
path('api/v1/projects/', include('projects.urls')) 例如以上代码,按着 command 点击 urls 就可以跳转到 urls 定义的地方
]]>在 Django 中,我们都知道当我们 all 之后是不会马上去查询数据的,当我们真正使用的时候,才会去触发查询操作。
模型类
下面我将带着大家从源码的角度一步一步解析。
from django.db import models # Create your models here. class Demo1(models.Model): name = models.CharField(max_length=100) age = models.IntegerField() def __str__(self): return self.name 看一下这几行代码发生了什么
使用是继承了 models.Model 。去看一下 models.Model 做了什么
# models.Model class Model(AltersData, metaclass=ModelBase): pass 可以看到把 ModelBase 当成了元类,那我们就去再看一下 ModelBase
class ModelBase(type): """Metaclass for all models.""" def __new__(cls, name, bases, attrs, **kwargs): super_new = super().__new__ # Also ensure initialization is only performed for subclasses of Model # (excluding Model class itself). parents = [b for b in bases if isinstance(b, ModelBase)] if not parents: return super_new(cls, name, bases, attrs) # Create the class. module = attrs.pop("__module__") new_attrs = {"__module__": module} classcell = attrs.pop("__classcell__", None) if classcell is not None: new_attrs["__classcell__"] = classcell attr_meta = attrs.pop("Meta", None) # Pass all attrs without a (Django-specific) contribute_to_class() # method to type.__new__() so that they're properly initialized # (i.e. __set_name__()). contributable_attrs = {} for obj_name, obj in attrs.items(): if _has_contribute_to_class(obj): contributable_attrs[obj_name] = obj else: new_attrs[obj_name] = obj new_class = super_new(cls, name, bases, new_attrs, **kwargs) abstract = getattr(attr_meta, "abstract", False) meta = attr_meta or getattr(new_class, "Meta", None) base_meta = getattr(new_class, "_meta", None) app_label = None # Look for an application configuration to attach the model to. app_cOnfig= apps.get_containing_app_config(module) if getattr(meta, "app_label", None) is None: if app_config is None: if not abstract: raise RuntimeError( "Model class %s.%s doesn't declare an explicit " "app_label and isn't in an application in " "INSTALLED_APPS." % (module, name) ) else: app_label = app_config.label new_class.add_to_class("_meta", Options(meta, app_label)) if not abstract: new_class.add_to_class( "DoesNotExist", subclass_exception( "DoesNotExist", tuple( x.DoesNotExist for x in parents if hasattr(x, "_meta") and not x._meta.abstract ) or (ObjectDoesNotExist,), module, attached_to=new_class, ), ) new_class.add_to_class( "MultipleObjectsReturned", subclass_exception( "MultipleObjectsReturned", tuple( x.MultipleObjectsReturned for x in parents if hasattr(x, "_meta") and not x._meta.abstract ) or (MultipleObjectsReturned,), module, attached_to=new_class, ), ) if base_meta and not base_meta.abstract: # Non-abstract child classes inherit some attributes from their # non-abstract parent (unless an ABC comes before it in the # method resolution order). if not hasattr(meta, "ordering"): new_class._meta.ordering = base_meta.ordering if not hasattr(meta, "get_latest_by"): new_class._meta.get_latest_by = base_meta.get_latest_by is_proxy = new_class._meta.proxy # If the model is a proxy, ensure that the base class # hasn't been swapped out. if is_proxy and base_meta and base_meta.swapped: raise TypeError( "%s cannot proxy the