
打算借助 kafka 的持久化,把任务丢到 kafka 中
后台服务有多个节点,也就是多个节点在消费 kafka
怎么样才能做到串行消费 kafka 的消息呢?
就是说,多个节点排队消费,第一个节点拿到消息后,如果没处理完,其他节点不能继续消费
搞了好久都没实现
又不想用数据库存储然后定时读取的方式(这种方式肯定没问题)
想通过这个功能,学会 kakfa 的使用
请假一下各位大佬,基于 kafka 能不能实现这个想法呢?谢谢 ]]>
我目前有一个 Kafka 集群,包含两个 Kafka 服务器,它们共享同一个 Zookeeper 。集群中有两个主题:corpnet-requests 和 corpnet-responses ,这两个主题都有 3 个 partition 。
系统中有四个客户端:
Client A 和 Client B:订阅两个 Kafka 服务器上的 corpnet-requests 和 corpnet-responses 主题。这两个客户端负责生产包含 guid 、url 、payload 和 auth 的消息到 corpnet-requests 主题。
Client C 和 Client D:同样订阅两个 Kafka 服务器上的 corpnet-requests 和 corpnet-responses 主题。这两个客户端负责消费 corpnet-requests 主题中的消息,执行实际的 HTTP 请求,并将响应结果生产到 corpnet-responses 主题中。
Client A 和 Client B:除了生产请求消息外,还需要消费 corpnet-responses 主题中的消息,以获取实际的 HTTP 响应,完成一次请求的逻辑。
以上设计主要用于解决 Client A 和 B 无法访问公司内网资源的问题,公司内网无法通过 vpn 访问。
问题描述
由于 corpnet-requests 和 corpnet-responses 主题都有多个分区,我担心会出现以下冲突情况:
Client A生产的请求消息的响应(由Client C 或 Client D生成)可能会被Client B消费,反之亦然。
我的疑问
请教各位大佬如何确保每个请求的响应能够准确地返回给发起请求的客户端(即Client A的请求响应不会被Client B消费,反之亦然)。似乎通过 key 来限制 partition 或者规划消费者组都无法保证,当然也有可能是我学艺不精理解有误。。
欢迎大家提供解决方案或建议,谢谢!
]]>陆续也快有 100 个 star 了,虽然很少,但是也是对我的认可,感谢大家

重要版本 v0.20🎉
使用了全新的 icon ,代表更新的活力。
修复最小化后有时会无法放大的 bug
增加 [监控] 功能,配置好 topic 和组后,以图表显示积压信息,后续将会增加告警模块
更新记录
1 、重要:修复最小化后有时会无法放大的 bug
2 、重要:增加 [监控] 功能,配置好 topic 和组后,以图表显示积压信息,后续将会增加告警模块
3 、add: 将分区数改为按钮,取消主题按钮
4 、add: 去除下拉默认背景颜色
5 、add: 增加默认值
6 、fix:重要,修复最小化无法恢复的问题
7 、add: 基本完成监控系统
8 、fix: 修复 group 问题
9 、add:增加监控图表配置及存储
10 、add: 优化不同提示的区别
11 、更新 icon
github 下载地址: https://github.com/Bronya0/Kafka-King
]]>addauth digest admin:123456 setAcl / auth:admin:cdrwa 通过下方测试看到 zookeeper 的账号密码应是生效了
[root@local-test bin]# ./zookeeper-shell.sh localhost:2181 Connecting to localhost:2181 Welcome to ZooKeeper! JLine support is disabled WATCHER:: WatchedEvent state:SyncConnected type:None path:null ls / Insufficient permission : / addauth digest admin:123456 ls / [admin, brokers, cluster, config, consumers, controller, controller_epoch, feature, isr_change_notification, latest_producer_id_block, log_dir_event_notification, zookeeper] 可我未对 kafka 做任何修改,为什么 kafka 创建 topic 、生产、消费依旧正常?
理论上 zookeeper 作为服务端添加了认证,kafka 作为客户端也需要修改一些配置吗。很是奇怪。
PS:我用的是 kafka v3.6.0 版本,zookeeper 使用的是 kafka 安装包中内置的。
]]>- 执行失败了就原封不动发回原队列,但是这样在有大量失败的情况下或许会造成单队列压力特别大
- 创建一个专门的重试队列,任务失败了就发到这个重试队列,然后再写一个服务,把重试队列的数据定时吐到主队列,缺点是多了一个服务,不太好维护
- 写进 mysql 然后手动读,感觉 mysql 扛不住
- 用个屁的 kafka ,天天吹性能,但是性能高又怎么样,就是一根高性能水管子,DLQ 重试队列一个没有,还不如换 RabbitMQ 或者 RocketMQ 。喷归喷,但是之后调研发现 rabbit 性能感觉确实一般,RocketMQ 的话感觉脱离阿里云,自己手动搭很容易出问题。
还有没有其他实践可以分享?
