一种资源的巨大浪费。而随着 Serverless 架构的出现,让服务提供商提供我们的计算能力最大限度满足实时需求,这将使我们能更有效地利用计算资源。
弹性容器,能够满足当前的对资源利用全部憧憬,也是云平台不断追求的目标之一,而对于开发者,不管是弹性的容器,还是弹性的函数,只要有一套代码能都运行其中,满足业务的需求即可。Midway Serverless 的目标由此而来,从原来的 FaaS 场景开拓到了其他领域,不管是函数还是新的架构,我们都将一一满足,并落地业务、反哺社区。
防平台锁定
Vendor Lock-in 是每个使用云平台的的人都会拷问灵魂的问题,Midway Serverless 一开始的初衷就是让一套代码能够运行在不同的平台和运行时之上,我们不建议在不了解全貌时去自定义运行时,那非常的危险。事实上,官方的运行时是运行最稳定,也一定是性能最好的,所有的基准跑分都是基于此。
我们了解的大多数企业在面对 Serverless 的第一个问题就是,我的代码是不是一定得绑死到阿里云,或者腾讯云,AWS 等等。
面对这个问题,Midway Serverless 提供了一套 “隐藏式” 入口加上通用化定义来解决这个问题。
针对每个平台,Midway Serverless 提供了不同的运行时启动器,用于抹平各个平台的差异,并且通过这些启动器,将各个平台的出入参,以及各个 event 结构,网关的返回格式进行规则化,让用户尽可能不感知底层容器以及协议的差异。

除此之外,Midway Serverless 提供了一套 Spec 定义,来抹平多个平台的差异,同时也能方便的在多个平台间复用相同的工具链和函数逻辑。
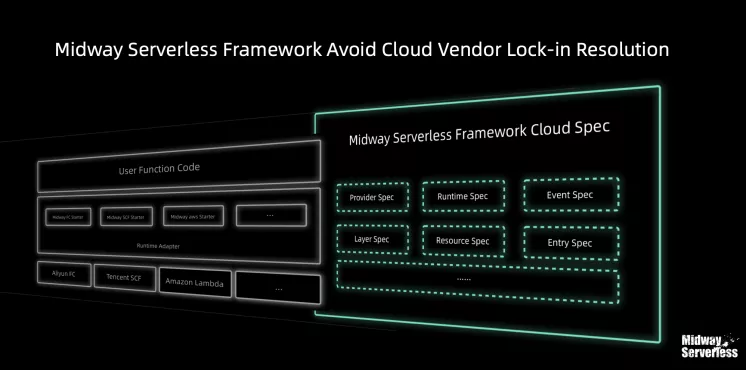
这样,不管是 API Gateway,还是普通的 HTTP 触发器,都能在统一的编程平面中提供 API,让编写代码变的简单。
TS 与装饰器
函数的写法是十分灵活的,灵活带来了简便,同时也带来了维护成本。由此在函数中引入了 TS,引入了标准和扩展性。
下面的代码,看起来似乎是 koa 的标准语法,其实是函数中面向 HTTP 触发器的 API,为了和 Web 栈语法保持一致,通过一些转变,使得参数的获取,调用都尽可能无缝衔接,也减少了学习的成本,原有的代码也能更好的迁移过来。
另一边,通过装饰器修饰的方法都将变为函数入口,让整个函数的结构变得自由。通过构建的方式,让真实的入口隐藏起来,不仅让函数跨多个平台调用,也可以适配到不同的路由。如上面的示例,在一个文件中入口有多个,可以共享同一份代码,但是实际上每个函数的调用又是独立的,在管理和后期维护上都提供了便利。
不同云平台的实际结构是不同,如果用户需要使用到传统的 event 、context 结构, 我们也给不同平台触发器提供了不同的定义,方便代码编写,如下图。
复用社区生态
上面提到,Midway Serverless 体系的设计的初衷就是复用现有 koa 生态,将多个平台的底层 event 规则化成统一的类 koa API 。API 相似的目的是为了整个 koa 的 web 生态,我们同时也希望整个 koa 的 middleware 生态都可以复用。如下图,引入了 @koa/cors 。
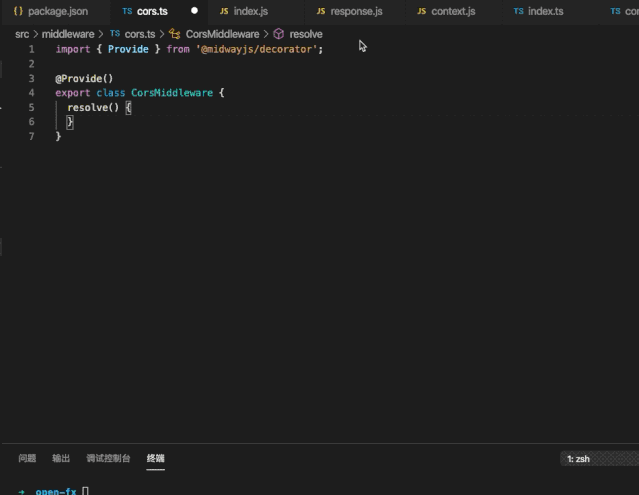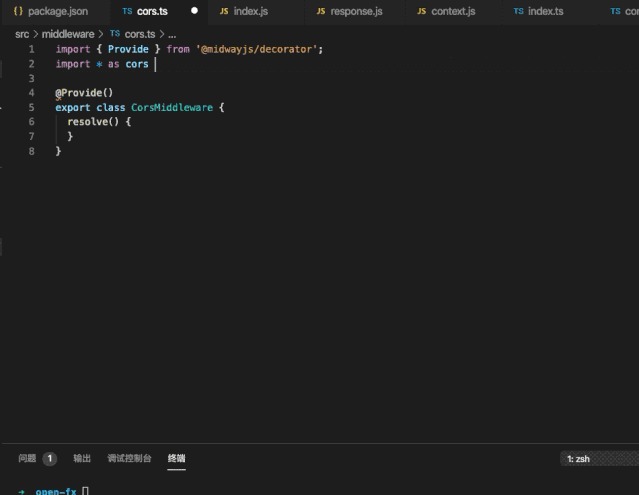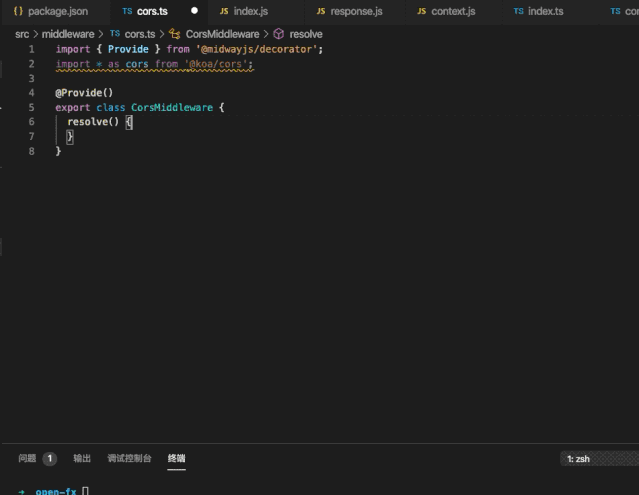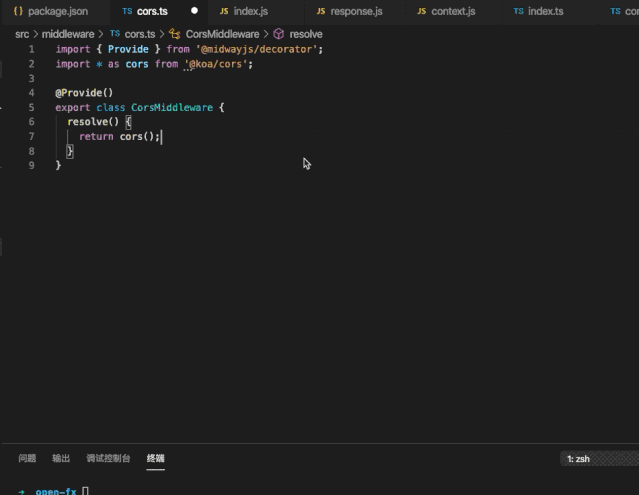
另一面,Midway 由于出色的 IoC 组件化能力,提供了上层的 egg 基础组建,同时也能复用现有的 egg 插件,让传统企业级开发的能力得以延续,比如下图就是使用 egg-mysql 插件的示例。
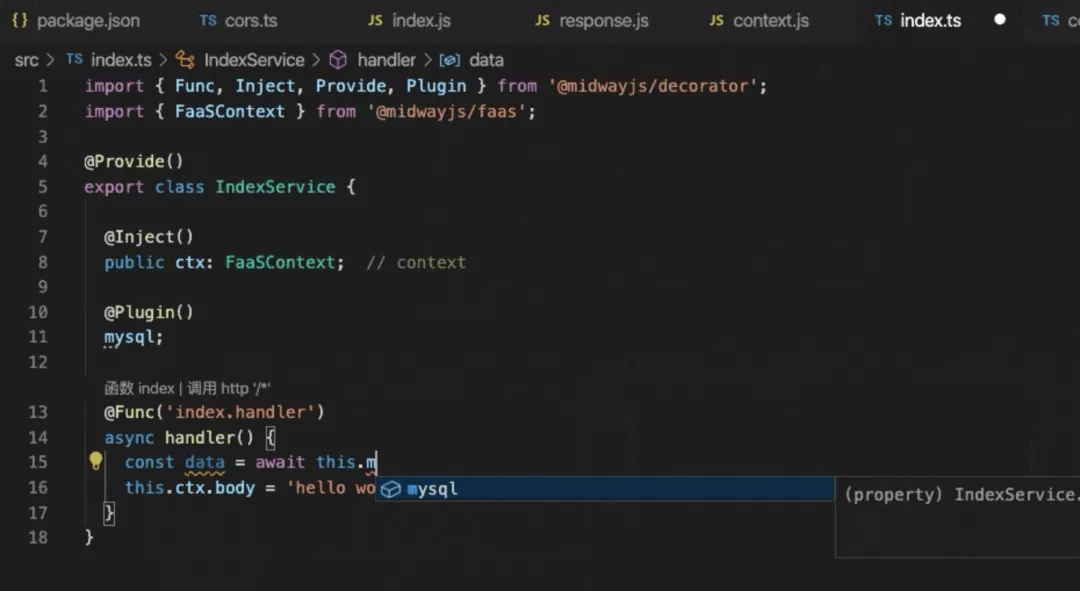
前端赋能
云 + 端的开发体验是 Midway Serverless 目标之一,传统应用的开发,前端和后端分离,多仓库开发,部署分离。就算使用了 Node.js 的胶水层,也无法避免人员开发体感上的割裂。而在 Serverless 体系下,这不是什么问题。
由于后端的大幅简化,再加上云服务的 BaaS 化,让数据聚合,页面渲染变得更容易,也能更快地让前端上手和开发。
一体化慢慢成为了这一块的前端诉求,所谓的一体化,不仅仅是传统仓库的融合,也是整个开发模式的演进,从工程体系加上代码,CI/CD 的整套体系重塑的机会。
如今的 Midway Serverless,提供了和前端一体的开发方案,囊括了社区现有的 React 、Vue 等生态,也对整个工具链( Webpack 、ice scrips 、umi 等)做了定制化方案,对不同的场景,比如博客等也提供了开箱即用的解决方案。

至于详细的前后端一体化能力,我们后续将单独开一篇文章来介绍前端一体化的细节和思考。
应用和函数
Serverless 是未来一段时间的方向,也是前端迈向更高层次的铺路砖。
之前一直在思索,如今的函数式开发的终态和应用的关系到底是什么?
现阶段,我们的答案是趋于统一,在被无数次的灵魂拷问和用户需求的追问中,我们得出了这个答案,函数即是应用在当前业务中的最小体现,更简单的来说,是在最小规格容器中运行应用的部分代码。
之后的一段时间,我们将聚焦于更多平台的接入,以及传统应用的迁移方案上,让之前的用户也能享受到 Serverless 弹性的红利,让企业成本更低,业务上线更容易。
最后
在集团大中台、小前端业务架构日趋深化的背景下,借助集团云原生 Serverless 的发展,去年 Node.js 在业务端到端交付场景上看到了未来。
新一代云 + 端的前台业务交付模式逐渐成为现实,这可以帮助技术团队塑造有业务整体交付能力的特种兵,帮助业务快赢。但其路漫漫仍诸多不完善,为了尽早达到这一步,需要高度聚焦在两个核心问题上:规模化成本和交付速度。
期望在未来透过我们对规模化成本、交付速度的持续投入,Node.js/Serverless 体系可以体现出全面的先进性。Midway Serverless,Go!
]]>
作者 | 不瞋
导读:用户需求和云的发展两条线推动了云原生技术的兴起、发展和大规模应用。本文将主要讨论什么是云原生应用,构成云原生应用的要素是什么,什么是 Serverless 计算,以及 Serverless 如何简化技术复杂度,帮助用户应对快速变化的需求,实现弹性、高可用的服务,并通过具体的案例和场景进行说明。
如今,各行各业都在谈数字化转型,尤其是新零售、传媒、交通等行业。数字化的商业形态已经成为主流,逐渐替代了传统的商业形态。在另外一些行业里(如工业制造),虽然企业的商业形态并非以数字化的形式表现,但是在数字孪生理念下,充分利用数据科技进行生产运营优化也正在成为研究热点和行业共识。
企业进行数字化转型,从生产资料、生产关系、战略规划、增长曲线四个层面来看:
- 生产资料:数据成为最重要的生产资料,需求 /风险随时变化,企业面临巨大的不确定性;
- 生产关系:数据为中心,非基于流程和规则的固定生产关系,网络效应令生产关系跨越时空限制,多连接方式催生新的业务和物种;
- 战略规划:基于数据决策,快速应对不确定的商业环境;
- 增长曲线:数字化技术带来触达海量用户的能力,可带来突破性的增长。
从云服务商的角度来看云的演进趋势,在 Cloud 1.0 时代,基础设施的云化是其主题,采用云托管模式,云上云下的应用保持兼容,传统的应用可以直接迁移到云上,这种方式的核心价值在于资源的弹性和成本的低廉;在基础设施提供了海量算力之后,怎么帮助用户更好地利用算力,加速企业创新的速度,就成为云的核心能力。
如果仍在服务器上构建基础应用,那么研发成本就会很高,管理难度也很大,因此有了 Cloud 2.0,也就是云原生时代。在云原生时代,云服务商提供了丰富的托管服务,助力企业数字化转型和创新,用户可以像搭积木一样基于各种云服务来构建应用,大大降低了研发成本。
云原生应用要素
云原生应用有三个非常关键的要素:微服务架构,应用容器化和 Serverless 化,敏捷的软件交付流程。
1. 微服务架构
单体架构和微服务架构各有各的特点,其主要特点对比如下图所示。总的来说,单体架构上手快,但是维护难,微服务架构部署较难,但是独立性和敏捷性更好,更适合云原生应用。