swapped model '%s'." % (name, base_meta.swapped) ) # Add remaining attributes (those with a contribute_to_class() method) # to the class. for obj_name, obj in contributable_attrs.items(): new_class.add_to_class(obj_name, obj) # All the fields of any type declared on this model new_fields = chain( new_class._meta.local_fields, new_class._meta.local_many_to_many, new_class._meta.private_fields, ) field_names = {f.name for f in new_fields} # Basic setup for proxy models. if is_proxy: base = None for parent in [kls for kls in parents if hasattr(kls, "_meta")]: if parent._meta.abstract: if parent._meta.fields: raise TypeError( "Abstract base class containing model fields not " "permitted for proxy model '%s'." % name ) else: continue if base is None: base = parent elif parent._meta.concrete_model is not base._meta.concrete_model: raise TypeError( "Proxy model '%s' has more than one non-abstract model base " "class." % name ) if base is None: raise TypeError( "Proxy model '%s' has no non-abstract model base class." % name ) new_class._meta.setup_proxy(base) new_class._meta.concrete_model = base._meta.concrete_model else: new_class._meta.concrete_model = new_class # Collect the parent links for multi-table inheritance. parent_links = {} for base in reversed([new_class] + parents): # Conceptually equivalent to `if base is Model`. if not hasattr(base, "_meta"): continue # Skip concrete parent classes. if base != new_class and not base._meta.abstract: continue # Locate OneToOneField instances. for field in base._meta.local_fields: if isinstance(field, OneToOneField) and field.remote_field.parent_link: related = resolve_relation(new_class, field.remote_field.model) parent_links[make_model_tuple(related)] = field # Track fields inherited from base models. inherited_attributes = set() # Do the appropriate setup for any model parents. for base in new_class.mro(): if base not in parents or not hasattr(base, "_meta"): # Things without _meta aren't functional models, so they're # uninteresting parents. inherited_attributes.update(base.__dict__) continue parent_fields = base._meta.local_fields + base._meta.local_many_to_many if not base._meta.abstract: # Check for clashes between locally declared fields and those # on the base classes. for field in parent_fields: if field.name in field_names: raise FieldError( "Local field %r in class %r clashes with field of " "the same name from base class %r." % ( field.name, name, base.__name__, ) ) else: inherited_attributes.add(field.name) # Concrete classes... base = base._meta.concrete_model base_key = make_model_tuple(base) if base_key in parent_links: field = parent_links[base_key] elif not is_proxy: attr_name = "%s_ptr" % base._meta.model_name field = OneToOneField( base, on_delete=CASCADE, name=attr_name, auto_created=True, parent_link=True, ) if attr_name in field_names: raise FieldError( "Auto-generated field '%s' in class %r for " "parent_link to base class %r clashes with " "declared field of the same name." % ( attr_name, name, base.