
我记得搜索引擎是有所谓的分词规则的,能不能在取昵称的时候利用到分词规则,如取名为“我和动物”,这样搜索引擎就会把这个昵称分为“我”、“和”、“动物”,并主动把“和”这个单词丢掉。
请问这样是否可行?还有没有其他办法可以防止搜索引擎收录自己的各平台信息?
]]>site: v2ex.com mysql
关键词排除 keyword -keyword
and 且
MySQL db design and index -csdn
or 或
MySQL db design or index -csdn
文件类型
数据库设计 filetype: pdf
数据库设计 ext:pdf
日期
leetcode site: github.com after: 2021
before: 2021
2021..2023
url 搜索
algorithm and data structure inurl:blog
inurl: gitbook
text 搜索
intext: mysql performance
我想请教的是你们要学一个东西或者找到你想要的且质量高的文章或者博客是用的什么关键字
你们是用的什么关键字或者技巧找到高质量的文章或者有趣的东西
谢谢大家。
推荐我觉得高质量的文章
]]>源自 sphinx 支持 Realtime 索引、indexer from mysql 。兼容 es 的 json 搜索,兼容 mysql 协议和基本 sql 语法子查询等。
性能目前在用很好。中文友好。资源占用很小。中小项目觉得挺适合的。
]]>如果是自己玩,应该是 Milvus 好一些, 但是他们数据处理流程是怎么样的呢?
假设有 1000 篇文章在 mysql 中,存在显示不显示状态。
如果导入 es 中,就可以实现分词搜索,但是这时候搜索比较笨。
看 Milvus 可以实现 类似拆字意图搜素, 我是用 Milvus 然后拆词,然后呢。。
用了 Milvus 是不是就不用用 es 了,还是和 es 搭配使用,具体方面呢。
我只会 es 分词搜索,es 日志使用, 对搜索方面又些兴趣, 但是越了解越乱。请大佬指点.
]]>- 清理谷歌浏览器的缓存,修改隐私政策(有账号)
- 更换浏览器为火狐(无账号)
- 更换设备(电脑→手机)更换浏览器( brave )(无账号,无使用记录)
- 更换同款双脚长凳🪜ip
- 更换其他双脚长凳
结果跟我开始搜索到的结果几乎都一样,这里有几个问题:
- 这是被谷歌用户分类了吗?还是被精确定位了?如果是后者,感觉有点细思极恐,在终端存在差异化环境情况下,谷歌是怎么定位到请求是来自“同个局域网”网络设备的?
- 大概率是什么原因导致这种搜索结果差异的?哪个环节被锁定?运营商?域名解析?或者说谷歌同过某种本地运算让不同环境的请求带上同个 key?
- 如何避免这种情况
PS:哈哈,如果问得不好或是我无知,大家尽管吐槽,谢谢大家回复!
]]>
-
是我搜索的姿势不对,还是别人的 seo 做的好,或者说是搜索引擎做的不够好?
-
PS:大家平时使用搜索引擎时,有哪些 tips 可以分享的?谢谢大家!
但是如果搜一些不存在但是又敏感的关键字,就会出现广告内容,比如搜索 site:chuangye.sjtu.edu.cn 污, 出现这种内容:
求解是什么原因呢,如何防止呢?感谢!
]]>https://dkb.io/post/google-search-is-dying
Google search 里 SEO 或者 Ads 太多了
大家干脆 search Reddit, 或者 Google xxx Reddit
大家之前讨论的 SEO 影响 搜索结果... 其实国外也一样啊