]]>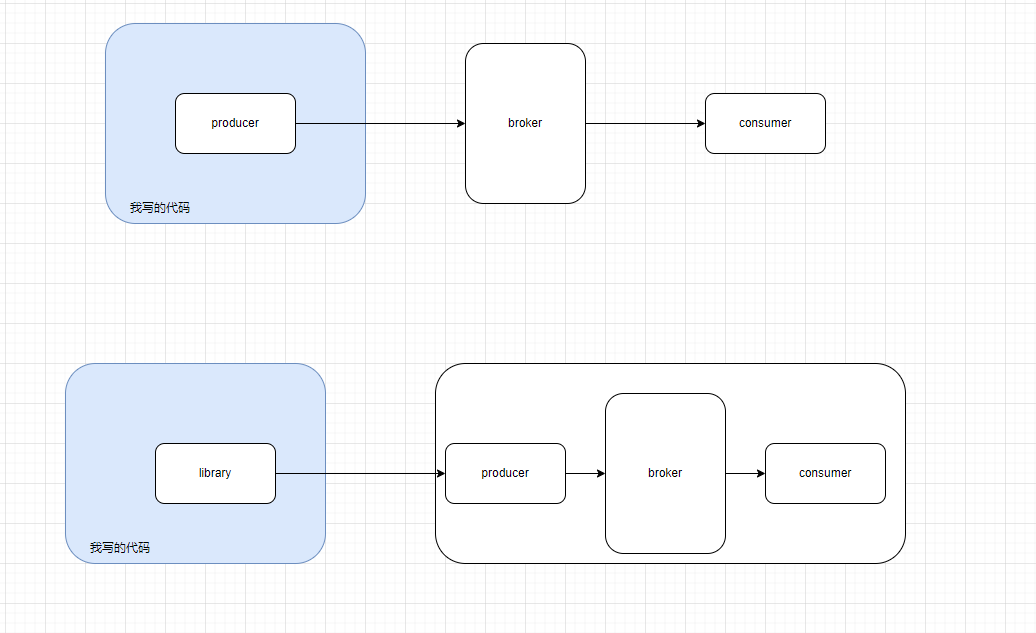 参考图片. producer 是和 broker 在一台物理设备上? 还是说只是一个 library, 被应用层代码调用, 然后负责和 broker 通信?
参考图片. producer 是和 broker 在一台物理设备上? 还是说只是一个 library, 被应用层代码调用, 然后负责和 broker 通信? 有此疑问是因为:
- kafka server 上有配置文件可以配置 producer (producer.properties)
- 根据链接 https://www.baeldung.com/java-kafka-send-large-message 似乎也可以在代码里配置 producer
还是说代码端和配置端都可以修改, 一个是动态的一个是静态的?
快问快答 不要太咬文嚼字 轻喷轻喷.
]]>场景是有很多小数据需要通过 kafka 发送,每条数据的量不到 1kb ,但是高峰期数量很多,这种情况下,小数据会不会影响 kafka 性能,需要把数据合并成数组,批量发送吗。kafka 在哪种情况下性能会好一些呢。
]]>Configured voter set: [1, 2] is different from the voter set read from the state file: [1]. Check if the quorum configuration is up to date, or wipe out the local state file if necessary 我是在 kafka/config/server.properties 新增加了一个 vote ,如下:
增加前:
controller.quorum.voters=1@10.20.74.57:9093 增加后:
controller.quorum.voters=1@10.20.74.57:9093,2@10.20.74.58:9093 然后再启动的时候就报错了,我该如何解决?
]]>这样报错, 因为 --offset latest 和 partition 必须同时指定. 要么都不指定.