__name__, ) ) # Only add the ptr field if it's not already present; # e.g. migrations will already have it specified if not hasattr(new_class, attr_name): new_class.add_to_class(attr_name, field) else: field = None new_class._meta.parents[base] = field else: base_parents = base._meta.parents.copy() # Add fields from abstract base class if it wasn't overridden. for field in parent_fields: if ( field.name not in field_names and field.name not in new_class.__dict__ and field.name not in inherited_attributes ): new_field = copy.deepcopy(field) new_class.add_to_class(field.name, new_field) # Replace parent links defined on this base by the new # field. It will be appropriately resolved if required. if field.one_to_one: for parent, parent_link in base_parents.items(): if field == parent_link: base_parents[parent] = new_field # Pass any non-abstract parent classes onto child. new_class._meta.parents.update(base_parents) # Inherit private fields (like GenericForeignKey) from the parent # class for field in base._meta.private_fields: if field.name in field_names: if not base._meta.abstract: raise FieldError( "Local field %r in class %r clashes with field of " "the same name from base class %r." % ( field.name, name, base.__name__, ) ) else: field = copy.deepcopy(field) if not base._meta.abstract: field.mti_inherited = True new_class.add_to_class(field.name, field) # Copy indexes so that index names are unique when models extend an # abstract model. new_class._meta.indexes = [ copy.deepcopy(idx) for idx in new_class._meta.indexes ] if abstract: # Abstract base models can't be instantiated and don't appear in # the list of models for an app. We do the final setup for them a # little differently from normal models. attr_meta.abstract = False new_class.Meta = attr_meta return new_class new_class._prepare() new_class._meta.apps.register_model(new_class._meta.app_label, new_class) return new_class def _prepare(cls): """Create some methods once self._meta has been populated.""" opts = cls._meta opts._prepare(cls) if opts.order_with_respect_to: cls.get_next_in_order = partialmethod( cls._get_next_or_previous_in_order, is_next=True ) cls.get_previous_in_order = partialmethod( cls._get_next_or_previous_in_order, is_next=False ) # Defer creating accessors on the foreign class until it has been # created and registered. If remote_field is None, we're ordering # with respect to a GenericForeignKey and don't know what the # foreign class is - we'll add those accessors later in # contribute_to_class(). if opts.order_with_respect_to.remote_field: wrt = opts.order_with_respect_to remote = wrt.remote_field.model lazy_related_operation(make_foreign_order_accessors, cls, remote) # Give the class a docstring -- its definition. if cls.__doc__ is None: cls.__doc__ = "%s(%s)" % ( cls.__name__, ", ".join(f.name for f in opts.fields), ) get_absolute_url_override = settings.ABSOLUTE_URL_OVERRIDES.get( opts.label_lower ) if get_absolute_url_override: setattr(cls, "get_absolute_url", get_absolute_url_override) if not opts.managers: if any(f.name == "objects" for f in opts.fields): raise ValueError( "Model %s must specify a custom Manager, because it has a " "field named 'objects'." % cls.