看来 Reddit 成最大赢家, Baidu 贴吧 确实是好牌打烂了
用谷歌搜索了一下却搜到了 https://imgchr.com/i/yJxR0g
谷歌爬虫的收录速度这么快的嘛,一天前的帖子就收录了 https://imgchr.com/i/yJzCjK
]]>不排除算法错误导致
例:
https://www.baidu.com/s?wd=%E6%96%AD%E5%8D%A1%E8%A1%8C%E5%8A%A8
所有搜索内容均为百家号,屏蔽了其他网站
https://www.baidu.com/s?wd=%E6%96%AD%E5%8D%A1%E8%A1%8C%E5%8A%A8+-baijiahao
-baijiahao 后内容正常 ]]>
当前想法:的方案是 elasticsearch,分词的话找个 python 库处理一下,有点像个迷你的搜索引擎,但不确定是否需要那么重量级的工具。
请教:有什么简单又直接又省运维成本的方案?非工作项目,所以全部上云,能不要内存型数据库就不要,能上 serverless 就上 serverless,以降每个月成本压到最低。Java 独有的技术线上不了,Python 、Go 和 Javascript ( Node )都可以。谢。
]]>
dogedoge:
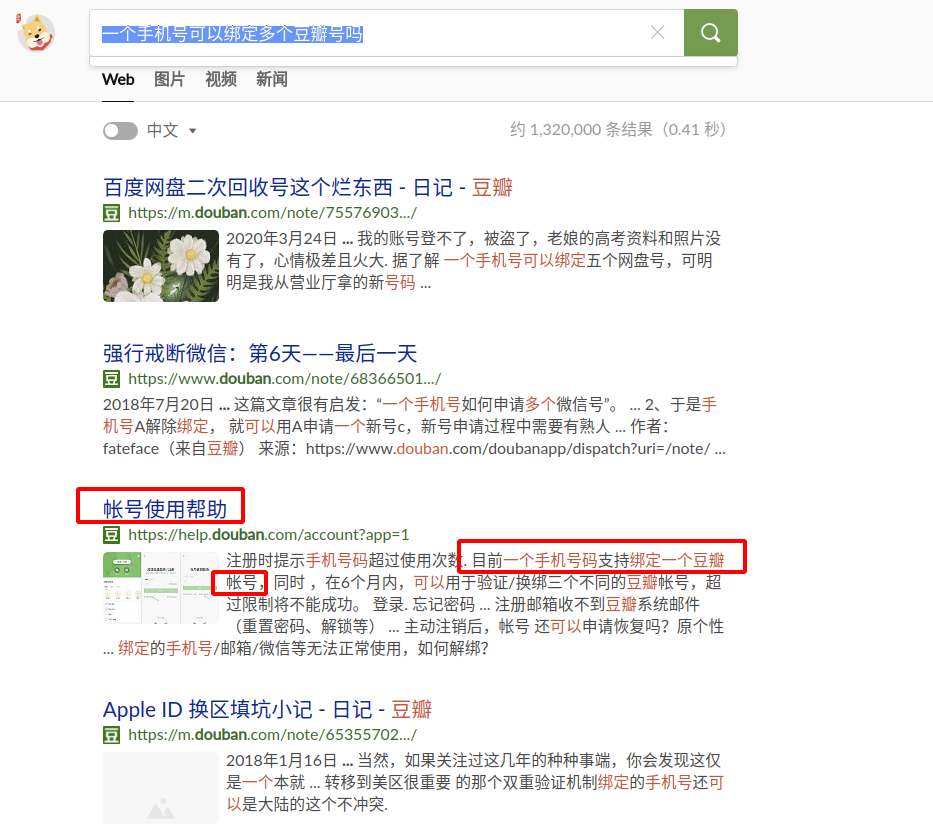
baidu:
注:没有利益相关
]]>因为有几十万个词,不奢求全自动化处理完全部的词。
希望有一个策略告知如何分类出来。
目前我已经处理的是:
导航词这个比较容易处理,就是别人品牌词,自己品牌词,之类的。好处理,但是没有策略自动化处理
事务搜索词,目前我用了价格词处理了一波
信息搜索词,还没有想到招怎么处理。
弱弱的问问各个大大如何处理
]]>一张用户标签表(用户 ID, 标签 ID)
一张用户表(用户 ID, 手机号, 微信 openid, 邮件...)
都是 MySQL 表,并且结构固定,数据的维护是别的系统同步(每天会同步一次,用户也可手动同步)
大概 500W 以下的人,几百上千的标签.
要实现:使用标签组成组(标签与标签交集或并集),再使用组组成包(组与组加法或减法),前端界面在组成组或包的过程中,后端实时提供组或包的人群数量.并且人群包创建好之后会发送各种消息(短信,微信等).
我的问题:
- 怎么样能实时提供人群数量
- 我该怎样存储组和包数据,什么样的结构,以方便我发送消息
- 有什么解决方案,用什么样的工具
欢迎拍砖交流,爬虫和后端接口开发使用的是 nodejs,前端使用的是 angular 8,有感兴趣的同学吗?
]]>一个好的搜索引擎,应该是既考虑用户搜索体验又照顾各大中小网站生存的搜索引擎,只有各大中小网站生存下去了,才能有源源不断的搜索资源提供给用户搜索。如果一心只想把搜索资源弄成自家的站内搜索,迟早会出问题的。那如何才能把各个网站的优质内容提供给用户呢?其实现在的搜索引擎都有站长平台,只要好好利用这个平台,这些问题根本就不是个事。
各网站可以把网站提交到搜索资源(站长)平台并且认证通过后,把网站上的优质内容链接,提交到搜索平台上,搜索平台将按照内容质量、网站页面排版给予收录和排名,站长还可以在搜索资源(站长)平台管理已经提交过的文章内容链接。这样做比弄那个什么号强多了,那个什么号只适合自媒体平台,不适合搜索引擎;搜索引擎也可以建立自己的自媒体平台,但不能把自媒体和搜索混在一起。在这里特别需要提醒的是,在平台验证网站方面,最好通过 ftp 上传文件到根目录这种方式验证,因为很多网站有多人管理,为了防止一些员工自己在站长平台弄账号给网站验证所有权,在网页上放代码这种验证方式不提倡! ]]>