]]>因为受网络原因约束不能直接访问集群,只能在服务器 192.168.30.160 上搭代理 试了两种配置方式
方式一: listen kafka bind *:9092 mode tcp balance roundrobin no option clitcpka timeout check 5s server kafka01 192.168.41.168:9092 check inter 5000 rise 2 fall 3 server kafka02 192.168.41.169:9092 check inter 5000 rise 2 fall 3 server kafka03 192.168.41.170:9092 check inter 5000 rise 2 fall 3 方式二: listen kafka bind *:9092 mode tcp balance roundrobin server kafka1 127.0.0.1:8881 check server kafka2 127.0.0.1:8883 check server kafka3 127.0.0.1:8885 check listen kafka01 bind *:8881 mode tcp server kafka1 192.168.41.168:9092 check listen kafka02 bind *:8883 mode tcp server kafka1 192.168.41.169:9092 check listen kafka03 bind *:8885 mode tcp server kafka1 192.168.41.170:9092 check kafka client 试过这两个配置,kafka01,kafka02,kafka03 都指向了 192.168.30.160 public final static String bootstrapServers = "kafka01:9092,kafka02:9092,kafka03:9092"; public final static String bootstrapServers = "kafka01:9092"; 网络测试 telnet 通, 代理和 host ping 也都通。 发送消息时报错 :
19:37:39.347 [main] INFO org.apache.kafka.clients.producer.ProducerConfig - ProducerConfig values: acks = -1 batch.size = 16384 bootstrap.servers = [kafka01:9092] buffer.memory = 33554432 client.dns.lookup = default client.id = compression.type = gzip connections.max.idle.ms = 3000 delivery.timeout.ms = 120000 enable.idempotence = false interceptor.classes = [] key.serializer = class org.apache.kafka.common.serialization.StringSerializer linger.ms = 500 max.block.ms = 60000 max.in.flight.requests.per.cOnnection= 5 max.request.size = 1048576 metadata.max.age.ms = 300000 metric.reporters = [] metrics.num.samples = 2 metrics.recording.level = INFO metrics.sample.window.ms = 30000 partitioner.class = class org.apache.kafka.clients.producer.internals.DefaultPartitioner receive.buffer.bytes = 32768 reconnect.backoff.max.ms = 1000 reconnect.backoff.ms = 50 request.timeout.ms = 10000 retries = 0 retry.backoff.ms = 100 sasl.client.callback.handler.class = null sasl.jaas.cOnfig= null sasl.kerberos.kinit.cmd = /usr/bin/kinit sasl.kerberos.min.time.before.relogin = 60000 sasl.kerberos.service.name = null sasl.kerberos.ticket.renew.jitter = 0.05 sasl.kerberos.ticket.renew.window.factor = 0.8 sasl.login.callback.handler.class = null sasl.login.class = null sasl.login.refresh.buffer.secOnds= 300 sasl.login.refresh.min.period.secOnds= 60 sasl.login.refresh.window.factor = 0.8 sasl.login.refresh.window.jitter = 0.05 sasl.mechanism = GSSAPI security.protocol = PLAINTEXT security.providers = null send.buffer.bytes = 131072 ssl.cipher.suites = null ssl.enabled.protocols = [TLSv1.2, TLSv1.1, TLSv1] ssl.endpoint.identification.algorithm = https ssl.key.password = null ssl.keymanager.algorithm = SunX509 ssl.keystore.location = null ssl.keystore.password = null ssl.keystore.type = JKS ssl.protocol = TLS ssl.provider = null ssl.secure.random.implementation = null ssl.trustmanager.algorithm = PKIX ssl.truststore.location = null ssl.truststore.password = null ssl.truststore.type = JKS transaction.timeout.ms = 60000 transactional.id = null value.serializer = class org.apache.kafka.common.serialization.StringSerializer 19:37:42.274 [kafka-producer-network-thread | producer-1] DEBUG org.apache.kafka.clients.producer.internals.Sender - [Producer clientId=producer-1] Starting Kafka producer I/O thread. 