▲ 单体架构 VS 微服务架构
2. 应用容器化和 Serverless 化
容器是当前最流行的代码封装方式,借助 K8s 及其生态的能力,大大降低了整个基础设施的管理难度,而且容器在程序的支撑性方面提供非常出色的灵活性和可移植性,越来越多的用户开始使用容器来封装整个应用。 Serverless 计算是另外一种形态,做了大量的端到端整合和云服务的集成,大大提高了研发效率,但是对传统应用的兼容性没有容器那么灵活,但是也带来了很大的整洁性,用户只需要专注于业务逻辑的编码,聚焦于业务逻辑的创新即可。
3. 敏捷的应用交付流程
敏捷的应用交付流程是非常重要的一个要素,主要包括流程自动化,专注于功能开发,快速发现问题,快速发布上线。
Serverless 计算
1. 阿里云函数计算
Serverless 是一个新的概念,但是其内涵早就已经存在。阿里云或者 AWS 的第一个云服务都是对象存储,对象储存实际上就是一个存储领域的 Serverless 服务;另外,Serverless 指的是一个产品体系,而不是单个产品。当前业界云服务商推出的新功能或者新产品绝大多数都是 Serverless 形态的。阿里云 Serverless 产品体系包括计算、存储、API 、分析和中间件等,目前云的产品体系正在 Serverless 化。
阿里云 Serverless 计算平台函数计算,有 4 个特点:
- 和云端无缝集成:通过事件驱动的方式将云端的各种服务与函数计算无缝集成,用户只需要关注函数的开发,事件的触发等均由服务商来完成;
- 实时弹性伸缩:由系统自动完成函数计算的弹性伸缩,且速度非常快,用户可以将这种能力用在在线应用上;
- 次秒级计量:次秒级的计量方式提供了一种完全的按需计量方式,资源利用率能达到百分之百;
- 高可用:函数计算平台做了大量工作帮助用户构建高可用的应用。
那么,阿里云函数计算是如何做到以上 4 点呢?阿里云函数计算的产品能力大图如下图所示,首先函数计算产品是建立在阿里巴巴的基础设施服务之上的产品,对在其之上的计算层进行了大量优化。接着在应用层开发了大量能力和工具,基于以上产品能力,为用户提供多种场景下完整的解决方案,才有了整个优秀的函数计算产品。函数计算是阿里云的一个非常基础的云产品,阿里云的许多产品和功能均是建立在函数计算的基础上。目前阿里云函数计算已经在全球 19 个区域提供服务。
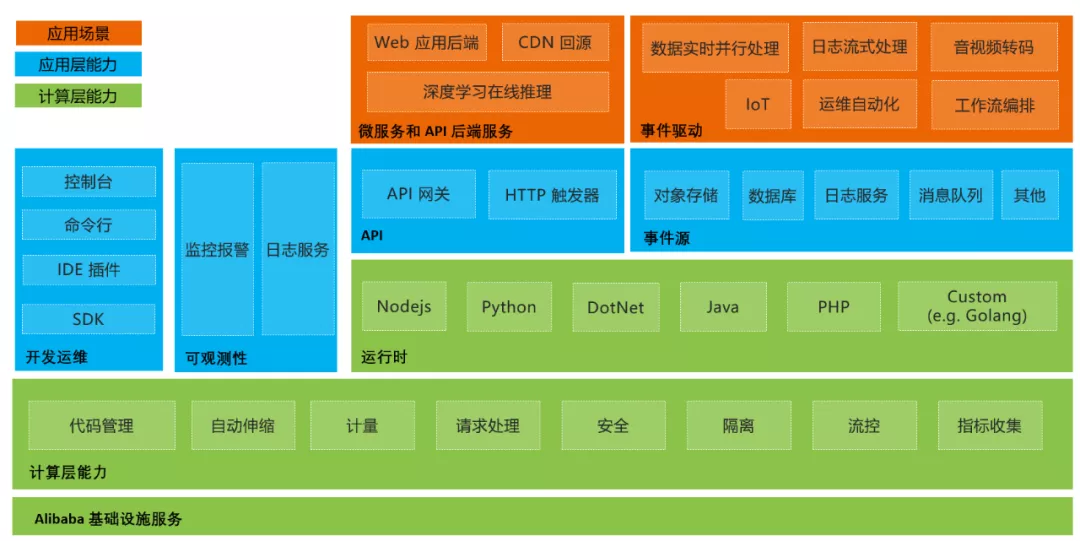
▲ 阿里云函数计算产品能力大图
2. Serverless 帮助用户简化云原生应用高可用设计、实施的复杂度
云原生应用的高可用是一个系统的工程,包括众多方面,完整的高可用体系构建需要很多时间和精力。那么 Serverless 计算是如何帮助用户简化云原生应用高可用设计、实施的复杂度呢? 如下图所示,高可用体系建设要考虑的点包括基础设施层、运行时层、数据层以及应用层,且每一层都有大量的工作要做才可以实现高可用。函数计算主要是从容错、弹性、流控、监控四方面做了大量工作来实现高可用,下图中蓝色虚线框所对应的功能均由平台来实现,用户是不需要考虑的。蓝色实线框虽然平台做了一些工作来简化用户的工作难度,但是仍需要用户来进行关注,而橘红色的实线框代表需要用户去负责的部分功能。结合平台提供的功能和用户的部分精力投入,可以极大地减轻用户进行高可用体系建设的难度。
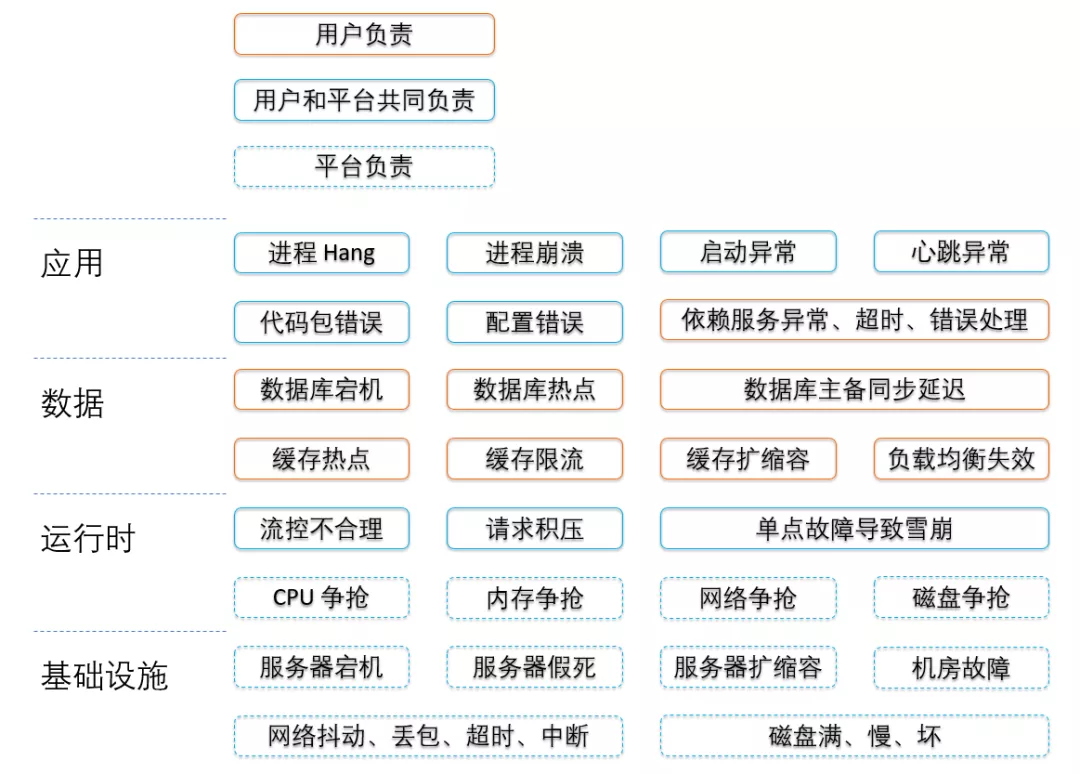
▲ 函数计算高可用
函数计算在很多方面做了优化来帮助用户建设高可用体系。下图展示了函数计算在可用区容灾方面的能力。从图中可知,函数计算做了相应的负载均衡,使得容灾能力大大提升。

▲ 函数计算多可用区容灾
下图展示的是函数计算对事件的异步处理,其处理流水线主要包括事件队列、事件分发、事件消费三个环节,在每一个环节上都可以进行水平伸缩,其中一个比较关键的点是事件的分发需要匹配下游的消费能力。另外,通过为不同函数指定不同数量的计算资源,用户能方便地动态调整不同类型事件的消费速度。此外,还可以自定义错误重试逻辑,并且有背压反馈和流控,不会在短时间内产生大量请求时压垮下一个服务。
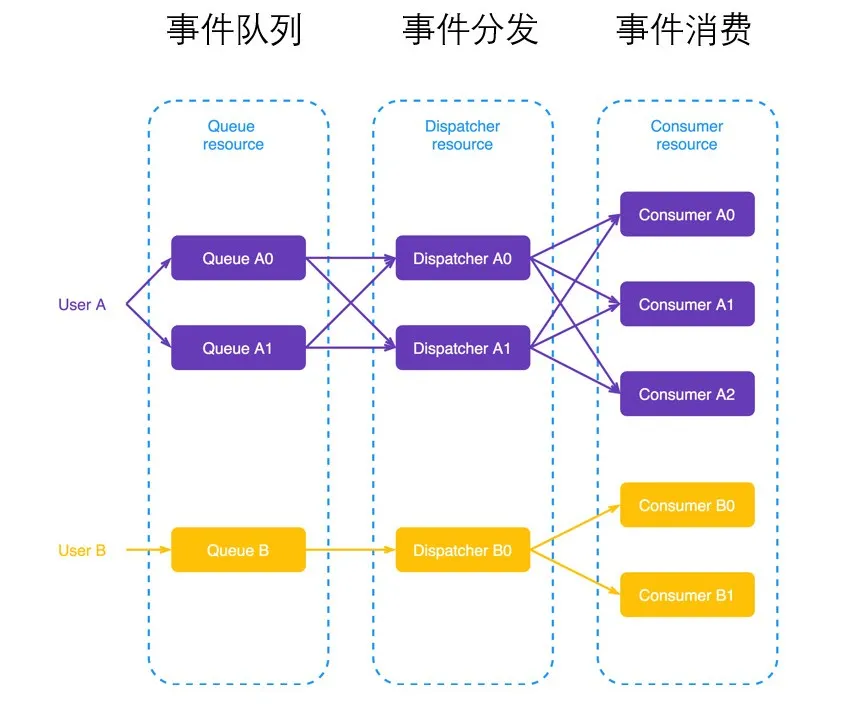
▲ 函数计算事件异步处理
在函数计算的可观测性上面,提供了日志收集和查询功能,除了默认的简单日志查询功能外,还提供了高级日志查询,用户可以更方便地进行日志分析。在指标收集和可视化方面,函数计算提供了丰富的指标收集能力,并且提供了标准指标、概览信息等视图,可以更方便用户进行运维工作。 下图是应用交付的一个示意图,在整个应用的交付过程中,只有每个环节都做好,才能够建设一个敏捷的应用交付流程,其核心是自动化,只有做到了自动化,才能提升整个流水线的效率和敏捷度。
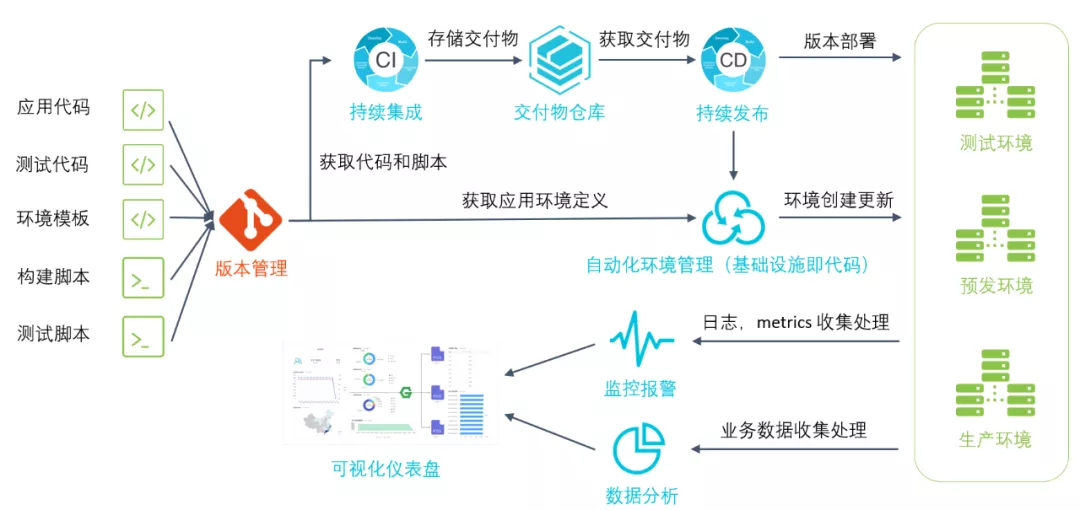
▲ 敏捷的应用交付流程
下图展示了自动化应用交付流水线在每个环节的具体任务。其中需要注意的是做到基础设施即代码,才能进行模板定义和自动化设置应用运行环境,进而实现自动化的持续集成等。

