
sudo ifconfig eth1 172.18.0.2 netmask 255.255.255.255 broadcast 172.18.0.2 mtu 1430 echo "1 rt1" | sudo tee -a /etc/iproute2/rt_tables sudo ip route add 172.18.0.1 src 172.18.0.2 dev eth1 table rt1 sudo ip route add default via 172.18.0.1 dev eth1 table rt1 sudo ip rule add from 172.18.0.2/32 table rt1 sudo ip rule add to 172.18.0.2/32 table rt1
第二网卡通网了之后,为什么第二网卡的 ip 只能访问 22 端口,80,443 之类的全都不通?请各位大神不吝赐教,急急急。
]]>经常见到问个人博客放在哪儿。为什么很少有人提到 GAE + CloudFlare 呢? ]]>
再看看提示,说明了 3 月底就会停用所有未绑定账单(信用卡)的实例。
昨天花了一天时间修改代码搬迁到自己的 VPS 上,为自己以前省钱买单。
不想再用 GAE 这种太多特定 api 的托管平台了。
]]>Google Analytics(Google 分析)是 Google 的一款免费的网站分析服务,Google Analytics 功能非常强大,只要在网站的页面上加入一段代码,就可以提供丰富详尽的图表 式报告。并且显示人们如何找到和浏览相关网站以及如何改善访问者的体验。提高网站投 资回报率、增加转换,在网上获取更多收益。可对整个网站的访问者进行跟踪,并能持续 跟踪营销广告系列的效果,利用此信息将了解到哪些关键字真正起作用、哪些广告词最有 效,访问者在转换过程中从何处退出。自从其诞生以来,即广受好评。 沙龙主题:如何利用 Google Analytics 搭建 (Google )最个性化转化漏斗
活动时间:1 月 19 日 14:15-17:00
活动地点: 深圳市南山区中国地质大学产学研基地 2 楼 A208 科技寺
如果你满足以下其中之一的条件,欢迎你参加:
-
想利用工具提升网站转化效率的同学;
-
对 Google Analytics 工具感兴趣或想进阶学习的同学;
-
想要了解 Aftership 的同学;
注:
1.现场将进行 Coding 教学,有兴趣的小伙伴记得带上个人电脑,参与 Coding 环节将有机会获得主办方准备精美奖品;
2.现场将提供稳定的网络环境供用户体验;
活动流程:
14:00-14:15 签到 14:15-14:30 主持人开场 14:30-15:00 Fifty-five (智博)share GA and GTM features 15:00-15:30 AfterShip share our use case 15:30-15:45 Tea Break 15:45-16:30 Live coding and demo 16:30-17:00 Demo 点评及颁奖环节 17:00-17:00 自由交流时间
具体的出来了后将在活动行上进行发布。欢迎各位报名参加!
]]>我如果想用这三个位置的 IP,哪家 VPS 服务上可以搞呢?
以上,谢谢 ]]>
是为了做视频配音。然后一句句去下载很麻烦嘛,就想搞个轮子。
自动识别多行文本,或者 excel,然后每段落单独下载为 mp3,这样比较方便。
方法
目前是直接去摸了 gcloud 官方的 api 啦,传送门:
Quickstart: Using the Client Libraries | Cloud Text-to-Speech API | Google Cloud
问题
现在全局开着飞机,但跑 sample.py 还是会 504 超时。(访问 google 或 youtube 或 g trans 都 ok 的)
想请问有没有人用过 google 这个接口?
或者有其它轮子也可以推荐一下
]]>我们发送此电子邮件是为了通知您,您的 Google Play 发布商帐号已被终止。
终止原因:违反了开发者计划政策中的假冒行为政策。
Google Play 发布商帐号被终止与开发者的行为有关,而且可能还会影响多个帐号注册和相关的 Google 服务。
您可以访问开发者政策中心,以更好地了解我们如何贯彻实施开发者计划政策。如果您已阅读相关政策,并认为此终止决定可能有误,请与我们的政策支持团队联系。
请勿尝试注册新的开发者帐号。我们目前不会恢复您的帐号。
此致
Google Play 团队敬上
This is a notification that your Google Play Publisher account has been terminated.
REASON FOR TERMINATION: Violation of the Impersonation policy within the Developer Program Policies.