__name__ ) manager = Manager() manager.auto_created = True cls.add_to_class("objects", manager) # Set the name of _meta.indexes. This can't be done in # Options.contribute_to_class() because fields haven't been added to # the model at that point. for index in cls._meta.indexes: if not index.name: index.set_name_with_model(cls) class_prepared.send(sender=cls) class Manager(BaseManager.from_queryset(QuerySet)): def get_queryset(self): """ Return a new QuerySet object. Subclasses can override this method to customize the behavior of the Manager. """ return self._queryset_class(model=self.model, using=self._db, hints=self._hints) def all(self): # We can't proxy this method through the `QuerySet` like we do for the # rest of the `QuerySet` methods. This is because `QuerySet.all()` # works by creating a "copy" of the current queryset and in making said # copy, all the cached `prefetch_related` lookups are lost. See the # implementation of `RelatedManager.get_queryset()` for a better # understanding of how this comes into play. return self.get_queryset() 可以看到这里是继承了 BaseManager.from_queryset(QuerySet)。那继续看**BaseManager.from_queryset(QuerySet)**方法
class BaseManager: @classmethod def from_queryset(cls, queryset_class, class_name=None): if class_name is None: class_name = "%sFrom%s" % (cls.__name__, queryset_class.__name__) return type( class_name, (cls,), { "_queryset_class": queryset_class, **cls._get_queryset_methods(queryset_class), }, ) 可以看到是使用 type 创建了类,然后继承了当前类,最后定义了一个**_queryset_class**方法。并把传入的 queryset_class(QuerySet)设置成了_queryset_class 属性的值。
class QuerySet(AltersData): """Represent a lazy database lookup for a set of objects.""" def __init__(self, model=None, query=None, using=None, hints=None): self.model = model self._db = using self._hints = hints or {} self._query = query or sql.Query(self.model) self._result_cache = None self._sticky_filter = False self._for_write = False self._prefetch_related_lookups = () self._prefetch_dOne= False self._known_related_objects = {} # {rel_field: {pk: rel_obj}} self._iterable_class = ModelIterable self._fields = None self._defer_next_filter = False self._deferred_filter = None def __iter__(self): """ The queryset iterator protocol uses three nested iterators in the default case: 1. sql.compiler.execute_sql() - Returns 100 rows at time (constants.GET_ITERATOR_CHUNK_SIZE) using cursor.fetchmany(). This part is responsible for doing some column masking, and returning the rows in chunks. 2. sql.compiler.results_iter() - Returns one row at time. At this point the rows are still just tuples. In some cases the return values are converted to Python values at this location. 3. self.iterator() - Responsible for turning the rows into model objects. """ self._fetch_all() return iter(self._result_cache) def _fetch_all(self): if self._result_cache is None: self._result_cache = list(self._iterable_class(self)) if self._prefetch_related_lookups and not self._prefetch_done: self._prefetch_related_objects() 开始查询
Demo1.objects.all() [test_model for test_model in demos] 看一下这几行代码发生了什么。
DemoModes.objects 返回的就是上面的Manager。然后调用了 Manager 的all。然后在 all 里面返回了了_queryset_class。由上面我们可以知道 queryset_class 是传入的 QuerySet 。
查询生命周期
flowchart TD model[Demo] --> objects[objects] -- Manager --> all --> get_queryset[返回了 QuerySet] 这里现在返回了 QuerySet ,但是实际上没有和数据库交互呢。真正和数据库交互是在**[test_model for test_model in demos]**这里。