▲ 自动化应用交付流水线
做到了应用的自动化交付之后,对整个研发效率的帮助是非常大的。在 Serverless 应用上,阿里云提供了多种工具来帮助用户实现基础设施即代码。Serverless 的模型有一个很好的能力,就是同一份模板可以传入不同的参数,进而生成不同环境的定义,然后通过自动化地管理这些环境。
对于应用本身不同服务版本的交付和灰度发布,函数计算提供了服务版本和服务别名来提供相应的服务,整个应用的灰度发布流程可以简化成一些 API 的操作,大大提升业务的效率。通过 Serverless 计算平台提供的这些能力,整个软件应用的交付流水线自动化程度得到了大幅度的提高。
函数计算还有一个很有用的功能——对存量应用的兼容性。通过 Custom runtime,能够适配很多的流行框架,兼容传统应用,使其能够很容易地适配到 Serverless 平台上面,由控制台提供应用的创建、部署、关联资源管理、监控等一系列服务。
除了函数计算,还可以用 Serverless 工作流对不同的应用环节、不同的函数进行编排,通过描述性的语言去定义工作流,由其可靠地执行每一个步骤,这就大幅度降低用户对于复杂任务的编排难度。
应用场景案例
函数计算有几个典型的应用场景,一个就是 Web/API 后端服务,阿里云已经有包括石墨文档、微博、世纪华联在内的多个成功应用案例。
函数计算的另外一个应用场景就是大规模的数据并行处理,比如往 OSS 上面上传大量的图片、音频、文本等数据,可以触发函数做自定义的处理,比如转码、截帧等。这方面的成功案例包括虎扑、分众传媒、百家互联等。
函数计算还有一个应用场景就是数据实时流式处理,比如不同的设备产生的消息、日志发送到消息队列等管道类似的服务中,就可以触发函数来进行流式处理。
最后一个应用场景就是运维的自动化,通过定时触发、云监控事件触发、流程编排等方式调用函数完成运维任务,大大降低运维成本和难度,典型的成功案例有图森未来等。
图森未来是一家专注于 L4 级别无人驾驶卡车技术研发与应用的人工智能企业,面向全球提供可大规模商业化运营的无人驾驶卡车技术,为全球物流运输行业赋能。在路测过程中会有大量数据产生,而对这些数据的处理流程复杂多变,即使对于同一批数据,不同的业务小组也会有不同的使用及处理方式。如何有效管理不同的数据处理流程、降低人为介入频率能够大幅的提高生产效率。
路测不定时运行的特点使得流程编排任务运行时间点、运行时长具有极大的不确定性,本地机房独自建立流程管理系统难以最大优化机器利用率,造成资源浪费。而图森未来本地已有许多单元化业务处理脚本及应用程序,但因为各种限制而无法全量的迁移上云,这也对如何合理化使用云上服务带来了挑战。
针对上述情况,图森未来开始探索数据处理平台的自动化。阿里云 Serverless 工作流按执行调度的次数计费,具有易用易集成、运维简单等诸多优点,能够很好地解决上述场景中所遇到的问题,非常适合这类不定时运行的离线任务场景。
Serverless 工作流还支持编排本地或自建机房的任务,图森未来通过使用 Serverless 工作流原生支持的消息服务 MNS 解决了云上云下的数据打通问题,使得本地的原有任务得到很好的编排及管理。
除了调度外,Serverless 工作流也支持对任务的状态及执行过程中所产生的数据进行维护。图森未来通过使用任务的输入输出映射及状态汇报机制,高效地管理了流程中各任务的生命周期及相互间的数据传递。
在未来,随着业务规模的扩大,图森未来将持续优化离线大数据处理流程的运行效率及自动化水平。通过各种探索,图森未来将进一步提升工程团队的效率,将更多的精力和资金投入到业务创新中去。
总结
Serverless 工作流是阿里云 Serverless 产品体系中的关键一环。通过 Serverless 工作流,用户能够将函数计算、视觉智能平台等多个阿里云服务,或者自建的服务,以简单直观的方式编排为工作流,迅速构建弹性高可用的云原生应用。
自 2017 年推出函数计算起,该服务根据应用负载变化实时智能地弹性扩缩容,1 分钟完成上万实例的伸缩并保证稳定的延时。目前已经支撑微博、芒果 TV 、华大基因、图森未来、石墨科技等用户的关键应用,轻松应对业务洪峰。
]]>
作者 | 不瞋 阿里云 Serverless 负责人 来源 | Serverless 公众号
"唯有超越,才能让我们走下去。"
这是不瞋在阿里的第十年。从 2010 年加入阿里云,不瞋参与了阿里云飞天分布式系统的研发,历任批量计算的架构师、表格存储( NoSQL )研发经理,深度参与了阿里云系统研发和产品迭代的全过程。2016 年不瞋成为阿里云函数计算产品研发负责人,致力于构建下一代弹性、高可用的无服务器计算平台。
无服务器( Serverless )是不瞋下一个十年要攻克的技术难题。在这波 Serverless 浪潮里,阿里云一直走在最前面,无论是技术还是产品,在国内的丰富度都是第一。“从不敢掉以轻心,Serverless 在国内还处于早期阶段,只有把技术和产品打磨成熟,让用户体验做到更好,这一战才算胜利。”
我们对不瞋做了一个简单的采访,针对大家比较关心的 Serverless 发展、技术难点以及落地情况,听听他的想法。
接受还是观望?
云计算未来一定会成为整个社会和商业的基础设施,届时使用云计算就应该像现在我们使用水电煤一样简单,不需要了解水从哪里来、怎么过滤、怎么铺设管道等一系列问题,只需要打开水龙头接一杯水而已。而 Serverless 的概念正好可以帮助云计算朝这个方向往前走一步,它提倡的是人们不需要关心应用逻辑以外的服务相关的事情,包括管理、配置、运维等,用多少就付多少。
从这个角度来看,Serverless 是真正让云计算变成社会商业基础设施的一个实现路径,也更接近现在业内提倡的云原生的方式,因此人们在使用云计算的过程中自然就应该按照 Serverless 的方式来使用。
国外的开发者在 Serverless 领域的心智明显比国内开发者建立的更好。因为国外很多公司一开始就是基于 Lambda 生态来创业的,而国内一些大企业已经陆续开始使用 Serverless 的工具和产品,还有很大一部分企业处于观望状态。
一个新产品的出现也是要有一个适应期的,所以在 Serverless 这样一系列产品出现之后,用户对于是否使用、是否迁移、如何迁移是有很多顾虑的。经常会有企业咨询关于函数计算的安全性如何保证,函数计算的稳定性如何保证,以及传统项目迁移到 Serverless 架构是否有比较大的改造成本和改造风险等。这些顾虑很正常,但是我相信,随着 Serverless 的发展,FaaS 定义的越发广泛,工具链建设的越发完整,这些问题都会逐渐被解决。理论上,技术能解决的问题,都不算问题。
没有规模,不要自建 Serverless
Serverless 带来的极致弹性体验、成本节约、开发效率提升等,都是非常具有吸引力的。传统业务在开发上线的过程中,需要团队合作,每个人开发一部分,合并代码,开发联调,然后进行资源评估,测试环境搭建、线上环境搭建、测试上线、运维。但是在 Serverless 时代下,开发者只需要开发自己那部分功能 /函数,然后部署到测试环境、线上环境即可,后期很大一部分运维工作都不用考虑和担心。
可以毫不夸张的说,如果企业自己通过云主机搭建的数据库服务,一般情况下可用性不如云厂商提供的数据库服务,此外,API 网关、数据存储服务等也是云厂商提供的产品性能更好,也更安全可靠。
小企业最好不要自己去建设 Serverless 。因为 Serverless 的核心要素是按量使用,这就意味着如果今天的量很小,你就用很少的资源;如果今天的量很大,就需要调动更多的资源。“双十一”的时候,流量都是亿的量级,如果你的企业内部没有按亿级做单位的这种流量的机器资源,你怎么去调度这些资源给他人使用呢?没办法实现按量调度,就别提 Serverless 了。那些不具备资源规模化的企业不建议去自建 Serverless 能力,但是可以通过使用公有云的产品来实践 Serverless 。
当下,各大厂商都看准了 Serverless 是未来,就算它不是云计算的终态,也是通往终态的一个途径,一方面是因为 Serverless 可以解决很多实际问题,更“像”或者说更“贴近”真正的云计算;另一方面,大家都不想在云计算发展的浪潮中掉队。所以,Serverless 成了必争之地。
关于 Serverless 能力的竞争主要有三部分:
一是性能,包括安全、稳定、弹性等在内,性能这部分如果做不好,我觉得不用说做不做 Serverless,就算云计算也别做了,因为性能是 Serverless 的核心能力,一切都建立在安全、稳定、性能之上。
二是功能,想要把 Serverless 做好,功能是不可缺少的。因为 Serverless 不仅仅是 FaaS,就算是 FaaS 也不仅仅是在线运行,还包括很多东西,如 BaaS 、触发器、日志、监控、告警等。只有在功能上满足开发者的诉求,开发者才有可能愿意使用。
最后是体验,Serverless 的体验太重要了,体验包括方方面面,如功能的易用性、稳定性、安全性、产品的灵活性、工具链的完整性等。除了前面说的三点,我觉得社区、生态、开放等,也非常重要。
阿里云作为国内第一批推出 Serverless 平台的公有云厂商,其 FaaS 平台产品被称为函数计算。从事件触发、支持语言以及用户体验等方面考量,函数计算有很多数据值得关注:
-
事件触发:阿里云函数计算可以被阿里云上的服务事件触发,例如阿里云对象存储( OSS )、日志服务( SLS )、消息服务( MNS )、表格存储( OTS )、API 网关、CDN 等,其特性在于独特的 Callback 机制大大减少开发者对于异步模型的架构和代码成本;
-
支持语言:阿里云函数计算目前支持主流开发语言如 Node.js 、Java 、Python,并通过 Custom Runtime 支持 Go 、C/C+、Ruby 、Lua 语言等;
-
用户体验:阿里云函数计算提供了基于 Web 的控制台和 SDK ;用户可以通过 Web 控制台管理函数应用,也可以通过交互式的命令行来操作;
-
服务模式:函数可以被服务和应用管理,单个函数实例可以并行执行多个请求,有效节省计算资源成本。
棘手的难题
Serverless 的痛点很棘手,例如传统项目如何快速迁移到 Serverless,如何平滑过渡,如何 Serverless 化,Serverless 架构下如何进行更优的调试,如何更好地节约成本等,每一个都是难题。我的同事许晓斌在《喧哗的背后:Serverless 的概念及挑战》一文中曾提到落地 Serverless 面临的挑战:
在主流的场景大规模的落地 Serverless,并不是一件容易的事情,面临的挑战有很多,下面我具体分析一下这些挑战:
挑战一:业务轻量化困难
要实现彻底的自动弹性,按实际使用资源付费,就意味着平台需要能够在秒级甚至毫秒级别扩容出业务实例。这对基础设施是一个挑战,对业务,尤其是比较庞大的业务应用来说,更提出了很高的要求。如果一个应用的分发和启动需要十分钟,那么自动弹性的响应能力就基本无法跟上业务流量的变化了……
挑战二:基础设施响应要求极高
一旦 Serverless 的应用或者函数的实例能够实现秒级,甚至毫秒级扩容,相关基础设施就很快会面临巨大的压力。最常见的基础设施就是服务发现和日志监控系统,原本整个集群实例的变化频率可能是每小时几次,现在这个频率变成了每秒几次;此外,如果这些系统的响应能力跟不上实例变化的速度,那么整个体验也就大打折扣了。
挑战三:业务进程生命周期与容器不一致
Serverless 平台依赖标准化的应用生命周期,才能实现完全自动的容器腾挪,应用自愈等特性。而在基于标准容器及 Kubernetes 的体系下,平台能控制的生命周期就是容器的生命周期。因此就需要业务做到业务进程的生命周期和容器的生命周期保持一致,具体包括启动、停止、以及 readiness probe 和 liveness probe 的规范等等……
挑战四:可观测能力需完善
在 Serverful 的模式下,如果生产环境出现任何问题,服务器是不会消失的,用户会很自然的想到登陆到服务器上去。到了 Serverless 模式下,用户不需要关心服务器了,也就是说默认情况下是看不到服务器了,那么这个时候如果系统出现异常了,而且平台无法完成自愈怎么办呢?……当围绕 Serverless 模式的全面可观测能力不足的时候,用户必然不会对此感到放心。
挑战五:研发运维心智需要改变
几乎所有的研发,在职业生涯中第一次部署自己的应用程序的时候,都是面向一台服务器的,或者说是面向一个 IP 的,这是一种非常强大的习惯。在 Serverless 逐渐落地的过程中,研发需要转换一些思维的模式,逐步地去适应 “IP 随时可能会发生变化” 这样一种心智,转而更多的从服务版本,以及从流量的视角去运维自己的系统。
打个比喻,Serverless 目前确切来说已经有了一个形态,也就是有一个框架,但是这个框架里还有很多格子(问题)没有被填满(解决),这也是大家今天对是不是该用 Serverless 存在疑问的地方,原因之一是还没有看到足够多的成功案例。**但事实上,阿里在 2019 年双十一就已经成功实践了 Serverless 。不仅如此,阿里云还带动了一批企业使用函数计算产品,从而节省了大量的 IT 成本。 **
"成为用户需要的 Serverless"
函数计算有几个非常典型的应用场景,比如 Web 应用、AI 推理、音视频处理、图文处理、实时文件处理、实时流处理等,目前函数计算拥有大量的客户群体,如石墨文档、芒果 TV 、新浪微博、码隆科技等。
以微博为例,函数计算平均每天承载微博几十亿次请求,其毫秒级伸缩计算资源能够确保在热点事件发生时,应用仍能保证稳定的延时,用户体验完全不受访问次数的影响。通过函数计算运行图片处理服务,微博实现了持续的成本节省,再也不需要为平滑处理业务高峰带来的流量激增而提前预留大量闲置机器资源,同时由于不需要维护复杂的机器状态,工程师可以集中精力与产品团队合作增加业务价值,而不是花时间管理基础设施。
不仅像新浪这样的早期互联网企业已经落地 Serverless,一些新兴的创业公司也正在加入 Serverless 阵营。
蓝墨是一家由美国留学生回国创业的高科技公司,专注于移动互联时代数字出版和移动学习领域的新技术研究及平台运营。随着在线教育迎来需求爆发,蓝墨加大了整合业界优质课程资源的力度,不断拓展自身的业务边界,在赢得机遇的同时,技术团队也面临了前所未有的挑战。
视频处理相关业务是蓝墨技术团队遇到的最棘手的问题之一。蓝墨每天都要处理大量视频教材资源,涉及到视频剪辑、切分、组合、转码、分辨率调整、客户端适配等一系列复杂的技术工作。在前几年的技术实践中,蓝墨技术团队通过 FFmpeg 等技术已经建立起一整套自主可控视频处理机制,支撑了业务的快速发展。但今年的业务增长速度是蓝墨的工程师们始料未及的,高峰期数十倍于往年的视频处理需求让现有的架构不堪重负,严重影响了用户体验。
蓝墨现在的核心诉求概括有三个:节省成本、极致弹性、免运维,而这些恰恰是 Serverless 最擅长解决的问题。经过对国内云厂商提供的 Serverless 服务的多方面调研后,蓝墨技术团队一致认为在视频处理领域阿里云函数计算是最适合他们的方案。
由于 FC 完全兼容现有的代码逻辑,也能够支持各类主流的开发语言,**所以蓝墨技术团队可以把代码逻辑以近乎无缝衔接的方式从原有的架构迁移到 FC 上,并且成本极低。**通过对接 OSS 触发器,只要 OSS 上有新的视频源文件上传,就能自动拉起函数计算实例,开启一次视频处理业务的生命周期。
通过整合 Serverless 工作流,还能对分布式任务进行统一编排,实现对于大文件切片后进行并行处理并最终合并的复杂操作,能够在短时间内迅速调集上万个实例的计算资源,实现视频处理任务的快速执行;
另一方面,相比于传统的方式,基于函数计算 FC 的 Serverless 方案在视频处理场景下,可以帮助蓝墨节省了 60% 左右的 IT 成本投入。
下一个十年的主战场
理想中的 Serverless,应该是:更完善的产品形态,更极致的弹性能力,更好用的工具链,更节约的成本,更高效的开发效率,更便捷快速的迁移速度,更简便强大的上云体验。要做到能让开发者以一种方式专注于业务代码的开发,无需关注运行平台的差异性,一处编写可以处处运行,开发者只要掌握一种方式就可以在不同业务之间没有学习成本地切换。
站在开发者的视角,Serverless 的整个研发模型对研发体系也带来了挑战。对于前端来说,Serverless 不仅补足了前端工程师现有的能力,还可能使整个前端行业的定位发生变化。原来经常有人会认为前端的工作很简单,面向 UI 做好开发就行,剩下的工作可以交给后端。但是前端和 Serverless 结合之后,大家对前端的诉求就不仅仅是开发一个页面了,而是要能交付整个应用的开发。
但是相应来讲,后端同学可能第一反应就是,那这是不是把我革命了?我就不需要干活了?其实不是这样的。Serverless 研发模式的演进有助于帮助他们往更底层演进,让他们聚焦于真正需要做技术研究的部分。比如,这些数据的能力、服务的能力,怎么做得更好、更扎实,这是我们期望看到的。
阿里云正在通过工具链、社区以及产品能力的结合,打一张非常有趣且会对 Serverless 的整体发展非常有利的牌。**阿里云 Serverless 的目标是成为“大家需要的 Serverless ”,这是与其他云厂商截然不同的地方。**只有将用户需求放在首位的 Serverless 厂商,才能将 Serverless 产品做好。
未来,Serverless 将无处不在,任何足够复杂的技术方案都可能被实现为全托管、Serverless 化的后端服务。不只是云产品,也包括来自合作伙伴和三方的服务,云及其生态的能力将通过 API + Serverless 来体现。事实上,对于任何以 API 作为功能透出方式的平台型产品或组织,如钉钉、滴滴、微信等,Serverless 都将是其平台战略中最重要的部分。
]]>
作者 | 叔同 来源 |Serverless 公众号
导读:Serverless 将开发人员从繁重的手动资源管理和性能优化中解放出来,就像数十年前汇编语言演变到高级语言的过程一样,云计算生产力再一次发生变革。Serverless 的核心价值是什么?阿里云发布了哪些 Serverless 生态产品,各有什么特别之处?阿里云函数计算的表现如何?阿里云研究员叔同将通过本文分享阿里布局 Serverless 的历程和决心。
引言
早在 2009 年,伯克利曾预测云计算将会得到蓬勃发展。近乎无限的云端计算资源,客户无需自建机房,按需要付费成为可能,企业在 IT 方面的投入显著降低,云计算所释放出的技术红利让越来越多的企业客户从云下搬到了云上。
然而,大部分客户在使用云服务时,仍然要面对复杂的运维、较高的闲置资源、无法做到真正按需付费,云计算的优势并未发挥到极致。
2015 年 AWS 推出了 Lambda 服务,2017 年阿里云推出了函数计算 FC,2019 年伯克利再次预测 Serverless 将取代 Serverful 计算;由此,Serverless 引发业内的广泛关注。
Serverless 将开发人员从繁重的手动资源管理和性能优化中解放出来,就像数十年前汇编语言演变到高级语言的过程一样,云计算生产力再一次发生变革。与其说 Serverless 是云计算的升华,不如说 Serverless 重新定义了云计算,将成为云时代新的计算范式,引领云的下一个十年。
Serverless 的核心价值
快速交付、智能弹性、更低成本,这是 Serverless 的核心三大价值。
首先,是快速交付
Serverless 做了大量的端对端的整合以及云服务之间的集成,为应用开发提供了最大便利性,用户无需关注底层的 IaaS 资源,只需专注于业务逻辑的开发,聚焦于业务创新,大大缩短了企业应用 Go-To-Market 的时间,创造了更大的业务价值。
其次,是极致的弹性
在 Serverless 之前,相信很多开发者都有过类似的经验,一旦遇到突发流量可能会直接导致系统超时、异常,甚至是崩溃;当我们在做大促的时候,需要进行多次的容量评估并提前做好扩容,一旦评估不准,可能会带来灾难性的影响;而有了 Serverles 之后,应对突发流量、容量评估等都将变得更加简单。
其三,是更低的成本
就跟我们生活中的水电煤一样,Serverless 只为实际产生的资源消耗付费,而无需为闲置的资源买单。
基于以上三大核心价值,Serverless 势必将会获得越来越多企业和开发者关注和青睐。
阿里布局 Serverless 的历程
阿里巴巴的 Serverless 实践在业内处于领先地位,不仅淘宝、支付宝、钉钉等已经将 Serverless 应用于生产业务,阿里云上的 Serverless 产品更是帮助微博、石墨、跟谁学、Timing 等数万家企业客户成功落地 Serverless,覆盖前端全栈,小程序、新零售、游戏互娱、在线教育等行业或场景。
丰富的 Serverless 产品给客户提供了更多的选择,面向函数的 Function Compute 、面向应用的 SAE 、面向容器编排的 Serverless K8s 、以及面向容器实例的 ECI,构成当前所有云厂商中最完整的 Serverless 产品矩阵。
而这些 Serverless 产品的背后,是阿里云基础设施的四大核心技术——神龙架构、沙箱容器、盘古存储、洛神网络,它们为 Serverless 提供了稳固的基石与强大的核心竞争力。
完善的 Serverless 产品需要配备完备的后端云服务,而今天我们将隆重发布的事件总线 EventBridge 和 Serverless Workflow 说明了阿里云在 Serverless 战略上的投入和决心。 9 月,阿里云重磅发布四款 Serverless 生态产品,助力阿里云 Serverless 的快速发展。
- 沙箱容器 2.0:阿里云 Serverless 产品的基石,更稳定、更安全、更弹性。
- EventBridge:云上事件枢纽,原生支持 CloudEvents,更标准、更规范。
- Serverless 工作流:提供简单灵活、可视化的函数编排,更直观、更便捷。
- 函数计算 2.0 Plus:携手开发者工具 + 应用中心,引领开发者体验全面升级。
这四款产品有什么特别之处?
沙箱容器 2.0,更轻更快的云原生运行单元,为阿里云 Serverless 产品提供了稳固的基石与强大的核心竞争力。
首先,它可以为用户提供隔离可靠、敏捷高效、裸机性能的运行环境。其次,50ms 冷启动、3ms 热恢复,更是满足 Serverless 对于资源刚性交付的超高要求。其三,通过软硬件协同设计,实现了性能零损耗。地基扎得稳,高楼方能拔地而起。只有基建稳固了,运行在 Serverless 产品之上的应用才能拥有更好的稳定性保证。
阿里云重磅发布 Serverless 事件总线 EventBridge,就好像人的神经中枢,通过 EventBridge 我们将打造云上的事件枢纽。CloudEvents 原生支持,使得 Serverless 事件更加标准化、规范化、统一化。事件无处不在,EventBridge 可以轻松连接云服务、云应用和 SaaS 应用,进一步加速阿里云 Serverless 产品端到端的集成。
2020 年,阿里云重磅发布 Serverless 工作流,它是一个用来协调多个分布式任务执行的全托管 Serverless 云服务,化繁为简,通过简单灵活的工作流描述,可视化的函数编排模型,即可轻松构建媒体处理流程、机器学习流水线、自动化运维流程等复杂的工作。Serverless Workflow 让函数编排更简单、更直观、更便利。
2019 年,阿里云首次发布函数计算 2.0,提供更丰富的运行时、更极致的弹性、更稳健的计算层调度;而今天,函数计算 2.0 Plus 再次升级,携手阿里巴巴丰富开发者框架,从开发者体验出发,全新推出 Serverless-tools 与 Serverless 应用中心,打造更加开放、标准、无厂商绑定的 Serverless 社区。
与此同时,容器镜像与性能实例的加持更是融合了容器生态,打破函数最小运行单位,让开发者使用起来更简单。开发者一步上云、一键 Severless 或将成为现实。
Serverless 实践逐渐深入
好的产品离不开客户的实践。目前,已有大量来自不同领域的客户选择阿里云的 Serverless,通过 Serverless 来构建新业务或优化原有业务。
新浪微博将 Serverless 技术应用于个性化图片处理,实现了百毫秒的极速弹性,综合成本下降 35%。在线教育客户跟谁学,借助 Serverless 技术,高峰期的实时音视频转码效率提升了 93%,综合成本下降 35%;而入选了“2019 福布斯中国最具创新力企业榜”的无人驾驶卡车品牌图森未来,通过 Serverless 技术实现秒级启动千节点 GPU 容器集群,缩短了 60% 的模型测试时间;在线教育平台 Timing,基于 SAE 零改造微服务架构实现 Serverless 化,计算成本下降 30%。
接下来,我们将通过一个 Demo 来演示音视频转码的场景,看下阿里云函数计算的优秀表现。
以转化 1 万个音视频的场景为例,在左边转码效率的比对上,函数计算集成了音视频处理能力,更极致的发挥了云计算的弹性能力,结合 Serverless 工作流的编排能力,分片过程得以自动化,而自建转码集群,需要独立构建分片程序,效率不高,从视频中左边的转码效率对比图看,函数计算节省了 59% 的转码时长;在右边的转码成本的比对上,从 vCPU 弹性 /视频处理吞吐 /排队延迟看,代表自建转码集群的红色曲线,面临严重的闲置资源浪费,代表函数计算的蓝色曲线代表函数计算,将非转码时的计算资源压缩到最低,消除了闲置资源成本,同时结合 Serverless 工作流的编排能力,让原本复杂的转码过程更简单、更自动化,函数计算节省了 48% 的成本。 可见,函数计算可以帮助研发效率和资源效率获得了不同程度的提升。
未来已来,Serverless 正当时!
从领先到普惠,阿里云的 Serverless 正以更为极致的方式在更高效、更经济、更开放的道路上越走越远,为阿里云上的企业客户带来更大的价值。未来十年,Serverless 值得期待! 2020 云栖大会期间,阿里巴巴正式成立云原生技术委员会,阿里巴巴高级研究员蒋江伟担任委员会负责人,达摩院数据库首席科学家李飞飞、阿里云计算平台高级研究员贾扬清、阿里云原生应用平台研究员丁宇等多位阿里技术负责人参与其中。蒋江伟表示,委员会将大力推动阿里经济体全面云原生化,并沉淀阿里巴巴 10 多年的云原生实践,对外赋能数百万家企业进行云原生改造,提升 30% 研发效率的同时降低 30% IT 成本,帮助客户迈入数字原生时代。此次委员会的成立,也意味着阿里已经将云原生升级为新的技术战略方向。
阿里云目前拥有国内规模最大的云原生产品家族和开源生态,提供云原生裸金属服务器、云原生数据库、数据仓库、数据湖、容器、微服务、DevOps 、Serverless 等超过 100 款创新产品。在云栖大会期间,阿里也对外发布云原生全景图,全面展示其在云原生领域的布局和决心。