19:37:42.280 [kafka-producer-network-thread | producer-1] DEBUG org.apache.kafka.clients.NetworkClient - [Producer clientId=producer-1] Initialize connection to node kafka01:9092 (id: -1 rack: null) for sending metadata request 19:37:42.283 [kafka-producer-network-thread | producer-1] DEBUG org.apache.kafka.clients.NetworkClient - [Producer clientId=producer-1] Initiating connection to node kafka01:9092 (id: -1 rack: null) using address kafka01/192.168.30.160 19:37:42.287 [main] INFO org.apache.kafka.common.utils.AppInfoParser - Kafka version: 2.4.1 19:37:42.287 [main] INFO org.apache.kafka.common.utils.AppInfoParser - Kafka commitId: c57222ae8cd7866b 19:37:42.288 [main] INFO org.apache.kafka.common.utils.AppInfoParser - Kafka startTimeMs: 1682077062274 19:37:42.296 [main] DEBUG org.apache.kafka.clients.producer.KafkaProducer - [Producer clientId=producer-1] Kafka producer started 19:37:45.442 [main] INFO com.example.demokafka.test.TestProduct - 准备发送 19:38:00.121 [kafka-producer-network-thread | producer-1] DEBUG org.apache.kafka.common.network.Selector - [Producer clientId=producer-1] Created socket with SO_RCVBUF = 32768, SO_SNDBUF = 131072, SO_TIMEOUT = 0 to node -1 19:38:00.432 [kafka-producer-network-thread | producer-1] DEBUG org.apache.kafka.clients.NetworkClient - [Producer clientId=producer-1] Completed connection to node -1. Fetching API versions. 19:38:00.432 [kafka-producer-network-thread | producer-1] DEBUG org.apache.kafka.clients.NetworkClient - [Producer clientId=producer-1] Initiating API versions fetch from node -1. 19:38:00.577 [kafka-producer-network-thread | producer-1] DEBUG org.apache.kafka.common.network.Selector - [Producer clientId=producer-1] Connection with kafka01/192.168.30.160 disconnected java.io.EOFException: null at org.apache.kafka.common.network.NetworkReceive.readFrom(NetworkReceive.java:96) at org.apache.kafka.common.network.KafkaChannel.receive(KafkaChannel.java:424) at org.apache.kafka.common.network.KafkaChannel.read(KafkaChannel.java:385) at org.apache.kafka.common.network.Selector.attemptRead(Selector.java:651) at org.apache.kafka.common.network.Selector.pollSelectionKeys(Selector.java:572) at org.apache.kafka.common.network.Selector.poll(Selector.java:483) at org.apache.kafka.clients.NetworkClient.poll(NetworkClient.java:547) at org.apache.kafka.clients.producer.internals.Sender.runOnce(Sender.java:335) at org.apache.kafka.clients.producer.internals.Sender.run(Sender.java:244) at java.base/java.lang.Thread.run(Thread.java:834) 19:38:00.579 [kafka-producer-network-thread | producer-1] DEBUG org.apache.kafka.clients.NetworkClient - [Producer clientId=producer-1] Node -1 disconnected. 19:38:00.583 [kafka-producer-network-thread | producer-1] WARN org.apache.kafka.clients.NetworkClient - [Producer clientId=producer-1] Bootstrap broker kafka01:9092 (id: -1 rack: null) disconnected 实在想不通是啥问题了,望大佬能赐教。
]]>拓扑中产生了 change-log 结尾的分区,查了很多资料是说和状态存储有关系,这个 topic 对集群流量会有什么影响,如果没有会怎么样
我的理解是 change-log 只会保存最后一次状态,重启 stream 时候本地会从 change-log 恢复状态,不过这样就很难估算 kafka 集群流量了
最后吐槽下 kafka stream 相关书籍实在太少,外网资料也是,可能从 spark 学起更好?
]]>我想默认从上一次消费的地点继续消费. 有没有办法实现?
kafka 是如何认识这个独立的消费者? 群组我知道, 是由 group name 来标识. 但是独立消费者我没想明白有什么办法. kafka 权威指南中也没有找到相关的描述.
似乎 kafka 消费者使用群组是一个很普遍的做法.
kafka 新手. 轻喷.
]]># ./kafka-metadata-shell.sh --snapshot /tmp/kraft-combined-logs/__cluster_metadata-0/00000000000000000000.log Loading... Starting... [ Kafka Metadata Shell ] >> cat metadataQuorum/leader LeaderAndEpoch(leaderId=OptionalInt[1], epoch=8) 想通过 API 获取,不知道可不可行?
]]>相同 ip ,time 的 record 会有多个不同值,且有可能是不同分区,不同消息中传过来的,消费到的时间也可能相隔的比较长
如何快速找到同一 ip ,同一时间的最大 value ?