当开始遍历 demos 的时候会触发__iter__方法,然后在这个魔法函数里面会触发**__fetch_all [和数据交互] **方法,并返回一个一个迭代对象
查询生命周期
flowchart TD for[循环] --> iter[_\_iter\_\_] --> _fetch_all --数据库交互--> 返回结果 /usr/bin/python3 /home/some/Qexo/manage.py runserver 0.0.0.0:8000 --noreload 以上脚本,直接在终端是可以运行的,服务也起来了。 但要开机运行,试过了以下三种方法,都不行 1 、https://blog.csdn.net/yuezhilangniao/article/details/113772277 2 、https://www.cnblogs.com/jingzaixin/p/15920472.html 出现的错误是
rc-local.service - /etc/rc.local Compatibility Loaded: loaded (/etc/systemd/system/rc-local.service; enabled; preset: enabled) Drop-In: /usr/lib/systemd/system/rc-local.service.d └─debian.conf Active: failed (Result: exit-code) since Tue 2024-07-23 09:22:23 CST; 15min ago Duration: 236ms Process: 3617 ExecStart=/etc/rc.local start (code=exited, status=0/SUCCESS) Main PID: 3621 (code=exited, status=1/FAILURE) CPU: 344ms 7 月 23 09:22:23 some-Ubuntu23 systemd[1]: Starting rc-local.service - /etc/rc.local Compatibility... 7 月 23 09:22:23 some-Ubuntu23 systemd[1]: Started rc-local.service - /etc/rc.local Compatibility. 7 月 23 09:22:23 some-Ubuntu23 systemd[1]: rc-local.service: Main process exited, code=exited, status=1/FAILURE 7 月 23 09:22:23 some-Ubuntu23 systemd[1]: rc-local.service: Failed with result 'exit-code'. 3 、使用 supervisor,出现的错误是:
ImportError: Couldn't import Django. Are you sure it's installed and available on your PYTHONPATH environment variable? Did you forget to activate a virtual environment? ...... 求助,请教,在 ubuntu23 中如何开机时自动运行上面提到的脚本
]]> Description=/etc/rc.local Compatibility COnditionPathExists=/etc/rc.local [Service] Type=forking ExecStart=/etc/rc.local start TimeoutSec=0 StandardOutput=tty RemainAfterExit=yes SysVStartPriority=99 [Install] WantedBy=multi-user.target /etc/rc.local 文件内容
#!/bin/sh -e # # rc.local # # This script is executed at the end of each multiuser runlevel. # Make sure that the script will "exit 0" on success or any other # value on error. # # In order to enable or disable this script just change the execution # bits. # # By default this script does nothing. echo "看到这行字,说明添加自启动脚本成功。" > /home/some/Qexo/test.log a=`lsof -i:8000 | wc -l` if [ "$a" -eq "0" ];then echo "start nohup django:8000" >> /home/some/Qexo/test.log nohup /usr/bin/python3 /home/some/Qexo/manage.py runserver 0.0.0.0:8000 > cmdb.log 2>&1 & else echo "8000 端口被占用" >> /home/some/Qexo/test.log fi #source/home/some/Qexo/ #nohup /usr/bin/python3 /home/some/Qexo/manage.py runserver 0.0.0.0:8000 > cmdb.log 2>&1 & echo "看到这行字,说明 django.sh 执行过。" >> /home/some/Qexo/test.log exit 0 重启后,sudo systemctl status rc-local,报如下错误
rc-local.service - /etc/rc.local Compatibility Loaded: loaded (/etc/systemd/system/rc-local.service; enabled; preset: enabled) Drop-In: /usr/lib/systemd/system/rc-local.service.d └─debian.conf Active: failed (Result: exit-code) since Tue 2024-07-23 09:22:23 CST; 15min ago Duration: 236ms Process: 3617 ExecStart=/etc/rc.local start (code=exited, status=0/SUCCESS) Main PID: 3621 (code=exited, status=1/FAILURE) CPU: 344ms 7 月 23 09:22:23 some-Ubuntu23 systemd[1]: Starting rc-local.service - /etc/rc.local Compatibility... 7 月 23 09:22:23 some-Ubuntu23 systemd[1]: Started rc-local.service - /etc/rc.local Compatibility. 7 月 23 09:22:23 some-Ubuntu23 systemd[1]: rc-local.service: Main process exited, code=exited, status=1/FAILURE 7 月 23 09:22:23 some-Ubuntu23 systemd[1]: rc-local.service: Failed with result 'exit-code'. 实际上两年前淘宝就彻底不让卖奈飞了,只有老客户找我买,我这两年什么事也没干,感觉人生好失败。