Google Play Publisher terminations are associated with developers, and may span multiple account registrations and related Google services.
You can visit the Developer Policy Center to better understand how we enforce Developer Program Policies. If you ’ ve reviewed the policy and feel this termination may have been in error, please reach out to our policy support team.
Please do not attempt to register a new developer account. We will not be restoring your account at this time.
The Google Play Team
----------------------------------------------------------------------------------------------------------------------------------
原因就是我作死,把开发者名称改为:Google Design,导致违规,那么还有希望解封吗? ]]>
"This means that after August 10, 2015 these applications will stop servicing requests and you will no longer have programmatic access to your data. If you no longer need your Master/Slave applications and associated data, no action is required. However, if you do need any of these applications we encourage you to migrate them to HRD immediately. "
这是不是已经凉透了? ]]>
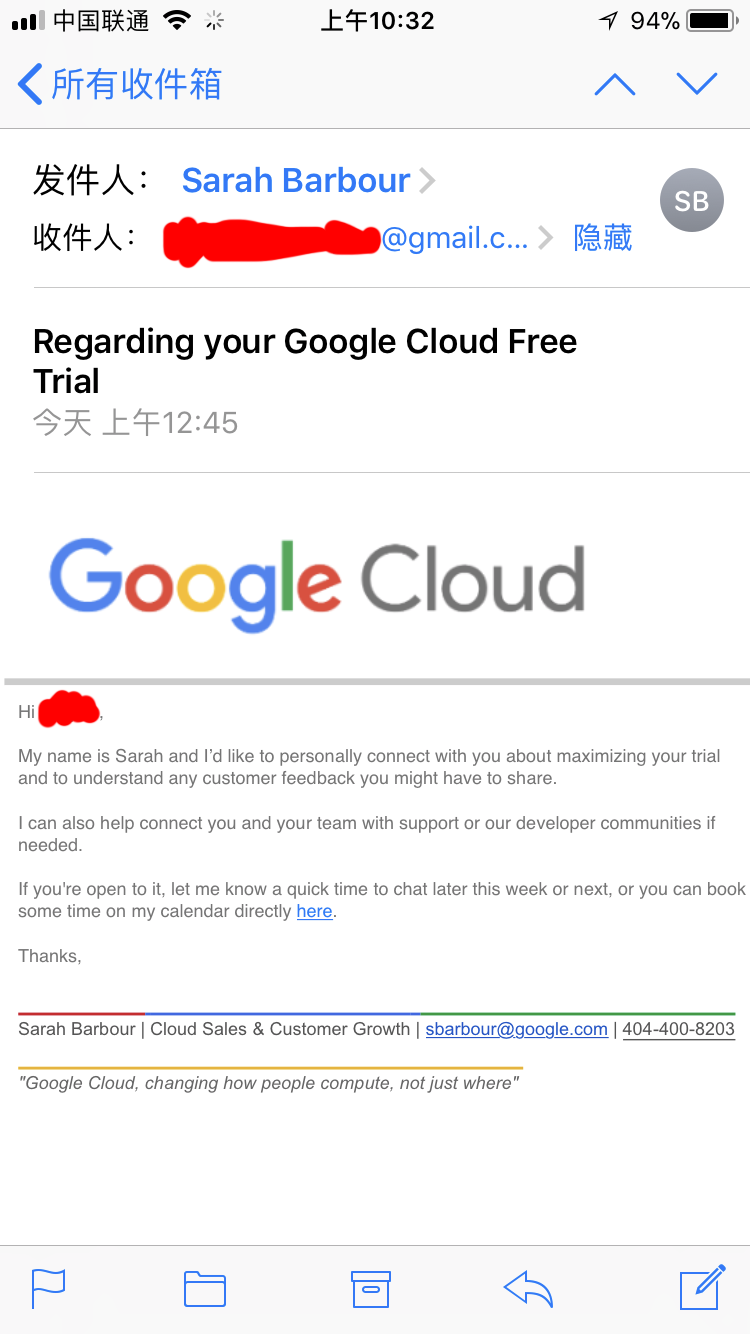
Hi xxx, My name is Sarah and I ’ d like to personally connect with you about maximizing your trial and to understand any customer feedback you might have to share. I can also help connect you and your team with support or our developer communities if needed. If you're open to it, let me know a quick time to chat later this week or next, or you can book some time on my calendar directly here. Thanks, Sarah Barbour | Cloud Sales & Customer Growth | sbarbour@google.com | 404-400-8203 "Google Cloud, changing how people compute, not just where" 各位能帮我解释一下吗?