]]>官网地址: http://www.redisant.cn/ka/
打开 Kafka Assistant ,切换到 Stream 选项卡,点击新建,在 Host 、Port 输入框中输入 Stream 程序所在的主机地址和 JMX 端口。
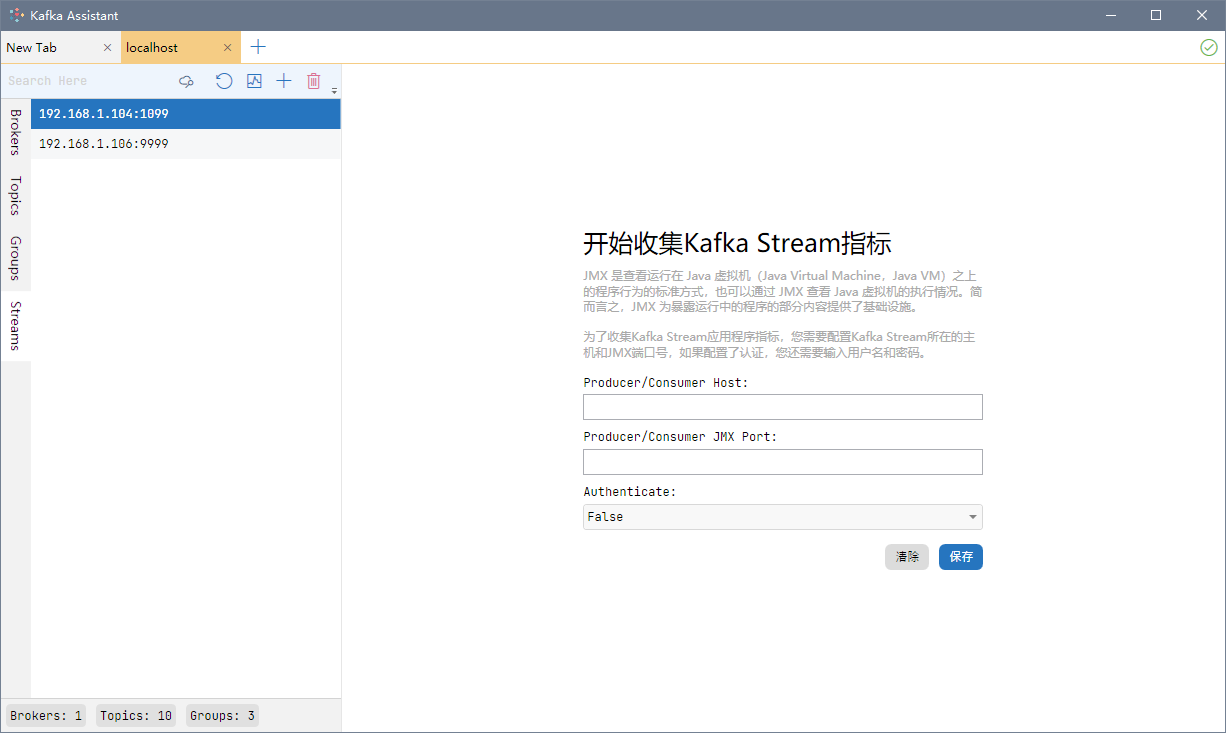
然后,左侧会出现新建的 Stream 程序,右侧可以看到每个 Stream 程序的拓扑图。拓扑图可以保存为各种格式:png 、jpg 、pdf 、svg 等等,非常方便。

kafka 小白,有没有大佬指点一下
]]>用来广播的 topic 消息量不会很大(<1w/day ) kafka 中其他 topic 流量会很大
不太深入 kafka 的原理 怕影响其他 topic 的性能
或者 用 redis 的 pub/sub 实现会更好吗 ]]>
* 目前看到,从 buffer 中读取到的消息都是完整的,但是从 kafka 消费出来的消息很多都被截断了,差不多 30%多
* 每个 topic n 个 partition ,1 个 group ,n 个消费者
* 每条消息的长度从 2k 到 10k 不等,也有更长的,但 90%多在 2k 到 10k 之间
* 被截断的消息:截断为 n 段( n 不确定),比较大的一部分基本都处于 4000 到 8000 个字节之间,小的部分可能就几个字节
**详细信息如上**
**各位,帮忙看下是什么原因导致的,先谢过🙏** ]]>
谢谢拉 ]]>
希望可以展开说说:
-
topic 在业务中如何定义
-
partition 在业务中如何定义,对于生产者和消费者而言,partition 意味着什么
-
消费者组在业务中的应用场景是什么样的?
-
kafka 在不同业务中有哪些最佳实践和骚操作?
已知同一个 groupid,能控制多个消费者竞争问题,不会出现同一条数据被多个消费者重复读取。
但是多个线程同时去读,是否必须手动提交 offset,auto_commit 不知道能否满足要求?
我在网上看到的 case,基本上是让本地建个临时 sqlite 库,根据 partion 和线程对应去消费,手动提交 offset 。
比如:https://www.cnblogs.com/lshan/p/11647485.html
我不知道最佳实践是怎样的?
各位大佬,很急在线等!
]]>缺点: 1.缺少统一的调度,消费者零散地散落在各个项目里,消息堆积时不好扩容. 2.同一条消息(对同一张表的一条操作记录)会下发到多个消费者(不同的业务逻辑),浪费网络资源.同时 binlog 的消息是全量下发(所有表的操作记录推到同一个 topic),消费者还得各自筛选自己需要的消息,浪费 cpu 资源. 3.消费者之间可能有依赖关系,但是业务逻辑是解耦的,不能相互调用,因此无法感知到依赖的资源是否已经到位.