]]>Serverless 公众号,发布 Serverless 技术最新资讯,汇集 Serverless 技术最全内容,关注 Serverless 趋势,更关注你落地实践中的遇到的困惑和问题。

作者 | 行松 阿里巴巴云原生团队 来源 | Serverless 公众号
应用发布、服务升级一直是一个让开发和运维同学既兴奋又担心的事情。
兴奋的是有新功能上线,自己的产品可以对用户提供更多的能力和价值;担心的是上线的过程会不会出现意外情况影响业务的稳定性。确实,在应用发布和服务升级时,线上问题出现的可能性更高,本文我们将结合 Serverless 应用引擎(以下简称 SAE )就 Serverless 架构下,讨论如何保障上线过程中服务的优雅下线。
在平时的发布过程中,我们是否遇到过以下问题:
- 发布过程中,出现正在执行的请求被中断?
- 下游服务节点已经下线,上游依然继续调用已经下线的节点导致请求报错,进而导致业务异常?
- 发布过程造成数据不一致,需要对脏数据进行修复。
有时候,我们把发版安排在凌晨两三点,赶在业务流量比较小的时候,心惊胆颤、睡眠不足、苦不堪言。那如何解决上面的问题,如何保证应用发布过程稳定、高效,保证业务无损呢?首先,我们来梳理下造成这些问题的原因。
场景分析

上图描述了我们使用微服务架构开发应用的一个常见场景,我们先看下这个场景的服务调用关系:
- 服务 B 、C 把服务注册到注册中心,服务 A 、B 从注册中心发现需要调用的服务;
- 业务流量从负载均衡打到服务 A,在 SLB 上配置服务 A 实例的健康检查,当服务 A 有实例停机的时候,相应的实例从 SLB 摘掉;服务 A 调用服务 B,服务 B 再调用服务 C ;
图中有两类流量,南北向流量(即通过 SLB 转发到后端服务器的业务流量,如业务流量 -> SLB -> A 的调用路径)和东西向流量(通过注册中心服务中心服务发现来调用的流量,如 A -> B 的调用路径),下面针对这两类流量分别进行分析。
南北向流量
南北向流量存在问题
当服务 A 发布的时候,服务 A1 实例停机后,SLB 根据健康检查探测到服务 A1 下线,然后把实例从 SLB 摘掉。实例 A1 依赖 SLB 的健康检查从 SLB 上摘掉,一般需要几秒到十几秒的时间,在这个过程中,如果 SLB 有持续的流量打入,就会造成一些请求继续路由到实例 A1,导致请求失败;
服务 A 在发布的过程中,如何保证经过 SLB 的流量不报错?我们接着看下 SAE 是如何做的。
南北向流量优雅升级方案

如上文所提,请求失败的原因在于后端服务实例先停止掉,然后才从 SLB 摘掉,那我们是不是可以先从 SLB 摘掉服务实例,然后再对实例进行升级呢?
按照这个思路,SAE 基于 K8S service 的能力给出了一种方案,当用户在通过 SAE 为应用绑定 SLB 时,SAE 会在集群中创建一个 service 资源,并把应用的实例和 service 关联,CCM 组件会负责 SLB 的购买、SLB 虚拟服务器组的创建,并且把应用实例关联的 ENI 网卡添加到虚拟服务器组中,用户可以通过 SLB 来访问应用实例;当应用发布时,CCM 会先把实例对应的 ENI 从虚拟服务器组中摘除,然后再对实例进行升级,从而保证流量不丢失。
这就是 SAE 对于应用升级过程中关于南北向流量的保障方案。
东西向流量
东西向流量存在问题
在讨论完南北向流量的解决方案后,我们再看下东西向流量,传统的发布流程中,服务提供者停止再启动,服务消费者感知到服务提供者节点停止的流程如下:

- 1.服务发布前,消费者根据负载均衡规则调用服务提供者,业务正常。
- 2.服务提供者 B 需要发布新版本,先对其中的一个节点进行操作,首先是停止 java 进程。
- 3.服务停止过程,又分为主动注销和被动注销,主动注销是准实时的,被动注销的时间由不同的注册中心决定,最差的情况会需要 1 分钟。
- 1 )如果应用是正常停止,Spring Cloud 和 Dubbo 框架的 Shutdown Hook 能正常被执行,这一步的耗时可以忽略不计。
- 2 )如果应用是非正常停止,比如直接使用
kill -9停止,或者 Docker 镜像构建的时候 java 应用不是 1 号进程且没有把 kill 信号传递给应用。那么服务提供者不会主动去注销服务节点,而是在超过一段时间后由于心跳超时而被动地被注册中心摘除。
- 4.服务注册中心通知消费者,其中的一个服务提供者节点已下线。包含推送和轮询两种方式,推送可以认为是准实时的,轮询的耗时由服务消费者轮询间隔决定,最差的情况下需要 1 分钟。
- 5.服务消费者刷新服务列表,感知到服务提供者已经下线了一个节点,这一步对于 Dubbo 框架来说不存在,但是 Spring Cloud 的负载均衡组件 Ribbon 默认的刷新时间是 30 秒 ,最差情况下需要耗时 30 秒。
- 6.服务消费者不再调用已经下线的节点。
从第 2 步到第 6 步的过程中,Eureka 在最差的情况下需要耗时 2 分钟,Nacos 在最差的情况下需要耗时 50 秒。在这段时间内,请求都有可能出现问题,所以发布时会出现各种报错,同时还影响用户的体验,发布后又需要修复执行到一半的脏数据。最后不得不每次发版都安排在凌晨两三点发布,心惊胆颤,睡眠不足,苦不堪言。
东西向流量优雅升级方案

经过上文的分析,我们看,在传统发布流程中,客户端有一个服务调用报错期,原因就是客户端没有及时感知到服务端下线的实例。在传统发布流程中,主要是借助注册中心通知消费者来更新服务提供者列表,那能不能绕过注册中心,服务提供者直接通知服务消费者呢?答案是肯定的,我们主要做了两件事情:
- 服务提供者应用在发布前后主动向注册中心注销应用,并将应用标记为已下线的状态;将原来的停止进程阶段注销服务变成了 prestop 阶段注销服务。
- 在接收到服务消费者请求时,首先会正常处理本次调用,并通知服务消费者此节点已下线,服务消费者会立即从调用列表删除此节点;在这之后,服务消费者不再调用已经下线的节点。这是将原来的依赖于 注册中心推送,做到了服务提供者直接通知消费者从调用列表中摘除自己。
通过上面这个方案,就使得下线感知的时间大大减短,从原来的分钟级别做到准实时,确保应用在下线时能做到业务无损。
分批发布和灰度发布
上文介绍的是 SAE 在处理优雅下线方面的一些能力,在应用升级的过程中,只有实例的优雅下线是不够的,还需要有一套配套的发布策略,保证我们新业务是可用的,SAE 提供分批发布和灰度发布的能力,可以使得应用的发布过程更加省心省力;
我们先介绍下灰度发布,某应用包含 10 个应用实例,每个应用实例的部署版本为 Ver.1 版本,现需将每个应用实例升级为 Ver.2 版本。

从图中可以看出,在发布的过程中先灰度 2 台实例,在确认业务正常后,再分批发布剩余的实例,发布的过程中始终有实例处于运行状态,实例升级过程中依照上面的方案,每个实例都有优雅下线的过程,这就保证了业务无损。
再来看下分批发布,分批发布支持手动、自动分批;还是上面的 10 个应用实例,假设将所有应用实例分 3 批进行部署,根据分批发布策略,该发布流程如图所示,就不再具体介绍了。

最后针对在 SAE 上应用灰度发布的过程进行演示,演示过程请点击链接观看:https://developer.aliyun.com/lesson_2026_19009
]]>欢迎观看 👉 《 Serverless Rap 》
]]>Respect😂 ]]>
如果把整个 WEB 框架放上去了,这还叫 serverless 吗?或者说这种叫做 serverless framework,也算是 serverless 无服务器架构。
]]>体验地址: https://v2ex.yuga.chat
项目源码: https://github.com/serverless-plus/serverless-v2ex
 ]]>
]]>抢先体验:serverless-cnode
本文主要内容:
- 如何快速部署 Serverless Next.js
- 如何自定义 API 网关域名
- 如何通过 COS 托管静态资源
- 静态资源配置 CDN
- 基于 Layer 部署 node_modules
如何快速部署 Serverless Next.js
由于本人对 Serverless Framework 开发工具比较熟悉,并且长期参与相关开源工作,所以本文均使用 Serverless Components 方案进行部署,请在开始阅读本文之前,保证当前开发环境已经全局安装 serverless 命令行工具。 本文依然上一篇中介绍的 Next.js 组件 来帮助快速部署 Next.js 应用到腾讯云的 Serverless 服务上。
我们先快速初始化一个 Serverless Next.js 项目:
$ serverless create -u https://github.com/serverless-components/tencent-nextjs/tree/master/example -p serverless-nextjs $ cd serverless-nextjs 该项目模板已经默认配置好 serverless.yml,可以直接执行部署命令:
$ serverless deploy 大概 30s 左右就可以部署成功了,之后访问生成的 apigw.url 链接 https://service-xxx-xxx.gz.apigw.tencentcs.com/release/ 就可以看到首页了。
Next.js 组件,会默认帮助我们创建一个 云函数 和 API 网关,并且将它们关联,实际我们访问的 是 API 网关,然后触发云函数,来获得请求返回结果,流程图如下:

解释:我们在执行部署命令时,由于一个简单的 Next.js 应用除了业务代码,还包括庞大的
node_modules文件夹,这就导致打包压缩的代码体积大概20M左右,所以大部分时间消耗在代码上传上。这里的速度也跟开发环境的网络环境有关,而实际上我们云端部署是很快的,这也是为什么需要30s左右的部署时间,而且网络差时会更久,当然后面也会提到如何提高部署速度。
相信你已经体会到,借助 Serverless Components 解决方案的便利,它确实可以帮助我们的应用高效的部署到云端。而且这里使用的 Next.js 组件,针对代码上传也做了很多优化工作,来保证快速的部署效率。
接下来将介绍如何基于 Next.js 组件,进一步优化我们的部署体验。
如何自定义 API 网关域名
使用过 API 网关的小伙伴,应该都知道它可以配置自定义域名,如下图所示:

但是这个手动配置还是不够方便,为此 Next.js 组件也提供了 customDomains 来帮助开发者快速配置自定义域名,于是我们可以在项目的 serverless.yml 中新增如下配置:
org: orgDemo app: appDemo stage: dev component: nextjs name: nextjsDemo inputs: src: dist: ./ hook: npm run build exclude: - .env region: ap-guangzhou runtime: Nodejs10.15 apigatewayConf: protocols: - https environment: release enableCORS: true # 自定义域名相关配置 customDomains: - domain: test.yuga.chat certificateId: abcdefg # 证书 ID # 这里将 API 网关的 release 环境映射到根路径 pathMappingSet: - path: / environment: release protocols: - https 由于这里使用的是 https 协议,所以需要配置托管在腾讯云服务的证书 ID,可以到 SSL 证书控制台 查看。腾讯云已经提供了申请免费证书的功能,当然你也可以上传自己的证书进行托管。
之后我们再次执行部署命令,会得到如下输出结果:

这里由于自定义域名时通过 CNAME 映射到 API 网关服务,所以还需要手动添加输出结果中红框部分的 CNAME 解析记录。等待自定义域名解析成功,就可以正常访问了。
如何通过 COS 托管静态资源
Next.js 应用,有两种静态资源:
- 项目中通过资源引入的方式使用,这种会经过
Webpack打包处理输出到.next/static目录,比如.next/static/css样式文件目录。 - 直接放到项目根目录的
public文件夹,通过静态文件服务返回,然后项目中可以直接通过 url 的方式引入(官方介绍)。
第一种的资源很好处理,Next.js 框架直接支持在 next.config.js 中配置 assetPrefix 来帮助我们在构建项目时,将提供静态资源托管服务的访问 url 添加到静态资源引入前缀中。如下:
// next.config.js const isProd = process.env.NODE_ENV === "production"; const STATIC_URL = "https://serverless-nextjs-xxx.cos.ap-guangzhou.myqcloud.com"; module.exports = { assetPrefix: isProd ? STATIC_URL : "", }; 上面配置中的 STATIC_URL 就是静态资源托管服务提供的访问 url,示例中是腾讯云对应的 COS 访问 url 。
那么针对第二种资源我们如何处理呢?这里就需要对业务代码进行稍微改造了。
首先,需要在 next.config.js 中添加 env.STATIC_URL 环境变量:
const isProd = process.env.NODE_ENV === "production"; const STATIC_URL = "https://serverless-nextjs-xxx.cos.ap-guangzhou.myqcloud.com"; module.exports = { env: { // 3000 为本地开发时的端口,这里是为了本地开发时,也可以正常运行 STATIC_URL: isProd ? STATIC_URL : "http://localhost:3000", }, assetPrefix: isProd ? STATIC_URL : "", }; 然后,在项目中修改引入 public 中静态资源的路径,比如:
<!-- before --> <head> <title>Create Next App</title> <link rel="icon" href="/favicon.ico" /> </head> <!-- after --> <head> <title>Create Next App</title> <link rel="icon" href={`${process.env.STATIC_URL}/favicon.ico`} /> </head> 最后,在 serverless.yml 中新增静态资源相关配置 staticConf,如下:
org: orgDemo app: appDemo stage: dev component: nextjs name: nextjsDemo inputs: src: dist: ./ hook: npm run build exclude: - .env region: ap-guangzhou runtime: Nodejs10.15 apigatewayConf: # 此处省略.... # 静态资源相关配置 staticConf: cosConf: # 这里是创建的 COS 桶名称 bucket: serverless-nextjs 通过配置 staticConf.cosConf 指定 COS 桶,执行部署时,会默认自动将编译生成的 .next 和 public 文件夹静态资源上传到指定的 COS 。
修改好配置后,再次执行 serverless deploy 进行部署:
$ serverless deploy serverless ⚡framework Action: "deploy" - Stage: "dev" - App: "appDemo" - Instance: "nextjsDemo" region: ap-guangzhou # 此处省略...... staticConf: cos: region: ap-guangzhou cosOrigin: serverless-nextjs-xxx.cos.ap-guangzhou.myqcloud.com bucket: serverless-nextjs-xxx 浏览器访问,打开调试控制台,可以看到访问的静态资源请求路径如下:

上图可以看出,静态资源均通过访问 COS 获取,现在云函数只需要渲染入口文件,而不需要像之前,静态资源全部通过云函数返回。
备注:之前由于都是将 .next 部署到了云函数,所以没法访问页面后,页面中的静态资源,如图片,都需要再次访问云函数,然后获取。于是看似我们请求了一次云函数,而实际上云函数单位时间并发数,会根据页面静态资源请求数而增加,从而造成冷启动问题。
静态资源配置 CDN
上面我们已经将静态资源都部署到 COS 了,页面访问也快了很多。但是对于生产环境,还需要给静态资源配置 CDN 的。通过 COS 控制台已经可以很方便的配置 CDN 加速域名了。但是还是需要手动去配置,作为一名懒惰的程序员,我还是不能接受的。 而 Next.js 组件正好提供了给静态资源配置 CDN 的能力,只需要在 serverless.yml 中新增 staticConf.cdnConf 配置即可,如下所示:
# 此处省略.... inputs: # 此处省略.... # 静态资源相关配置 staticConf: cosConf: # 这里是创建的 COS 桶名称 bucket: serverless-nextjs cdnConf: domain: static.test.yuga.chat https: certId: abcdefg 这里使用 https 协议,所以也添加了 https 的 certId 证书 ID 配置。此外静态资源域名也需要修改为 CDN 域名,修改 next.config.js 如下:
const isProd = process.env.NODE_ENV === "production"; const STATIC_URL = "https://static.test.yuga.chat"; module.exports = { env: { STATIC_URL: isProd ? STATIC_URL : "http://localhost:3000", }, assetPrefix: isProd ? STATIC_URL : "", }; 配置好后,再次执行部署,结果如下:
$ serverless deploy serverless ⚡framework Action: "deploy" - Stage: "dev" - App: "appDemo" - Instance: "nextjsDemo" region: ap-guangzhou apigw: # 省略... scf: # 省略... staticConf: cos: region: ap-guangzhou cosOrigin: serverless-nextjs-xxx.cos.ap-guangzhou.myqcloud.com bucket: serverless-nextjs-xxx cdn: domain: static.test.yuga.chat url: https://static.test.yuga.chat 注意:这里虽然添加了 CDN 域名,但是还是需要手动配置 CNAME
static.test.yuga.chat.cdn.dnsv1.com解析记录。
优化前后对比
到这里,Serverless Next.js 应用体验已经优化了很多,我们可以使用 Lighthouse 进行性能测试,来验证下我们的收获。测试结果如下:
优化前:

优化后:

前后对比,可以明显看出优化效果,当然这里主要是针对静态资源进行了优化处理,减少了冷启动。为了更好地游湖体验,我们还可以做的更多,这里就不展开讨论了。
基于 Layer 部署 node_modules
随着我们的业务变得复杂,项目体积会越来越大,node_modules 文件夹也会变得原来越大,而现在每次部署都需要将 node_modules 打包压缩,然后上传,跟业务代码一起部署到云函数。在实际开发中, node_modules 大部分时候是不怎么变化的,但是当前每次都需要上传,这必然会浪费很多部署时间,尤其在网络状态不好的情况下,代码上传就更慢了。
既然 node_modules 文件夹是不怎么变更的,那么我们能不能只有在它变化时才上传更新呢?
借助 Layer 的能力是可以实现的。
在这之前,先简单介绍下 Layer:
借助 Layer,可以将项目依赖放在 Layer 中而无需部署到云函数代码中。函数在执行前,会先加载 Layer 中的文件到
/opt目录下(云函数代码会挂载到/var/user/目录下),同时会将/opt和/opt/node_modules添加到NODE_PATH中,这样即使云函数中没有node_modules文件夹,也可以通过require('abc')方式引入使用该模块。
正好 Layer 组件 可以帮助我们自动创建 Layer。
使用时只需要在项目下添加 layer 文件夹,并且创建 layer/serverless.yml 配置如下:
org: orgDemo app: appDemo stage: dev component: layer name: nextjsDemo-layer inputs: region: ap-guangzhou name: ${name} src: ../node_modules runtimes: - Nodejs10.15 - Nodejs12.16 配置说明:
region:地区,需要跟云函数保持一致 name:Layer 名称,在云函数绑定指定 Layer 时需要指定 src:指定需要上传部署到 Layer 的目录 runtimes:支持的云函数运行环境
执行部署 Layer 命令:
$ serverless deploy --target=./layer serverless ⚡framework Action: "deploy" - Stage: "dev" - App: "appDemo" - Instance: "nextjsDemo-layer" region: ap-guangzhou name: nextjsDemo-layer bucket: sls-layer-ap-guangzhou-code object: nextjsDemo-layer-1594356915.zip description: Layer created by serverless component runtimes: - Nodejs10.15 - Nodejs12.16 version: 1 从输出可以清晰看到 Layer 组件已经帮助我们自动创建了一个名称为 nextjsDemo-layer,版本为 1 的 Layer 。
接下来我们如何自动和我们的 Next.js 云函数绑定呢?
参考 serverless components outputs 说明文档 ,可以通过引用一个基于 Serverless Components 部署成功的实例的 outputs (这里就是控制台输出对象内容),语法如下:
# Syntax ${output:[stage]:[app]:[instance].[output]} 那么我们只需要在项目根目录的 serverless.yml 文件中,添加 layers 配置就可以了:
org: orgDemo app: appDemo stage: dev component: nextjs name: nextjsDemo inputs: src: dist: ./ hook: npm run build exclude: - .env - "node_modules/**" region: ap-guangzhou runtime: Nodejs10.15 layers: - name: ${output:${stage}:${app}:${name}-layer.name} version: ${output:${stage}:${app}:${name}-layer.version} # 静态资源相关配置 # 此处省略.... 注意:不同组件部署实例结果的依赖使用,需要保证 serverless.yml 中
org,app,stage三个配置是一致的。
由于 node_modules 已经通过 Layer 部署,所以还需要在 src.exclude 中添加忽略部署该文件夹。
之后再次执行部署命令 serverless deploy 即可, 你会发现这次部署时间大大缩减了,因为我们不在需要每次压缩上传 node_moduels 这个庞大的文件夹了 (^▽^)
最后
基于以上方案,我部署了一个完整的 Cnode 项目,serverless-cnode,欢迎感兴趣的小伙伴,提交宝贵的 ISSUE/PR 。
关于 Serverless SSR 的方案,我也在不断尝试和探索中,如果你有更好的方案和建议,欢迎评论或者私信来撩~
欢迎访问:Serverless 中文网
]]>读完本文将了解到:
传统 Web 服务特点
Web 服务定义:
Web 服务是一种
面向服务的架构(SOA) 的技术,通过标准的 Web 协议提供服务,目的是保证不同平台的应用服务可以互操作。
日常生活中,接触最多的就是基于 HTTP 协议的服务,客户端发起请求,服务端接受请求,进行计算处理,然后返回响应,简单示意图如下:
<center> </center>
</center> 传统 Web 服务部署流程:通常需要将项目代码部署到服务器上,启动服务进程,监听服务器的相关端口,然后等待客户端请求,从而响应返回处理结果。而这个服务进程是常驻的,就算没有客户端请求,也会占用相应服务器资源。
一般我们的服务是由高流量和低流量场景交替组成的,但是为了考虑高流量场景,我们需要提供较高的服务器配置和多台服务进行负载均衡。这就导致服务处在低流量场景时,会多出很多额外的闲置资源,但是购买的资源却需要按照高流量场景进行付费,这是非常不划算的。
如果我们的服务能在高流量场景自动扩容,低流量场景自动缩容,并且只在进行计算处理响应时,才进行收费,而空闲时间不占用任何资源,就不需要收费呢?
答案就是 Serverless。
Serverless 适用场景
上面已经提到了 Serverless 的两个核心特点:按需使用和收费 和 自动扩缩容。而且近几年 Serverless 的应用也越来越广泛,但是它并不是银弹,任何技术都是有它的适合场景和不适合场景。我们不能因为一项技术的火热,而盲目的追捧。Serverless 是有它的局限性的,一般 Serverless 适合如下几种场景:
- 异步的并发,组件可独立部署和扩展
- 应对突发或服务使用量不可预测
- 无状态,计算耗时较短服务
- 请求延时不敏感服务
- 需要快速开发迭代的业务
如果你的服务不满足以上条件,笔者是不推荐迁移到 Serverless 。
Web 框架如何迁移到 Serverless
如果你的服务是以上提到的任何话一个场景,那么就可以尝试迁移到 Serverless 上。
常见的 Serverless HTTP 服务结构图如下:
<center> </center>
</center> 那么我们如何将 Web 服务进行迁移呢?
我们知道 Faas (云函数)是基于事件触发的,也就是云函数被触发运行时,接收到的是一个 JSON 结构体,它跟传统 Web 请求时有区别的,这就是为什么需要额外的改造工作。而改造的工作就是围绕如何将事件 JSON 结构体转化成标准的 Web 请求。
所以 Serverless 化 Web 服务的核心就是需要开发一个 适配层,来帮我们将触发事件转化为标准的 Web 请求。
整个处理流程图如下:
<center> </center>
</center> 接下来将介绍如何为 Express 框架开发一个适配层。
Serverless Express 适配层开发
实现原理
首先我们先来看看一个标准的云函数结构:
module.exports.handler = (event, context) => { // do some culculation return res; }; 在介绍如何开发一个 Express 的适配层前,我们先来熟悉下 Express 框架。
一个简单的 Node.js Web 服务如下:
const http = require("http"); const server = http.createServer(function (req, res) { res.end("helloword"); }); server.listen(3000); Express 就是基于 Node.js 的 Web 框架,而 Express 核心就是 通过中间件的方式,生成一个回调函数,然后提供给 http.createServer() 方法使用。
Express 核心架构图如下:
<center> </center>
</center> 由此可知,我们可以将 Express 框架生成的回调函数,作为 http.createServer() 的参数,来创建可控的 HTTP Server,然后将云函数的 event 对象转化成一个 request 对象,通过 http.request() 方法发起 HTTP 请求,获取请求响应,返回给用户,就可以实现我们想要的结果。
Node.js Server 的监听方式选择
对于 Node.js 的 HTTP Server,可以通过调用 server.listen() 方法来启动服务,listen() 方法支持多种参数类型,主要有两种监听方式 从一个 TCP 端口启动监听 和 从一个 UNIX Socket 套接字启动监听。
server.listen(port[, hostname][, backlog][, callback]):从一个 TCP 端口启动监听server.listen(path, [callback]):从一个 UNIX Domain Socket 启动监听
服务器创建后,我们可以像下面这样启动服务器:
// 从'127.0.0.1'和 3000 端口开始接收连接 server.listen(3000, '127.0.0.1', () => {}); // 从 UNIX 套接字所在路径 path 上监听连接 server.listen('path/to/socket', () => {}) 无论是 TCP Socket 还是 Unix Domain Socket,每个 Socket 都是唯一的。TCP Socket 通过 IP 和端口 描述,而 Unix Domain Socket 通过 文件路径 描述。
TCP 属于传输层的协议,使用 TCP Socket 进行通讯时,需要经过传输层 TCP/IP 协议的解析。
而 Unix Domain Socket 可用于不同进程间的通讯和传递,使用 Unix Domain Socket 进行通讯时不需要经过传输层,也不需要使用 TCP/IP 协议。所以,理论上讲 Unix Domain Socket 具有更好的传输效率。
因此这里在设计启动服务时,采用了 Unix Domain Socket 方式,以便减少函数执行时间,节约成本。
关于 Node.js 如何实现 IPC 通信,这里就不详细介绍的,感兴趣的小伙伴可以深入研究下,这里有个简单的示例,nodejs-ipc
代码实现
原理大概介绍清楚了,我们的核心实现代码需要以下三步:
- 通过 Node.js HTTP Server 监听 Unix Domain Socket,启动服务
function createServer(requestListener, serverListenCallback) { const server = http.createServer(requestListener); server._socketPathSuffix = getRandomString(); server.on("listening", () => { server._isListening = true; if (serverListenCallback) serverListenCallback(); }); server .on("close", () => { server._isListening = false; }) .on("error", (error) => { // ... }); server.listen(`/tmp/server-${server._socketPathSuffix}.sock`) return server; } - 将 Serverless Event 对象转化为 Http 请求
function forwardRequestToNodeServer(server, event, context, resolver) { try { const requestOptiOns= mapApiGatewayEventToHttpRequest( event, context, getSocketPath(server._socketPathSuffix), ); // make http request to node server const req = http.request(requestOptions, (response) => forwardResponseToApiGateway(server, response, resolver), ); if (event.body) { const body = getEventBody(event); req.write(body); } req .on('error', (error) => // ... ) .end(); } catch (error) { // ... return server; } } - 将 HTTP 响应转化为 API 网关标准数据结构
function forwardResponseToApiGateway(server, response, resolver) { response .on("data", (chunk) => buf.push(chunk)) .on("end", () => { // ... resolver.succeed({ statusCode, body, headers, isBase64Encoded, }); }); } 最后函数的 handler 将异步请求返回就可以了。
借助 tencent-serverless-http 库实现
如果不想手写这些适配层代码,可以直接使用 tencent-serverless-http 模块。
它使用起来很简单,创建我们的 Express 应用入口文件 sls.js:
const express = require("express"); const app = express(); // Routes app.get(`/`, (req, res) => { res.send({ msg: `Hello Express`, }); }); module.exports = app; 然后创建云函数 sl_handler.js 文件:
const { createServer, proxy } = require("tencent-serverless-http"); const app = require("./app"); exports.handler = async (event, context) => { const server = createServer(app); const result = await proxy(server, event, context, "PROMISE").promise; }; 接下来,将业务代码和依赖模块一起打包部署到云函数就可以了(记得指定 执行方法 为 sl_handler.handler )。
其他 Node.js 框架
除了 Express 框架,其他的 Node.js 框架也基本类似,只需要按照要求,exports 一个 HTTP Server 的回调函数就可以。
比如 Koa,我们拿到初始化的 Koa 应用后,只需要将 app.callback() 作为 createServer() 方法的参数就可以了,如下:
const { createServer, proxy } = require("tencent-serverless-http"); const app = require("./app"); exports.handler = async (event, context) => { // 这里和 Express 略有区别 const server = createServer(app.callback()); const result = await proxy(server, event, context, "PROMISE").promise; }; 其他语言框架
对于非 Node.js 框架,比如 Python 的 Flask 框架,原理都是一样的,核心只需要做到 将 Serverless Event 对象转化为 Http 请求,就可以了。由于笔者对其他语言不太熟悉,这里就不做深入介绍了,感兴趣的小伙伴,可以到 Github 社区搜索下,已经有很多对应的解决方案了,或者自己尝试手撸也是可以的。
使用 Serverless Components 快速部署 Web 框架
读到这里,相信你已经清楚,如何将自己的 Node.js 框架迁移到 Serverless 了。但是在这之前,我们都是手动处理的,而且每次都需要自己创建 handler.js 文件,还是不够方便。
为此开源社区提供了一套优秀的解决方案 Serverless Component,通过组件,我们进行简单的 yaml 文件配置后,就可以方便的将我们的框架代码部署到云端。
比如上面提到的 Express 框架,就有对应的组件,我们只需要在项目根目录下创建 serverless.yml 配置文件:
component: express name: expressDemo inputs: src: ./ region: ap-guangzhou runtime: Nodejs10.15 apigatewayConf: protocols: - https environment: release 然后全局安装 serverless 命令 npm install serverless -g 之后,执行部署命令即可:
$ serverless deploy 耐心等待几秒,我们的 Express 应用就成功部署到云端了。更多详细信息,请参考 Express 官方文档
注意:本文 Serverless 服务均基于
腾讯云部署。
Serverless Express 组件不仅能帮我们快速部署 Express 应用,而且它还提供了 实时日志 和 云端调试 的能力。
只需要在项目目录下执行 serverless dev 命令,serverless 命令行工具就会自动监听项目业务代码的更改,并且实时部署,同时我们可以通过打开 Chrome Devtools 来调试 Express 应用。
关于云端调试,腾讯云 Serverless Framework 正式发布公告 中有详细的介绍,并且有视频演示。
而且除了 Express 组件,还支持:Koa.js ,Egg.js ,Next.js ,Nuxt.js.....
最后
当然 Serverless 化 Web 服务并没有本文介绍的那么简单,比如文件读写,服务日志存储,Cookie/Session 存储等......实际开发中,我们还会面临各种未知的坑,但是比起困难,Serverless 带给我们的收益是值得去尝试的。当然传统 Web 服务真的适合迁移到 Serverless 架构上,也是值得我们去思考的问题,毕竟现有的 Web 框架都是面向传统 Web 服务开发实现的 (推荐阅读 利与弊-传统框架要不要部署在 Serverless 架构上)。但是笔者相信,很快就会出现一个专门为 Serverless 而生的 Web 框架,可以帮助我们更好地基于 Serverless 开发应用 ~
欢迎访问:Serverless 中文社区
]]>或者说,这类 Serverless 产品解决了哪些 SAE 无法实现的痛点呢?
]]>本文作者:yugasun,原文地址:前端福音:Serverless 和 SSR 的天作之合
什么是 SSR
SSR 顾名思义就是 Server-Side Render, 即服务端渲染。原理很简单,就是服务端直接渲染出 HTML 字符串模板,浏览器可以直接解析该字符串模版显示页面,因此首屏的内容不再依赖 Javascript 的渲染( CSR - 客户端渲染)。
SSR 的核心优势:
- 首屏加载时间:因为是 HTML 直出,浏览器可以直接解析该字符串模版显示页面。
- SEO 友好:正是因为服务端渲染输出到浏览器的是完备的 html 字符串,使得搜索引擎 能抓取到真实的内容,利于 SEO 。
SSR 需要注意的问题:
- 虽然 SSR 能快速呈现页面,但是在 UI 框架(比如 React )加载成功之前,页面是没法进行 UI 交互的。
- TTFB (Time To First Byte),即第一字节时间会变长,因为 SSR 相对于 CSR 需要在服务端渲染出更对的 HTML 片段,因此加载时间会变长。
- 更多的服务器端负载。由于 SSR 需要依赖 Node.js 服务渲染页面,显然会比仅仅提供静态文件的 CSR 应用需要占用更多服务器 CPU 资源。以 React 为例,它的
renderToString()方法是同步 CPU 绑定调用,这就意味着在它完成之前,服务器是无法处理其他请求的。因此在高并发场景,需要准备相应的服务器负载,并且做好缓存策略。
什么是 Serverless
Serverless,它是云计算发展过程中出现的一种计算资源的抽象,依赖第三方服务,开发者可以更加专注的开发自己的业务代码,而无需关心底层资源的分配、扩容和部署。
特点:
- 开发者只需要专注于业务,无需关心底层资源的分配、扩容和部署
- 按需使用和收费
- 自动扩缩容
更详细的有关 Serverless 介绍,推荐阅读:精读《 Serverless 给前端带来了什么》
Serverless + SSR
结合 Serverless 和 SSR 的特点,我们可以发现他们简直是天作之合。借助 Serverless,前端团队无需关注 SSR 服务器的部署、运维和扩容,可以极大地减少部署运维成本,更好的聚焦业务开发,提高开发效率。
同时也无需关心 SSR 服务器的性能问题,理论上 Serverless 是可以无限扩容的(当然云厂商对于一般用户是有扩容上限的)。
如何快速将 SSR 应用 Serverless 化?
既然说 Serverless 对于 SSR 来说有天然的优势,那么我们如何将 SSR 应用迁移到 Serverless 架构上呢?
本文将以 Next.js 框架为例,带大家快速体验部署一个 Serverless SSR 应用。
借助 Serverless Framework 的 Nextjs 组件,基本可以实现无缝迁移到腾讯云云函数 SCF 上。
1. 初始化 Next.js 项目
$ npm init next-app serverless-next $ cd serverless-next # 编译静态文件 $ npm run build 2. 全局安装 Serverless CLI
$ npm install serverless -g 3. 配置 severless.yml
org: orgDemo app: appDemo stage: dev component: nextjs name: nextjsDemo inputs: src: ./ functionName: nextjsDemo region: ap-guangzhou runtime: Nodejs10.15 exclude: - .env apigatewayConf: protocols: - https environment: release 4. 部署
部署时需要进行身份验证,如您的账号未 登录 或 注册 腾讯云,您可以直接通过 微信 扫描命令行中的二维码进行授权登陆和注册。当然你也可以直接在项目下面创建 .env 文件,配置腾讯云的 SecretId 和 SecretKey。如下:
TENCENT_SECRET_ID=123 TENCENT_SECRET_KEY=123 执行部署命令:
$ serverless deploy 以下
serverless命令全部简写为sls.
部署成功后,直接访问 API 网关生成的域名,这里是就可以了。
类似
https://service-xxx-xxx.gz.apigw.tencentcs.com/release/这种链接。
现有 Next.js 应用迁移
如果你的项目是基于 Express.js 的自定义 Server,那么需要在项目根目录新建 sls.js 入口文件,只需要将原来启动 Node.js Server 的入口文件复制到 sls.js 中,然后进行少量改造就好,默认入口 sls.js 文件如下:
const express = require('express'); const next = require('next'); const app = next({ dev: false }); const handle = app.getRequestHandler(); // 将原来的服务逻辑放入到异步函数 `createServer()`中 async function createServer() { // 内部内容需要根据项目需求进行修改就好,基本是你的 `server.js` 的原代码 await app.prepare(); const server = express(); server.all('*', (req, res) => { return handle(req, res); }); // 定义返回二进制文件类型 // 由于 Next.js 框架默认开启 `gzip`,所以这里需要配合为 `['*/*']` // 如果项目关闭了 `gzip` 压缩,那么对于图片类文件,需要定制化配置,比如 `['image/jpeg', 'image/png']` server.binaryTypes = ['*/*']; return server; } // export 函数 createServer() module.exports = createServer; 添加入口文件后,重新执行部署命令 sls deploy 就 OK 了。
Serverless 部署方案的优化
至此,我们已经成功将整个 Next.js 应用迁移到腾讯云的 Serverless 架构上了,但是这里有个问题,就是所有的静态资源都部署到了云函数 SCF 中,这就导致我们每次页面请求的同时,会产生很多静态源请求,对于 SCF 来说同一时间并发会比较高,而且很容易造成冷启动。而且大量静态资源通过 SCF 输出,然后经过 API 网关返回,会额外增加链路长度,也会导致静态资源加载慢,无形中也会拖累网页的加载速度。
云厂商一般会提供云对象存储功能,腾讯云叫 COS (对象存储),用它来存储我们的静态资源有天然的优势。而且开始使用有 50GB!!! 的免费容量(用来存喜爱的高清电影也是不错的吧~)。
要是在我们项目部署时,将静态资源统一上传到 COS,然后静态页面通过 SCF 渲染,这样既支持了 SSR,也解决了静态资源访问问题。而且 COS 也支持 CDN 加速,这样静态资源优化就更加方便。
那么我们如何将静态资源上传到 COS 呢?
普通青年做法
登录 [腾讯云 COS 控制台]( https://console.cloud.tencent.com/cos5) -> 创建存储桶 -> 获取 COS 访问链接 -> 构建 Next.js 项目 -> 点击 COS 上传按钮 -> 选择上传文件 -> 开始上传 -> 完成 文艺青年做法
配置 COS 组件 -> 构建 Next.js 项目 -> 执行部署 COS 组件命令 -> 完成 接下来我们一起学习下文艺青年是如何做的。
在项目下创建 COS 文件夹,创建 cos/serverless.yml 配置文件:
org: orgDemo app: appDemo stage: dev component: cos name: serverless-cos inputs: # src 配置成你的 next 项目构建的目标目录 src: ../.next/static # 由于 next 框架在访问静态文件会自动附加 _next 前缀,所以这里需要配置上传 COS 的目标目录为 /_next targetDir: /_next/static bucket: serverless-bucket region: ap-guangzhou protocol: https acl: permissions: public-read 根据 COS 访问链接生成规则:
<protocol>://<bucket-name>-<appid>.cos.<region>.myqcloud.com 可以直接推断出部署后的访问 URL 为:https://serverless-bucket-1251556596.cos.ap-guangzhou.myqcloud.com
然后在项目更目录新建 next.config.js 文件,配置 assetPrefix 为该链接:
const isProd = process.env.NODE_ENV === 'production'; module.exports = { assetPrefix: isProd ? 'https://serverless-bucket-1251556596.cos.ap-guangzhou.myqcloud.com' : '', }; 注意:如果你是直接给该 COS 配置了 CDN 域名。
然后执行构建:
$ npm run build 然后部署命令新增部署到 cos 命令执行就好:
$ sls deploy --target=./cos && sls deploy 然后我们就可以耐心等待部署完成。
Serverless + Next.js 部署流程图
优化后项目整体部署流程图如下:
<center>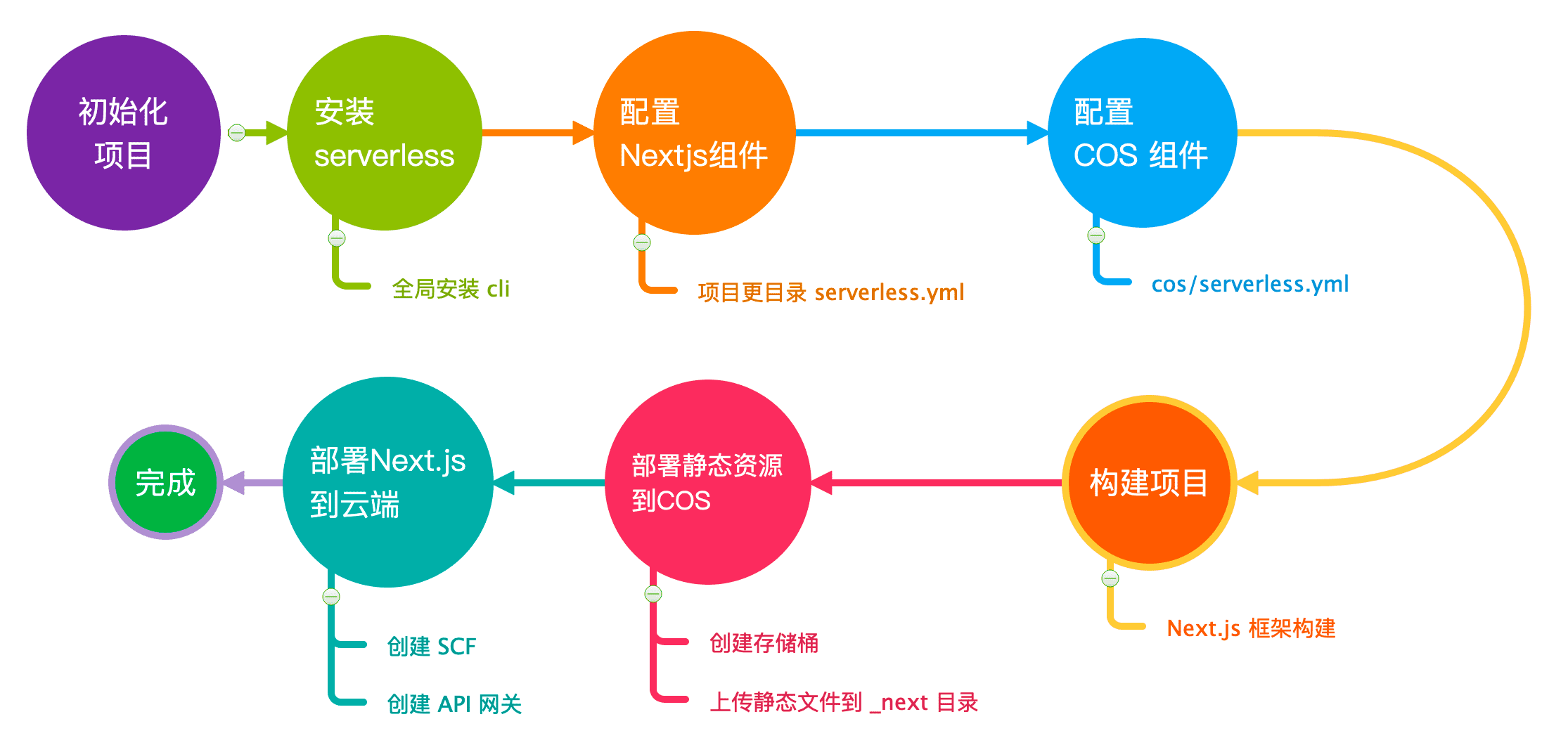 </center>
</center> 起初虽然看起来步骤很多,但是项目配置一次后,之后部署,只需要执行构建和部署命令,就可以了。
性能分析
依赖 Serverless Component, 虽然我们可以快速部署 SSR 应用。但是对于开发者来说,性能才是最重要的。那么 Serverless 方案的性能表现如何呢?
为了跟传统的 SSR 服务做对比,我专门找了一台 CVM (腾讯云服务器),然后部署相同的 Next.js 应用。分别进行压测和性能分析。
压测配置如下:
| 起始人数 | 每阶段增加人数 | 每阶段持续时间(s) | 最大人数 | 发包间隔时间(ms) | 超时时间(ms) | | -------- | -------------- | ----------------- | -------- | ---------------- | ------------ | | 5 | 5 | 30 | 100 | 0 | 10000 |
本文压测使用的是 腾讯 WeTest。
页面访问性能对比
均使用 Chrome 浏览器
| 方案 | 配置 | TTFB | FCP | TTI | | :---------------- | :---------------------: | :-----: | :--: | :--: | | 腾讯云 CVM | 2 核,4G 内存,10M 带宽 | 50.12ms | 2.0s | 2.1s | | 腾讯云 Serverless | 128M 内存 | 69.88ms | 2.0s | 2.2s |
压测性能对比
1.响应时间:
<center>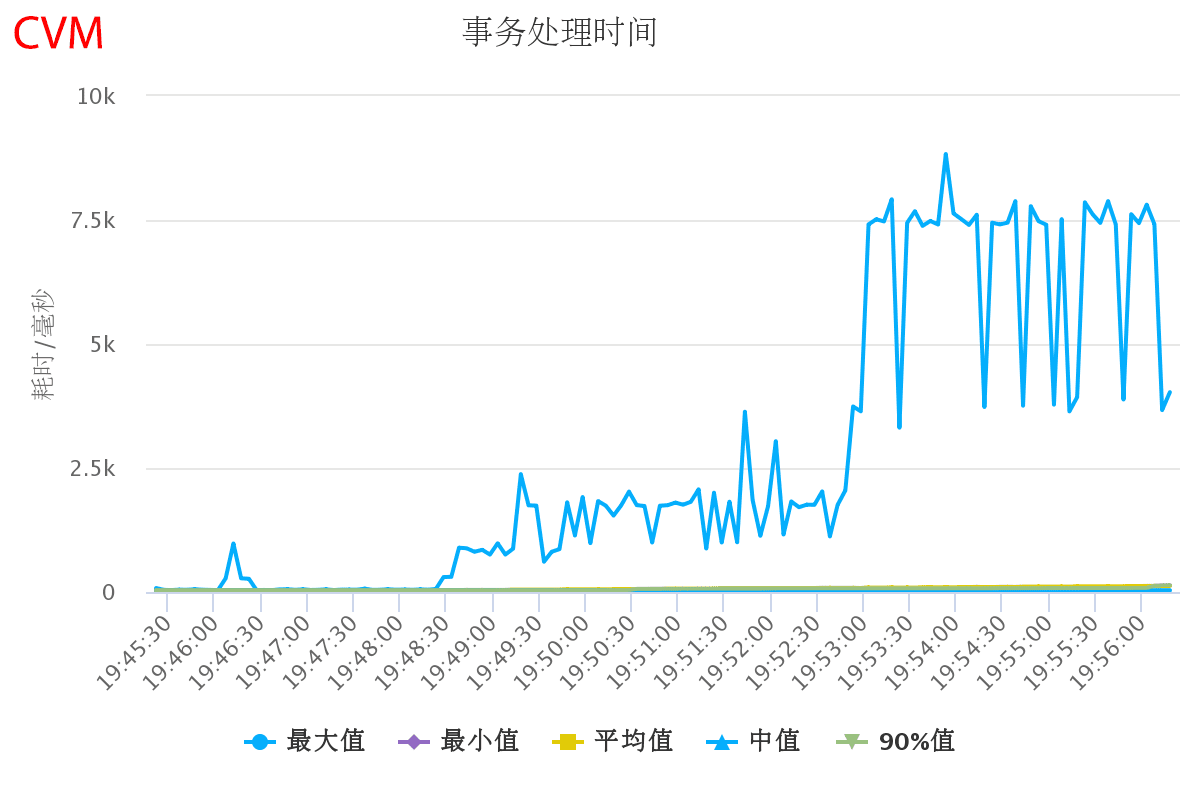 </center> <center>
</center> <center> 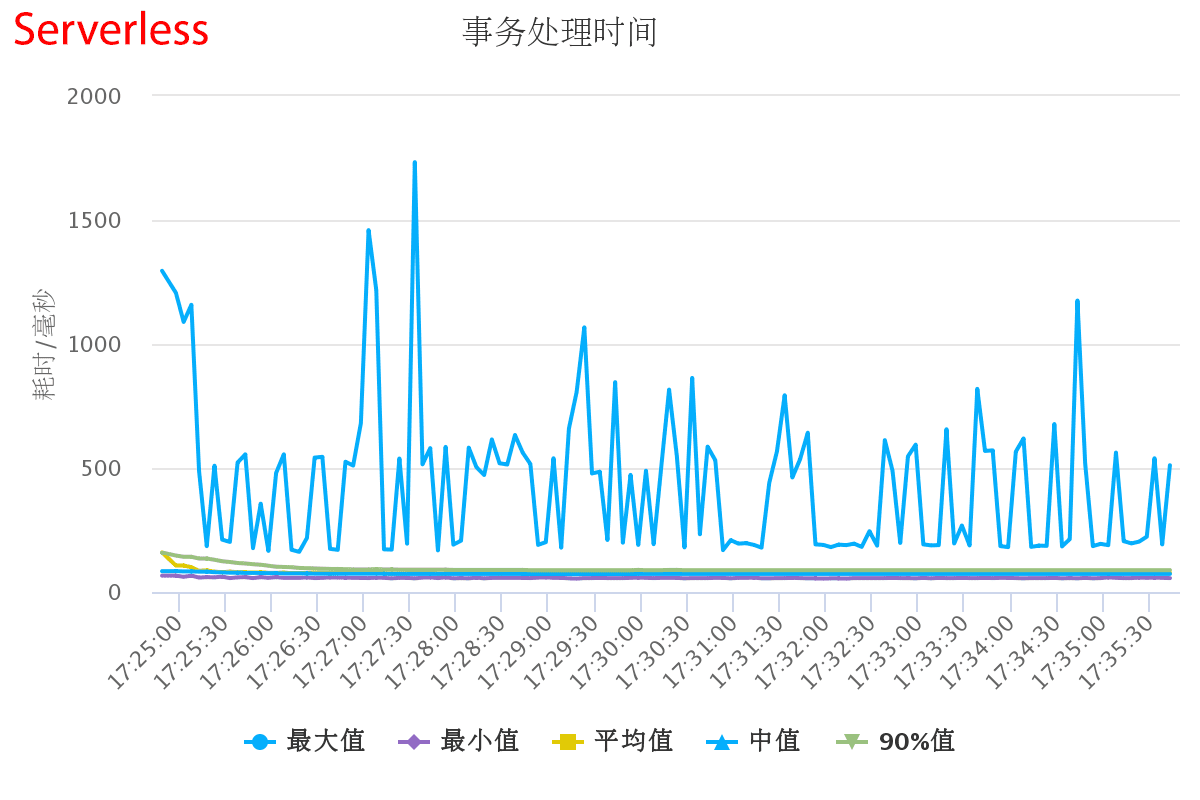 </center>
</center> | 方案 | 配置 | 最大响应时间 | P95 耗时 | P50 耗时 | 平均响应时间 | | :---------------- | :---------------------: | :----------: | :------: | :------: | :----------: | | 腾讯云 CVM | 2 核,4G 内存,10M 带宽 | 8830ms | 298ms | 35ms | 71.05 ms | | 腾讯云 Serverless | 128M 内存 | 1733ms | 103ms | 73ms | 76.78 ms |
2.TPS:
<center>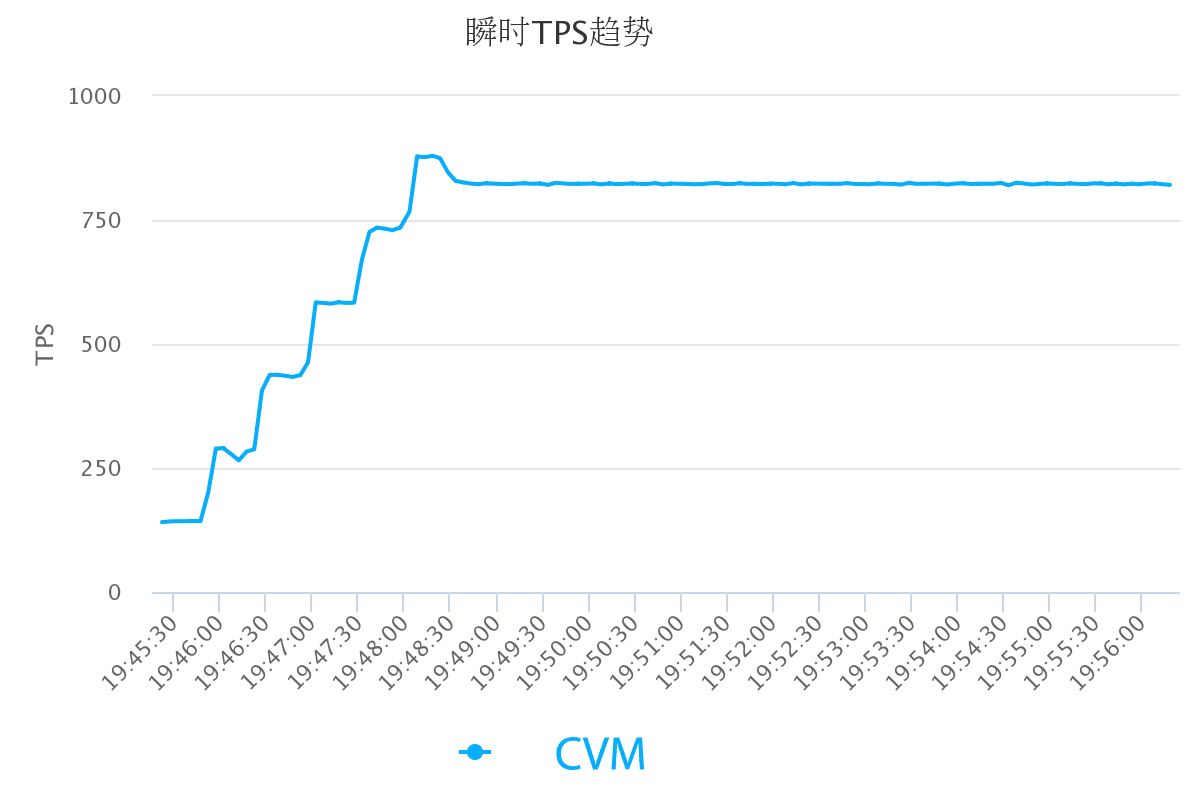 </center> <center>
</center> <center>  </center>
</center> | 方案 | 配置 | 平均 TPS | | :---------------- | :---------------------: | --------- | | 腾讯云 CVM | 2 核,4G 内存,10M 带宽 | 727.09 /s | | 腾讯云 Serverless | 128M 内存 | 675.59 /s |
价格预算对比
直接上图:
<center>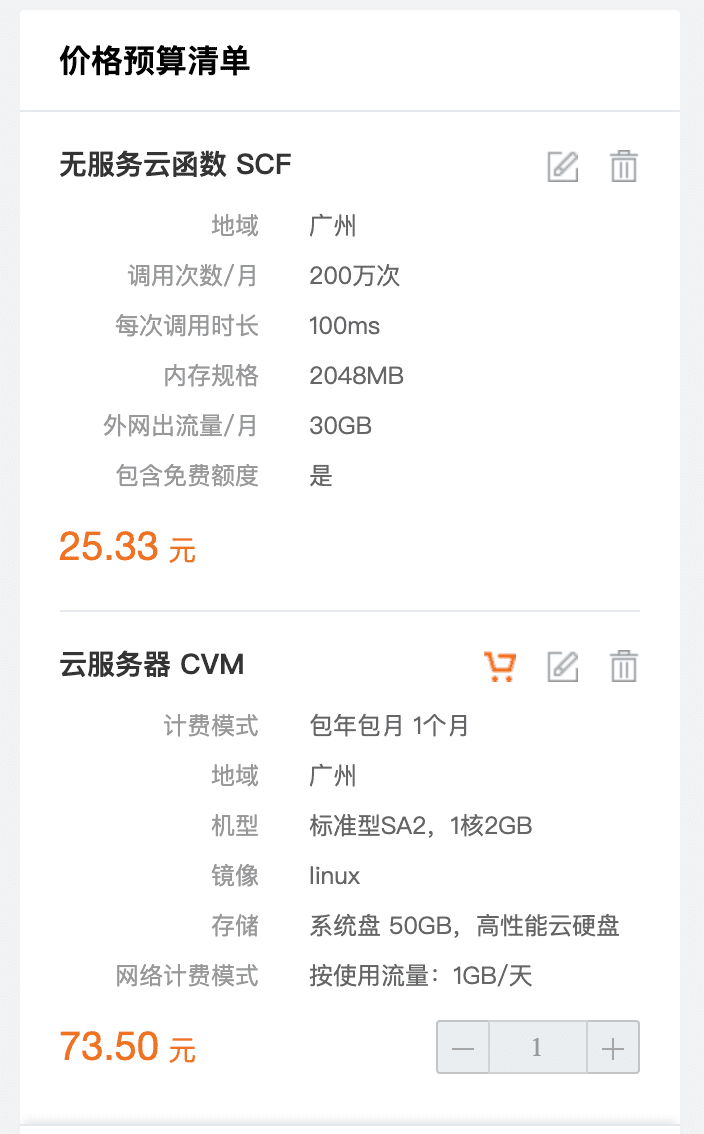 </center>
</center> 对比分析
从单用户访问页面性能表现来看 Serverless 方案略逊于服务器方案,但是页面性能指标是可以优化的。从压测来看,虽然 Serverless 的 平均响应时间 略大于 CVM,但是 最大响应时间 和 P95 耗时 均优于 CVM 很多,CVM 的最大响应时间甚至接近 Serverless 的 3 倍。而且当并发量逐渐增大时,CVM 的响应时间变化明显,而且越来越大,而 Serverless 则表现平稳,除了极个别的冷启动,基本能在 200ms 以内。
由此可以看出,随着并发的增加,SSR 会导致服务器负荷越来越大,从而会加大服务器的响应时间;而 Serverless 由于具有自动扩缩的能力,所以相对比较平稳。
当然由于测试条件有限,可能会有考虑不够全面的地方,但是从压测图形来看,是完全符合理论预期的。
但是从价格对比来看,接近配置的 Serverless 方案基本不怎么花钱,甚至很多时候,免费额度就已经可以满足需求了,这里为了增加 Serverless 费用,估计调大了调用次数,内存大小,但是即便如此,服务器方案还是接近 Serverless 方案的 10 倍!!!!!。
最后
写到这,作为一名前端开发,我的内心是无比激动的。记得以前在项目中为了优化首屏时间和 SEO,就做个好几个方案的对比,但是最终因为公司运维团队的不够配合,最后放弃了 SSR,最后选择了前端可掌控的 预渲染方案。现在有了 Serverless,前端终于不用受运维的限制,可以基于 Serverless 来大胆的尝试 SSR 。而且借助 Serverless,前端还可以做的更多。
当然真正的 SSR 并不止如此,要达到页面极致体验我们还需要做很多工作,比如:
- 静态资源部署到 CDN
- 页面缓存
- 降级处理
- ...
但是这些无论是部署到服务器还是 Serverless,都是我们需要做的工作。并不会成为我们将 SSR 部署到 Serverless 的绊脚石。
如果你对 Serverless Component 开发感兴趣,欢迎一起学习讨论。
欢迎访问:Serverless 中文网
]]>这次看上了腾讯家的云函数,主要是国内的厂有国内的节点,可以做一些事情。
直接跑 lambda 的版本是跑不起来的,只能自己重新编译了个 chromium,终于可以用了,项目在这儿,有这需求的可以来看看,点个星星什么的
]]>API 网关触发器实现 Websocket
WebSocket 协议是基于 TCP 的一种新的网络协议。它实现了浏览器与服务器全双工 (full-duplex) 通信,即允许服务器主动发送信息给客户端。WebSocket 在服务端有数据推送需求时,可以主动发送数据至客户端。而原有 HTTP 协议的服务端对于需推送的数据,仅能通过轮询或 long poll 的方式来让客户端获得。
由于云函数是无状态且以触发式运行,即在有事件到来时才会被触发。因此,为了实现 WebSocket,云函数 SCF 与 API 网关相结合,通过 API 网关承接及保持与客户端的连接。您可以认为云函数与 API 网关一起实现了服务端。当客户端有消息发出时,会先传递给 API 网关,再由 API 网关触发云函数执行。当服务端云函数要向客户端发送消息时,会先由云函数将消息 POST 到 API 网关的反向推送链接,再由 API 网关向客户端完成消息的推送。
具体的实现架构如下:

对于 WebSocket 的整个生命周期,主要由以下几个事件组成:
- 连接建立:客户端向服务端请求建立连接并完成连接建立;
- 数据上行:客户端通过已经建立的连接向服务端发送数据;
- 数据下行:服务端通过已经建立的连接向客户端发送数据;
- 客户端断开:客户端要求断开已经建立的连接;
- 服务端断开:服务端要求断开已经建立的连接。
对于 WebSocket 整个生命周期的事件,云函数和 API 网关的处理过程如下:
- 连接建立:客户端与 API 网关建立 WebSocket 连接,API 网关将连接建立事件发送给 SCF ;
- 数据上行:客户端通过 WebSocket 发送数据,API 网关将数据转发送给 SCF ;
- 数据下行:SCF 通过向 API 网关指定的推送地址发送请求,API 网关收到后会将数据通过 WebSocket 发送给客户端;
- 客户端断开:客户端请求断开连接,API 网关将连接断开事件发送给 SCF ;
- 服务端断开:SCF 通过向 API 网关指定的推送地址发送断开请求,API 网关收到后断开 WebSocket 连接。
因此,云函数与 API 网关之间的交互,需要由 3 类云函数来承载:
- 注册函数:在客户端发起和 API 网关之间建立 WebSocket 连接时触发该函数,通知 SCF WebSocket 连接的 secConnectionID 。通常会在该函数记录 secConnectionID 到持久存储中,用于后续数据的反向推送;
- 清理函数:在客户端主动发起 WebSocket 连接中断请求时触发该函数,通知 SCF 准备断开连接的 secConnectionID 。通常会在该函数清理持久存储中记录的该 secConnectionID ;
- 传输函数:在客户端通过 WebSocket 连接发送数据时触发该函数,告知 SCF 连接的 secConnectionID 以及发送的数据。通常会在该函数处理业务数据。例如,是否将数据推送给持久存储中的其他 secConnectionID 。
Websocket 功能实现
根据腾讯云官网提供的该功能的整体架构图:

这里我们可以使用对象存储 COS 作为持久化的方案,当用户建立链接存储 ConnectionId 到 COS 中,当用户断开连接删除该链接 ID 。
其中注册函数:
# -*- coding: utf8 -*- import os from qcloud_cos_v5 import CosConfig from qcloud_cos_v5 import CosS3Client bucket = os.environ.get('bucket') region = os.environ.get('region') secret_id = os.environ.get('secret_id') secret_key = os.environ.get('secret_key') cosClient = CosS3Client(CosConfig(Region=region, SecretId=secret_id, SecretKey=secret_key)) def main_handler(event, context): print("event is %s" % event) cOnnectionID= event['websocket']['secConnectionID'] retmsg = {} retmsg['errNo'] = 0 retmsg['errMsg'] = "ok" retmsg['websocket'] = { "action": "connecting", "secConnectionID": connectionID } cosClient.put_object( Bucket=bucket, Body='websocket'.encode("utf-8"), Key=str(connectionID), EnableMD5=False ) return retmsg 传输函数:
# -*- coding: utf8 -*- import os import json import requests from qcloud_cos_v5 import CosConfig from qcloud_cos_v5 import CosS3Client bucket = os.environ.get('bucket') region = os.environ.get('region') secret_id = os.environ.get('secret_id') secret_key = os.environ.get('secret_key') cosClient = CosS3Client(CosConfig(Region=region, SecretId=secret_id, SecretKey=secret_key)) sendbackHost = os.environ.get("url") def Get_ConnectionID_List(): respOnse= cosClient.list_objects( Bucket=bucket, ) return [eve['Key'] for eve in response['Contents']] def send(connectionID, data): retmsg = {} retmsg['websocket'] = {} retmsg['websocket']['action'] = "data send" retmsg['websocket']['secConnectionID'] = connectionID retmsg['websocket']['dataType'] = 'text' retmsg['websocket']['data'] = data requests.post(sendbackHost, json=retmsg) def main_handler(event, context): print("event is %s" % event) connectionID_List = Get_ConnectionID_List() cOnnectionID= event['websocket']['secConnectionID'] count = len(connectionID_List) data = event['websocket']['data'] + "(===Online people:" + str(count) + "===)" for ID in connectionID_List: if ID != connectionID: send(ID, data) return "send success" 清理函数:
# -*- coding: utf8 -*- import os import requests from qcloud_cos_v5 import CosConfig from qcloud_cos_v5 import CosS3Client bucket = os.environ.get('bucket') region = os.environ.get('region') secret_id = os.environ.get('secret_id') secret_key = os.environ.get('secret_key') cosClient = CosS3Client(CosConfig(Region=region, SecretId=secret_id, SecretKey=secret_key)) sendbackHost = os.environ.get("url") def main_handler(event, context): print("event is %s" % event) cOnnectionID= event['websocket']['secConnectionID'] retmsg = {} retmsg['websocket'] = {} retmsg['websocket']['action'] = "closing" retmsg['websocket']['secConnectionID'] = connectionID requests.post(sendbackHost, json=retmsg) cosClient.delete_object( Bucket=bucket, Key=str(connectionID), ) return event Yaml 文件如下:
Conf: component: "serverless-global" inputs: region: ap-guangzhou bucket: chat-cos-1256773370 secret_id: secret_key: myBucket: component: '@serverless/tencent-cos' inputs: bucket: ${Conf.bucket} region: ${Conf.region} restApi: component: '@serverless/tencent-apigateway' inputs: region: ${Conf.region} protocols: - http - https serviceName: ChatDemo environment: release endpoints: - path: / method: GET protocol: WEBSOCKET serviceTimeout: 800 function: transportFunctionName: ChatTrans registerFunctionName: ChatReg cleanupFunctionName: ChatClean ChatReg: component: "@serverless/tencent-scf" inputs: name: ChatReg codeUri: ./code handler: reg.main_handler runtime: Python3.6 region: ${Conf.region} environment: variables: region: ${Conf.region} bucket: ${Conf.bucket} secret_id: ${Conf.secret_id} secret_key: ${Conf.secret_key} url: http://set-gwm9thyc.cb-guangzhou.apigateway.tencentyun.com/api-etj7lhtw ChatTrans: component: "@serverless/tencent-scf" inputs: name: ChatTrans codeUri: ./code handler: trans.main_handler runtime: Python3.6 region: ${Conf.region} environment: variables: region: ${Conf.region} bucket: ${Conf.bucket} secret_id: ${Conf.secret_id} secret_key: ${Conf.secret_key} url: http://set-gwm9thyc.cb-guangzhou.apigateway.tencentyun.com/api-etj7lhtw ChatClean: component: "@serverless/tencent-scf" inputs: name: ChatClean codeUri: ./code handler: clean.main_handler runtime: Python3.6 region: ${Conf.region} environment: variables: region: ${Conf.region} bucket: ${Conf.bucket} secret_id: ${Conf.secret_id} secret_key: ${Conf.secret_key} url: http://set-gwm9thyc.cb-guangzhou.apigateway.tencentyun.com/api-etj7lhtw 注意,这里需要先部署 API 网关。当部署完成,获得回推地址,将回推地址以 url 的形式写入到对应函数的环境变量中:

理论上应该是可以通过 ${restApi.url[0].internalDomain} 自动获得到 url 的,但是我并没有成功获得到这个 url,只能先部署 API 网关,获得到这个地址之后,再重新部署。
部署完成之后,我们可以编写 HTML 代码,实现可视化的 Websocket Client,其核心的 Javascript 代码为:
window.Onload= function () { var conn; var msg = document.getElementById("msg"); var log = document.getElementById("log"); function appendLog(item) { var doScroll = log.scrollTop === log.scrollHeight - log.clientHeight; log.appendChild(item); if (doScroll) { log.scrollTop = log.scrollHeight - log.clientHeight; } } document.getElementById("form").Onsubmit= function () { if (!conn) { return false; } if (!msg.value) { return false; } conn.send(msg.value); //msg.value = ""; var item = document.createElement("div"); item.innerText = "发送↑:"; appendLog(item); var item = document.createElement("div"); item.innerText = msg.value; appendLog(item); return false; }; if (window["WebSocket"]) { //替换为 websocket 连接地址 cOnn= new WebSocket("ws://service-01era6ni-1256773370.gz.apigw.tencentcs.com/release/"); conn.Onclose= function (evt) { var item = document.createElement("div"); item.innerHTML = "<b>Connection closed.</b>"; appendLog(item); }; conn.Onmessage= function (evt) { var item = document.createElement("div"); item.innerText = "接收↓:"; appendLog(item); var messages = evt.data.split('\n'); for (var i = 0; i < messages.length; i++) { var item = document.createElement("div"); item.innerText = messages[i]; appendLog(item); } }; } else { var item = document.createElement("div"); item.innerHTML = "<b>Your browser does not support WebSockets.</b>"; appendLog(item); } }; 完成之后,我们打开两个页面,进行测试:

总结
通过云函数 + API 网关进行 Websocket 的实践,绝对不仅仅是一个聊天工具这么简单,它可以用在很多方面,例如通过 Websocket 进行实时日志系统的制作等。
单独的函数计算,仅仅是一个计算平台,只有和周边的 BaaS 结合,才能展示出 Serverless 架构的价值和真正的能力。这也是为什么很多人说 Serverless=FaaS+BaaS 的一个原因。
期待更多小伙伴,可以通过 Serverless 架构,创造出更多有趣的应用。
欢迎访问:Serverless 中文社区
]]>随着各种社交论坛的日益火爆,敏感词过滤逐渐成为了非常重要的功能。那么在 Serverless 架构下,利用 Python 语言,敏感词过滤又有那些新的实现呢?我们能否用最简单的方法实现一个敏感词过滤的 API 呢?
了解敏感过滤的几种方法
Replace 方法
敏感词过滤,其实在一定程度上是文本替换,以 Python 为例,我们可以通过 replace 来实现,首先准备一个敏感词库,然后通过 replace 进行敏感词替换:
def worldFilter(keywords, text): for eve in keywords: text = text.replace(eve, "***") return text keywords = ("关键词 1", "关键词 2", "关键词 3") cOntent= "这是一个关键词替换的例子,这里涉及到了关键词 1 还有关键词 2,最后还会有关键词 3 。" print(worldFilter(keywords, content)) 这种方法虽然操作简单,但是存在一个很大的问题:在文本和敏感词汇非常庞大的情况下,会出现很严重的性能问题。
举个例子,我们先修改代码进行基本的性能测试:
import time def worldFilter(keywords, text): for eve in keywords: text = text.replace(eve, "***") return text keywords =[ "关键词" + str(i) for i in range(0,10000)] cOntent= "这是一个关键词替换的例子,这里涉及到了关键词 1 还有关键词 2,最后还会有关键词 3 。" * 1000 startTime = time.time() worldFilter(keywords, content) print(time.time()-startTime) 此时的输出结果是:0.12426114082336426,可以看到性能非常差。
正则表达方法
相较于 replace,使用正则表达 re.sub 实现可能更加快速。
import time import re def worldFilter(keywords, text): return re.sub("|".join(keywords), "***", text) keywords =[ "关键词" + str(i) for i in range(0,10000)] cOntent= "这是一个关键词替换的例子,这里涉及到了关键词 1 还有关键词 2,最后还会有关键词 3 。" * 1000 startTime = time.time() worldFilter(keywords, content) print(time.time()-startTime) 增加性能测试之后,我们按照上面的方法进行改造测试,输出结果是 0.24773502349853516。
对比这两个例子,我们会发现当前两种方法的性能差距不是很大,但是随着文本数量的增加,正则表达的优势会逐渐凸显,性能提升明显。
DFA 过滤敏感词
相对来说,DFA 过滤敏感词的效率会更高一些,例如我们把坏人、坏孩子、坏蛋作为敏感词,那么它们的树关系可以这样表达:

而 DFA 字典是这样表示的:
{ '坏': { '蛋': { '\x00': 0 }, '人': { '\x00': 0 }, '孩': { '子': { '\x00': 0 } } } } 使用这种树表示问题最大的好处就是可以降低检索次数、提高检索效率。其基本代码实现如下:
import time class DFAFilter(object): def __init__(self): self.keyword_chains = {} # 关键词链表 self.delimit = '\x00' # 限定 def parse(self, path): with open(path, encoding='utf-8') as f: for keyword in f: chars = str(keyword).strip().lower() # 关键词英文变为小写 if not chars: # 如果关键词为空直接返回 return level = self.keyword_chains for i in range(len(chars)): if chars[i] in level: level = level[chars[i]] else: if not isinstance(level, dict): break for j in range(i, len(chars)): level[chars[j]] = {} last_level, last_char = level, chars[j] level = level[chars[j]] last_level[last_char] = {self.delimit: 0} break if i == len(chars) - 1: level[self.delimit] = 0 def filter(self, message, repl="*"): message = message.lower() ret = [] start = 0 while start < len(message): level = self.keyword_chains step_ins = 0 for char in message[start:]: if char in level: step_ins += 1 if self.delimit not in level[char]: level = level[char] else: ret.append(repl * step_ins) start += step_ins - 1 break else: ret.append(message[start]) break else: ret.append(message[start]) start += 1 return ''.join(ret) gfw = DFAFilter() gfw.parse( "./sensitive_words") cOntent= "这是一个关键词替换的例子,这里涉及到了关键词 1 还有关键词 2,最后还会有关键词 3 。" * 1000 startTime = time.time() result = gfw.filter(content) print(time.time()-startTime) 这里的字典库是:
with open("./sensitive_words", 'w') as f: f.write("\n".join( [ "关键词" + str(i) for i in range(0,10000)])) 执行结果:
0.06450581550598145 从中,我们可以看到性能又进一步得到了提升。
AC 自动机过滤敏感词算法
什么是 AC 自动机?简单来说,AC 自动机就是字典树 +kmp 算法 + 失配指针,一个常见的例子就是给出 n 个单词,再给出一段包含 m 个字符的文章,让你找出有多少个单词在文章里出现过。
代码实现:
import time class Node(object): def __init__(self): self.next = {} self.fail = None self.isWord = False self.word = "" class AcAutomation(object): def __init__(self): self.root = Node() # 查找敏感词函数 def search(self, content): p = self.root result = [] currentposition = 0 while currentposition < len(content): word = content[currentposition] while word in p.next == False and p != self.root: p = p.fail if word in p.next: p = p.next[word] else: p = self.root if p.isWord: result.append(p.word) p = self.root currentposition += 1 return result # 加载敏感词库函数 def parse(self, path): with open(path, encoding='utf-8') as f: for keyword in f: temp_root = self.root for char in str(keyword).strip(): if char not in temp_root.next: temp_root.next[char] = Node() temp_root = temp_root.next[char] temp_root.isWord = True temp_root.word = str(keyword).strip() # 敏感词替换函数 def wordsFilter(self, text): """ :param ah: AC 自动机 :param text: 文本 :return: 过滤敏感词之后的文本 """ result = list(set(self.search(text))) for x in result: m = text.replace(x, '*' * len(x)) text = m return text acAutomation = AcAutomation() acAutomation.parse('./sensitive_words') startTime = time.time() print(acAutomation.wordsFilter("这是一个关键词替换的例子,这里涉及到了关键词 1 还有关键词 2,最后还会有关键词 3 。"*1000)) print(time.time()-startTime) 词库同样是:
with open("./sensitive_words", 'w') as f: f.write("\n".join( [ "关键词" + str(i) for i in range(0,10000)])) 使用上面的方法,测试结果为 0.017391204833984375。
敏感词过滤方法小结
根据上文的测试对比,我们可以发现在所有算法中,DFA 过滤敏感词性能最高,但是在实际应用中,DFA 过滤和 AC 自动机过滤各自有自己的适用场景,可以根据具体业务来选择。
实现敏感词过滤 API
想要实现敏感词过滤 API,就需要将代码部署到 Serverless 架构上,选择 API 网关与函数计算进行结合。以 AC 自动机过滤敏感词算法为例:我们只需要增加是几行代码就好:
# -*- coding:utf-8 -*- import json, uuid class Node(object): def __init__(self): self.next = {} self.fail = None self.isWord = False self.word = "" class AcAutomation(object): def __init__(self): self.root = Node() # 查找敏感词函数 def search(self, content): p = self.root result = [] currentposition = 0 while currentposition < len(content): word = content[currentposition] while word in p.next == False and p != self.root: p = p.fail if word in p.next: p = p.next[word] else: p = self.root if p.isWord: result.append(p.word) p = self.root currentposition += 1 return result # 加载敏感词库函数 def parse(self, path): with open(path, encoding='utf-8') as f: for keyword in f: temp_root = self.root for char in str(keyword).strip(): if char not in temp_root.next: temp_root.next[char] = Node() temp_root = temp_root.next[char] temp_root.isWord = True temp_root.word = str(keyword).strip() # 敏感词替换函数 def wordsFilter(self, text): """ :param ah: AC 自动机 :param text: 文本 :return: 过滤敏感词之后的文本 """ result = list(set(self.search(text))) for x in result: m = text.replace(x, '*' * len(x)) text = m return text def response(msg, error=False): return_data = { "uuid": str(uuid.uuid1()), "error": error, "message": msg } print(return_data) return return_data acAutomation = AcAutomation() path = './sensitive_words' acAutomation.parse(path) def main_handler(event, context): try: sourceCOntent= json.loads(event["body"])["content"] return response({ "sourceContent": sourceContent, "filtedContent": acAutomation.wordsFilter(sourceContent) }) except Exception as e: return response(str(e), True) 最后,为了方便本地测试,我们可以再增加以下代码:
def test(): event = { "requestContext": { "serviceId": "service-f94sy04v", "path": "/test/{path}", "httpMethod": "POST", "requestId": "c6af9ac6-7b61-11e6-9a41-93e8deadbeef", "identity": { "secretId": "abdcdxxxxxxxsdfs" }, "sourceIp": "14.17.22.34", "stage": "release" }, "headers": { "Accept-Language": "en-US,en,cn", "Accept": "text/html,application/xml,application/json", "Host": "service-3ei3tii4-251000691.ap-guangzhou.apigateway.myqloud.com", "User-Agent": "User Agent String" }, "body": "{\"content\":\"这是一个测试的文本,我也就呵呵了\"}", "pathParameters": { "path": "value" }, "queryStringParameters": { "foo": "bar" }, "headerParameters": { "Refer": "10.0.2.14" }, "stageVariables": { "stage": "release" }, "path": "/test/value", "queryString": { "foo": "bar", "bob": "alice" }, "httpMethod": "POST" } print(main_handler(event, None)) if __name__ == "__main__": test() 完成之后,就可以进行测试运行,例如我的字典是:
呵呵 测试 执行之后结果:
{'uuid': '9961ae2a-5cfc-11ea-a7c2-acde48001122', 'error': False, 'message': {'sourceContent': '这是一个测试的文本,我也就呵呵了', 'filtedContent': '这是一个**的文本,我也就**了'}} 接下来,我们将代码部署到云端,新建 serverless.yaml:
sensitive_word_filtering: component: "@serverless/tencent-scf" inputs: name: sensitive_word_filtering codeUri: ./ exclude: - .gitignore - .git/** - .serverless - .env handler: index.main_handler runtime: Python3.6 region: ap-beijing description: 敏感词过滤 memorySize: 64 timeout: 2 events: - apigw: name: serverless parameters: environment: release endpoints: - path: /sensitive_word_filtering description: 敏感词过滤 method: POST enableCORS: true param: - name: content position: BODY required: 'FALSE' type: string desc: 待过滤的句子 然后通过 sls --debug 进行部署,部署结果:

最后,通过 PostMan 进行测试:

总结
敏感词过滤是当前企业的普遍需求,通过敏感词过滤,我们可以在一定程度上遏制恶言恶语和违规言论的出现。在具体实现过程中,有两个方面需要额外主要:
-
敏感词库的获得问题:Github 上有很多敏感词库,其中包含了各种场景中的敏感词,大家可以自行搜索下载使用;
-
API 使用场景的问题:我们可以将这个 API 放置在社区跟帖系统、留言评论系统或者是博客发布系统中,这样可以防止出现敏感词汇,减少不必要的麻烦。
欢迎访问:Serverless 中文网
]]>- 依赖库安装和本地调试成功,但在云端部署为何失败?
- Serverless 应用内部的监控,无法直接查看,每次定位问题的流程好长啊!
- 怎样组织 Serverless 应用?
- 不同的函数之间的调用关系、环境划分、资源的管理及权限控制是怎样的呢?
近期 Serverless 团队发布了一款里程碑新特性产品,产品通过支持应用级别监控和 Dashboard 资源管理,有效解决小伙伴们的痛点问题,一起来看看吧!
Serverless Dashboard 新特性
1. 应用管理
本次发布的应用管理页面则以 Component 为粒度,聚合了所有 Serverless Framework 部署的资源,并且展示了实例状态、访问链接以及上次的部署信息。此外,在管理详情中还支持删除 Serverless 应用、下载项目代码进行二次开发等操作,开发者可以更方便、集中的管理账号下的 Serverless 应用。如下图所示:

2. 部署详情及输出
Serverless Framework 的特性之一就是可以便捷的联动关联的云上资源,因此不同的 Serverless Component,可能会联动不同的云上资源,如网关、云函数、COS 等。相信许多小伙伴在进行二次开发时,都想要了解每个 Component 具体创建了的资源信息。
在本次发布的部署详情页中,不仅可以查看到 Serverless 实例的基本信息,还可以在输出( output )页面中查看到 Serverless Component 对应的输入、输出信息。通过该页面,可以查看到对应的资源配置,如:地域信息、资源 id 、使用的语言环境、支持的协议信息等。有了这个页面,可以直观的看到对应的资源配置,再也不担心不同应用之间搞混配置啦。

3. 应用级别监控
当前 Serverless Framework 已经支持了多种 Web 框架的一键部署。在部署完毕后,相信许多开发者会希望查看到基于应用级别的监控数据。而这往往在基础资源的监控中是难以体现出来的。
那么本次发布最为亮眼的能力,即支持了应用级别的监控页面,实现了”0“配置的监控指标展示。当前已经支持 Express.js Component 的应用级别监控。无需去多个产品的控制台查看监控,无需自助上报数据,无需借助第三方 APM 插件,只需一次部署,立刻查看 Express 应用的监控信息!
当前的 Express.js 组件监控主要支持下列指标:
- 函数触发次数 /错误次数:function invocations & errors
- 函数延迟:function latency
- API 请求次数 /错误次数:api requests & errors
- API 请求延迟:api latency
- API 5xx 错误次数:api 5xx errors
- API 4xx 错误次数:api 4xx errors
- API 错误次数统计:api errors
- 不同路径下 API 的请求方法、请求次数和平均延迟统计:api path requests

由于 Serverless Dashboard 是基于新版的 Serverless Component 开发,因此同样支持新版 Serverless Component 的特性:
- [门槛低] 交互式的一键部署指引:对于新用户而言,只需要在终端输入 serverless 命令,即可按照引导快速部署一个 Express 或 静态网站应用。
- [部署快] 将一个 Express.js 应用部署到云端只需要 5-6s 的时间,使本地和云端代码可以顺畅、快速同步。
- [可复用] 支持云端注册中心,每位开发者都可以贡献自己的组件到注册中心中,便于团队进行复用。
- [实时日志查看] 支持部署阶段实时输出请求日志、错误等信息,此外支持检测本地代码变化并自动部署云端,方便的进行云端代码开发。
- [云端调试] 针对 Node.js 应用,支持一键开启云端 debug 能力,对云端代码打断点调试,真正实现了在云端进行开发和调试的能力,无需考虑本地环境和远端环境的不一致问题。
- [状态共享] 通过云端部署引擎存储应用部署状态,便于账号和团队之间共享资源,协作开发。
针对 Express.js 框架的应用级别监控主要基于腾讯云自定义监控能力实现。在部署过程中,框架中使用 Serverless SDK,收集应用级别的监控信息进行自定义上报和展示。因此用户可以做到 “0”配置 查看应用级别监控指标。真正实现快速部署一个开箱即用的 Serverless 应用框架。
下面让我带大家一起实战体验一下我们的新产品吧!
玩转 Dashboard 使用实战
本次实战,我们将通过一个 Express.js 框架的部署,来体验 最新发布的 Dashboard 应用管理、监控视图等能力。
首先,点击 Express 链接,扫码,登录腾讯云账号授权,一键部署你的 Express 应用。
完成后,可以看到如下图所示:

你的 Express 应用已经部署好了!
等待几分钟,就可以在 Dashboard 上看到对应的监控数据啦!
如下图所示:

当前支持 15 分钟,60 分钟,24 小时和 7 天的监控数据。
如果您希望进行二次开发,则在本地安装 Serverless Framework,并点击右上角的[下载项目代码],对代码进行修改和部署。 参考:更多文档资料