免费增值?要写反馈?
后端服务 后端服务
- instance-2
端点协议:HTTPS 已命名的端口: https 超时:30 秒 运行状况检查: https-kk 会话粘性:无 Cloud CDN:已停用
高级配置 实例组 地区 运行状况良好 自动调节 平衡模式 容量 instance-group-1 asia-east1-b 1 / 1 关闭 CPU 利用率上限:80% 100% 主机和路径规则
主机 路径 后端 所有不匹配的项(默认) 所有不匹配的项(默认) instance-2 前端
协议 IP:端口 证书 HTTP 135.10.167.69:80 — HTTPS 135.10.167.69:443 js-ca1
]]>- 不再使用额外的 security manager
- 不再有 Java7 里的 class 白名单限制
- 使用 Jetty9
- 支持 Servlet 3.1/2.5
- 可以用 Java 自带的 Thread 类创建新 thread,不用再使用 GAE SDK 里的 ThreadManager
Java8 只是开始:-)
]]>我弄了个 GCE
asia-northeast1-a 和 asia-east1-a
日本的 ping 在 100 左右 台湾在 60 左右(北方联通)
手贱把 asia-northeast1-a 删了重新建了一个悲剧发生了
第一次分配的 ip 是 104 开头的 延迟 100 左右……
第二次分配的就是 3x 开头的 ip 了……延迟直接 200+
重试了好多次都是这样了……看了下绕路美国了……怎么破
]]>尊敬的 Google Apps 客户:
我们创建 Google Apps 是为了帮助世界各地的人们协同合作、共同创新,让您的单位快速运作、取得更大成就。现在,我们要推出一个更能彰显此使命的新名称: G Suite 。
您好!在接下来的几周内,您会在熟悉的地方(包括管理控制台、帮助中心和您的帐单上)看到我们的新名称和新徽标。 G Suite 依然是您日常使用的多合一解决方案,包含同样强大的工具: Gmail 、文档、云端硬盘和日历。
感谢您一路陪伴,才有如今的 G Suite 。我们一直致力于改进技术,让 G Suite 不断完善并与您的团队一同成长。
如果您有任何问题,欢迎随时与我们联系。
请访问我们的官方博文(英文版)以便了解详情。
此致
G Suite 团队
--------------------------- ]]>
谢谢
]]>https://cnwordpresssss.appspot.com/
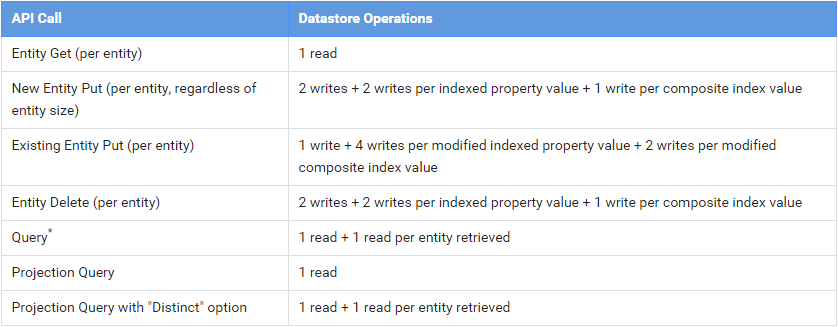
另外 GAE 没有免费的 MYSQL (就是这个了 Google Cloud SQL 。据说也不能使用远程 MYSQL 服务器),
但是可以连接到 Google Cloud Datastore 这个 NosQL 有木有啊……
Google 搜索到 http://stackoverflow.com/questions/19219748/can-google-cloud-datastore-access-with-php
得到这个……
https://github.com/tomwalder/php-gds
以及演示
https://github.com/tomwalder/php-gds-demo
http://php-gds-demo.appspot.com/
用它代替 MYSQL 还是可以使用的吧…… ]]>
比如,开了代理,想测试 ping facebook.com 的延迟情况,怎么测?
]]>






 ]]>
]]>