所以我们计划把这些消费者整合到同一个项目里面统一管理,统一调度. 深思熟虑了 5 分钟之后,我感觉可能遇到这些问题: 1.如何协调消费者之间的依赖关系?如果直接把它们丢到一个串行的方法里面,那么调用链就很长,消息延迟就很严重,有些消费者本来没有前置依赖,但却要白白等前面的消费者执行完,不合理.如果都是异步去调用它们的话,就无法感知到依赖关系. 2.消息消费的速度会不会受到影响?以前一条消息开了很多消费者去消费,现在整合到一起,调用链变长了.
所以想问问大家有没有现成的开源框架是解决这类问题的? 我们开发的语言是 scala 和 java,mq 是 kafka,当然消息源最好也能支持其他 mq
]]>在消费者端配置了下面两个参数,以保证消费者每 10 秒能够回调一次
fetch-min-bytes = Integer.MAX_VALUE (当一次拉取请求的数据小于这个值,就会等待直到满足这个参数,这里我设到最大值) fetch-max-wait-ms: 10000 (如果等待超过这个值就直接返回,这里设为 10 秒) 同时我是用批量消费的方式进行的,每次回调都会打印一次时间间隔观察实际消费情况,发现消费者在每 10 秒的时候总会拉取两次,但我希望它只拉取一次
KafkaConsumer--->==:10s size:6 KafkaConsumer--->==:0s size:14 KafkaConsumer--->==:9s size:7 KafkaConsumer--->==:0s size:13 所以比较疑惑是触发了哪个参数导致它会多回调一次
btw,我尝试过把下面这些参数都调到最大,但都无济于事
send.buffer.bytes = Integer.MAX_VALUE receive.buffer.bytes = Integer.MAX_VALUE max.partition.fetch.bytes Integer.MAX_VALUE fetch.max.bytes = Integer.MAX_VALUE max.poll.records = Integer.MAX_VALUE 有没有熟悉 kafka 的大佬帮忙解答一二
]]>ka,fka 命令行是可以消费的,但通过 python 消费时,一直消费不到,进程也不超时,更换消费组,消费lastet最新 msg 也无响应, consume.poll(1000, 1) 第一个参数的 timeout 仿佛无效,设置了也是一直等待消费 import time from kafka import KafkaConsumer topic1 = 'additional_order' host = '192.168.14.55:9092' cOnsume= KafkaConsumer(topic, group_id="group1", bootstrap_servers=host, auto_offset_reset='latest', security_protocol='SASL_PLAINTEXT', sasl_mechanism='PLAIN', sasl_plain_username='admin', sasl_plain_password='$%<a' api_version=(0, 10) ) while True: count += 1 if time.time() - start_time > 1 * 60: print('超时,退出') break msg = consume.poll(1000, 1) # 看上去,进程是一直等候在这里 print(count) import time from kafka import KafkaConsumer topic1 = 'additional_order' host = '192.168.14.55:9092' cOnsume= KafkaConsumer(topic, group_id="group1", bootstrap_servers=host, auto_offset_reset='latest', security_protocol='SASL_PLAINTEXT', sasl_mechanism='PLAIN', sasl_plain_username='admin', sasl_plain_password='$%foper!@#$', api_version=(0, 10) ) while True: count += 1 if time.time() - start_time > 1 * 60: print('超时,退出') break msg = consume.poll(1000, 1) # 看上去,进程是一直等候在这里 print(count) 服务提供商: 1. 集群每个节点的吞吐量在 1.5 MB/s 左右,远小于服务的吞吐量 2. 3 个节点每个 topic 设置 90 个分区, 3 副本,这个使用方式不太合理,服务需要对每个 topic 维护 90x3 个 replica 进程,io process 也要维护 90x3 个,原来顺序的读写也会退化为随机读写,网络 process 需要维护 90 个 3. 看历史监控记录,副本延迟在过去是会频繁发生的 4. 之前有建议您修改分区到 6 ~ 9 个 您这边反馈分区数调低之后消费者有延迟,实际您这边的吞吐量远没有达到服务应该有的吞吐量,怀疑是客户端方面有问题,需要您在消费端打印每次 poll 的时间和 poll 下来的消息条数,确定消费者行为,这样我们可以进一步分析 现在我们这边的解决方案还是和之前的建议一样,topic 分区数调整到 6 ~ 9 个,消费延迟的问题需要从客户端出发解决 开发者: 调整为 6 个分区之后,不是消费延迟问题,是单个消费者的能力不足,跟不上生产的速度。之前已经试过了,10 来分钟就堆积了 100 万消息。 服务提供商: 6 个分区的话,可以使用 6 个消费者,6 个消费者的能力远不止这么差. max.poll.records,可以用于指定批量消费条数的 配合配置 max.partition.fetch.byte 和 fetch.max.wait.ms 两个参数 可以实现批量消费 kafka 的消息。您看看 php 的客户端是否有设置这些参数的地方,或者有其他地方可以设置消费者的批量消费的,因为一条条的消费,效率是极低的 开发者: rdkafka 扩展里,好像没这个相关的参数 当前是 1 个 topic,90 个分区,分区数太多引起 kafka 集群副本同步时的性能下降问题。服务商建议减少分区数,但是减少分区数会有大量的消息堆积,rdkafka 如何提升单消费者的性能呢?
消费者大致代码如下:
$this->RdKafkaCOnf= new RdKafka\Conf(); $this->RdKafkaConf->setRebalanceCb(function (RdKafka\KafkaConsumer $kafka, $err, array $partitiOns= null) { switch ($err) { case RD_KAFKA_RESP_ERR__ASSIGN_PARTITIONS: $kafka->assign($partitions); break; case RD_KAFKA_RESP_ERR__REVOKE_PARTITIONS: $kafka->assign(null); break; default: throw new \Exception($err); } }); $this->RdKafkaConf->set('group.id', $groupid); // Initial list of Kafka brokers $this->RdKafkaConf->set('metadata.broker.list', $configs); $this->RdKafkaConf->set('socket.keepalive.enable', 'true'); $this->RdKafkaConf->set('enable.auto.commit', 'true'); $this->RdKafkaConf->set('auto.commit.interval.ms', '100'); $this->RdKafkaConf->set('auto.offset.reset', 'smallest'); $topic = is_array($topic) ? $topic : [$topic]; $cOnsumer= new RdKafka\KafkaConsumer($this->RdKafkaConf); $consumer->subscribe($topic); while (true) { $message = $consumer->consume($timeout * 1000); switch ($message->err) { case RD_KAFKA_RESP_ERR_NO_ERROR: call_user_func_array($callback, [$message]); // $consumer->commitAsync($message); break; case RD_KAFKA_RESP_ERR__PARTITION_EOF: // Log::get('consumer')->info("No more messages; will wait for more"); break; case RD_KAFKA_RESP_ERR__TIMED_OUT: // Log::get('consumer')->error("Timed out"); break; default: throw new \Exception($message->errstr(), $message->err); } } //callback function if (count(self::$queue) >= 10 || (time() - $this->lastWriteTimestamp) >= 1) { self::$queue[] = $msg; $queue = self::$queue; self::$queue = []; $this->lastWriteTimestamp = time(); $reportData = []; foreach ($queue as $message) { $data = json_decode($message->payload, true); // 入库 } } else { self::$queue[] = $msg; } 我在本地( windows )启动 kafka,使用 PowerShell,命令执行完成后出现右箭头,输入内容后按回车,消息会被发送出去。
当我使用 xshell 连接到服务器上,尝试同样的操作, 输入内容按回车,理论上会将数据发送出去,实际上却换行了,导致我无法将数据发送出去。 我觉得这应该是 xshell 的问题,但我却不知道怎么做。 也不排除是 kafka 版本的问题
kafka 版本:kafka_2.11-2.3.0
]]>xshell 版本: xshell6
我现在用的是启动的时候动态生成 groupId, 比如 name + uuid 的方式
但是这样重启后就会导致原来的 consumerGroup 对应的实例都被销毁了.但 kafka 里依然存在原来的 consumerGroup, 监控上看已经被销毁的 consumerGroup 也会发现堆积越来越严重, 有谁知道正确的使用姿势吗??
不胜感激
😢
]]>我通过 docker 在本地部署 kafka,之后在容器内部用 console-producer 和 console-consumer 脚本试了一下,功能是正常的,但容器外使用 golang 程序( sarama )连接却无法成功
zookeeper 中的注册信息是这样的:
get /brokers/ids/1001 {"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://localhost:9092"],"jmx_port":-1,"host":"localhost","timestamp":"1585138788130","port":9092,"version":4} docker 部署时使用的参数是:
KAFKA_ADVERTISED_HOST_NAME: localhost KAFKA_CREATE_TOPICS: "test:1:2" KAFKA_BROKER_ID: 1 KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1 KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181 kafka 版本 2.4.0, zookeeper 版本 3.4.13
sarama 反馈信息:“kafka: client has run out of available brokers to talk to (Is your cluster reachable?)”
sarama log:
[sarama] 2020/03/25 20:41:02 client/metadata fetching metadata for all topics from broker 127.0.0.1:9092 [sarama] 2020/03/25 20:41:02 Connected to broker at 127.0.0.1:9092 (unregistered) [sarama] 2020/03/25 20:41:02 client/metadata got error from broker -1 while fetching metadata: read tcp 127.0.0.1:52260->127.0.0.1:9092: read: connection reset by peer [sarama] 2020/03/25 20:41:02 Closed connection to broker 127.0.0.1:9092 [sarama] 2020/03/25 20:41:02 client/metadata no available broker to send metadata request to [sarama] 2020/03/25 20:41:02 client/brokers resurrecting 1 dead seed brokers [sarama] 2020/03/25 20:41:02 Closing Client kafka: client has run out of available brokers to talk to (Is your cluster reachable?) 现在,为了保证服务的高可用性和水平扩展,服务是水平扩展的,但是现在有一种需求,要求消息从发送完后到接收响应的整条链路不受水平扩展( Cluster )的影响,也就是说 ,即使 scale out 了,业务应用级别的一条消息及他的响应,要保证能够从 A 发的,也到响应回到 A,而不是 A1 或 A2
请教大家,为了实现这个,要考虑从什么方式切入进行改造?
]]>但是都没有说原因,想问问各位大神,这是什么原因造成了 kafka 性能下降,而 RocketMQ 性能稳定呢?
还有,当消息大小超过 2048 的时候,kafka 性能也会下降,RocketMq 性能稳定,这又是什么原因呢?
]]>有没有那种 zookeeper 和 kafka 打包到一个镜像里面的呀
]]>如何解决: 如果是延迟小时, push 之前先放到 redis 里, 然后 work 通过 lua 轮训拿到需要真的 push 到队列里的请求, 然后 push 到 kafka 里.
整个功能其实和 Python 的 celery 或者 Go 的 machinery 很像.但是前者需要单独部署项目太复杂, 后者不支持 kafka.
有搞头吗?
]]>[2019-01-09 01:08:05,297] WARN Send worker leaving thread (org.apache.zookeeper.server.quorum.QuorumCnxManager)
[2019-01-09 01:08:05,296] INFO Received connection request /(org.apache.zookeeper.server.quorum.QuorumCnxManager)
[2019-01-09 01:08:05,447] ERROR Unreasonable buffer length: 100000 (org.apache.zookeeper.server.quorum.QuorumCnxManager)
[2019-01-09 01:08:05,547] INFO Received connection request /(org.apache.zookeeper.server.quorum.QuorumCnxManager)
[2019-01-09 01:08:05,564] WARN Connection broken for id 8444275087900673, my id = 1, error = (org.apache.zookeeper.server.quorum.QuorumCnxManager)
java.io.IOException: Received packet with invalid packet: 0
at org.apache.zookeeper.server.quorum.QuorumCnxManager$RecvWorker.run(QuorumCnxManager.java:1012)
[2019-01-09 01:08:05,565] WARN Interrupting SendWorker (org.apache.zookeeper.server.quorum.QuorumCnxManager)
[2019-01-09 01:08:05,595] WARN Interrupted while waiting for message on queue (org.apache.zookeeper.server.quorum.QuorumCnxManager)
java.lang.InterruptedException
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.reportInterruptAfterWait(AbstractQueuedSynchronizer.java:2014)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.awaitNanos(AbstractQueuedSynchronizer.java:2088)
at java.util.concurrent.ArrayBlockingQueue.poll(ArrayBlockingQueue.java:418)
at org.apache.zookeeper.server.quorum.QuorumCnxManager.pollSendQueue(QuorumCnxManager.java:1094)
at org.apache.zookeeper.server.quorum.QuorumCnxManager.access$700(QuorumCnxManager.java:74)
at org.apache.zookeeper.server.quorum.QuorumCnxManager$SendWorker.run(QuorumCnxManager.java:929)
[2019-01-09 01:08:05,597] WARN Send worker leaving thread (org.apache.zookeeper.server.quorum.QuorumCnxManager)
[2019-01-09 01:08:05,597] INFO Received connection request (org.apache.zookeeper.server.quorum.QuorumCnxManager)
[2019-01-09 01:08:05,646] WARN Connection broken for id 3377699988963328, my id = 1, error = (org.apache.zookeeper.server.quorum.QuorumCnxManager)
java.io.IOException: Received packet with invalid packet: 0
at org.apache.zookeeper.server.quorum.QuorumCnxManager$RecvWorker.run(QuorumCnxManager.java:1012)
[2019-01-09 01:08:05,670] WARN Interrupting SendWorker (org.apache.zookeeper.server.quorum.QuorumCnxManager)
[2019-01-09 01:08:05,670] WARN Interrupted while waiting for message on queue (org.apache.zookeeper.server.quorum.QuorumCnxManager)
请问 ERROR Unreasonable buffer length: 100000 这个是什么原因造成的,应该如何解决? ]]>