前段时间发现几个做的不错的流媒体合租网站,所以自己一时起兴选择开发自己的在线商店。
我一边学习一边开发,最近完成了用户注册登录、订单处理、支付宝集成、自动发货、帮助文档、推广算法、微信等常用聊天方式的客服接入,我大学环境设计专业,在大学做设计方案的时候就很不喜欢套用一些普遍的、没有创新性的模版,我喜欢自己折腾和认真学习优秀的解决方案。因此开发网站没有选择开源的在线商店模版,所有模型都是自己设计,前后端一起做。
最近总是在怀疑自己,做这件事是否有意义?因为流媒体的风控,合租的体验其实在降低,大众也普遍了解网飞应该如何订阅…… 我不懂我的目标是什么,我的业务是否真的可以为用户带来便利?是否真的可以解决当下的一些问题?其次…可以解决我的一日三餐吗…毕竟我已经 26 了,也靠不起父母。如果我把这个项目当做一个兴趣的话,好像对我来说有些收获,我体验到了这种崭新的学习对象给我带来的成就感,好像在学习上可以掌握的东西变多了,比不学习的时候心里发觉踏实了很多。我从毕业到现在四年了,这四年基本没有学习跟任何职业关联的东西,除了流媒体合租方面。
我在设计网站的时候遇到了很多问题,技术上的就不说了,因为我不是技术专家,我更专注于设计问题的解决方案。
我很想设计一个完美的用户表单填写和验证的方案,同时确保前后端通信的安全。比如大家都不喜欢注册账号、不愿意提交手机号码这些来作为身份验证,这是我在开发网站中积极解决的事情。
我在用户订单板块要求用户填写邮箱地址,用户提交订单到后端的支付请求函数中,我加入了对于用户 email 状态的检测进行重定向,或者继续处理表单的逻辑,如果用户输入的 email 不在数据库内就会跳转到注册页面,反之会跳转到登陆页面,并且自动填写 email 信息,用户只需要输入一个密码即可,注册和登录界面都设计了一个复选框,如果用户同意,那么表单会在注册/登录成功之后继续发起支付请求(仅限于订单卡片板块发起的请求),这样可以提高转化率和减少用户重新输入。如果在点开订单卡片之前已经登录,那么我们的订单表格就会自动输入用户登录的 email 。类似的处理机制运用到我们网站的各个板块。
我还专注于网站信息的上下架解决方案,比如帮助中心的文档,为此我选择的是为其创建一个博客模型,在后台就可以创建或更新现有的帮助中心文档…不用打开代码编辑器添加重复的操作……
最后是关于网站的安全防卫措施,我对所有用户输入的信息都进行了双重认证,不相信用户输入的任何信息,主要防止一些针对网站的恶意攻击,因为网站的前端都是透明的,这点让人很不安。
以上就是我的一些心路历程,和对网站开发的思考…… 项目演示视频: https://youtube.com/shorts/8gza4B-1Upo?si=xaIFFFNsHt6yxd29
]]>1 、负责核心技术问题的攻关、架构设计、系统优化,协助解决项目开发过程中 的技术难题;
2 、高性能服务器端程序的设计、开发和测试;
3 、负责现有业务的微服务化,并在不断的学习当中能够形成自己的架构方法论;
4 、Go/Golang/C++/C 开发后台相关项目经验。
岗位要求:
1 、专科及以上学历,3 年以上 go 后端开发经验,至少有 一个完整项目的开
发经验;
2 、扎实的 Golang 基础,懂得代码调优及性能优化方法;
3 、熟悉 goroutine 、channel 、mutex 、syncmap ,熟悉网络编程;
4 、熟悉 restful 接口开发,并有相关经验;
5 、熟悉后台对外开放平台接口规划,并有相关经验熟悉一种关系型数据库,如 MySQL 、Sql
Server ,熟悉 SQL 语句;
6 、熟悉常用 NoSQL 数据库,MongoDB 、Redis 等;
7 、熟悉 bash 脚本编程,熟悉常用的 Linux 系统等实用工具;
8 、保持技术热情,有强烈的责任心和团队精神,善于沟通和合作。
底薪范围:20~50K 人民币(具体面议)
求职咨询👉
email: zygs2151@gmail.com
#golang
工作方式及语言:
全职远程工作 远程工作时间:北京时间 10:00 - 20:00 ,固定周末双休,午休+晚餐休 国内节假日统一正常休假
工作语言:全中文
录用流程: 视频面试:2-3 轮,1-2 天内反馈
邮箱: zygs2151@gmail.com
wechat ID : shenyanlin2212
其他远程岗位包括:UI/UX ,Web 前端,Cocos 开发,游戏系统策划等 ]]>
然后 INSTALLED_APPS 添加了"allauth.socialaccount.providers.openid_connect"
sites 配置不太清楚做什么的
问题:现在一点击登录就 500error..
不知道有没有老哥愿意付费帮忙看一下。
然后就看到 migrate 文件一直叠加生成
问题是开发的时候 DB 结构可能被我改来改去 过一会甚至还会有回退的 migrate 文件(
然后强迫症就很不爽 我会在确认修改后把本地数据库整个清掉 然后 git reset 掉所有开发期间的 migrate 文件
再重新生成一遍 migrate 再同步到生产库去
这是正常开发流程吗 怎么感觉一点都不优雅
]]>class CustomManager(models.Manager): def filter(self, *args, **kwargs): cOnditions= ... return super().get_queryset().filter(conditions).filter(*args, **kwargs) 这样使用 Custom.objects.filter(key=value) 是没有问题的,但是 Custom.objects.filter(key=value).filter(key2=value2) 这样就不行了,因为这个 filter 只作用在 manager 上,而没有作用在 queryset 上,应该如何处理啊?
这里为什么不是 fork 或者不是 spawn ,就会返回 1 呢。
]]>有没有办法将这些 migrations 文件放在修改他代码的当前目录下的 migrations 里,保证 venv 环境不会变更? ]]>
什么时候的事?
说到登录了,当然是用 https, form 表单 post ,自带的。
]]>后端返回的是形如
{a_1:1,a_2:2,a_3:3.....}这样的对象。我要在模板中展示这些{{ a_1 }},{{ a_2 }}...
自然而然想用循环,其实是个嵌套 {{ a_{{forloop_counter}} }},但是模板不支持。
和 gpt 磋商半天,这样曲线实现了
1.后端返回加一层壳:
{data:{a_1:1,a_2:2,a_3:3.....}}
2.你可以使用 with 标签创建一个中间变量 ,并在内部构建嵌套的变量名来访问对应的值:
{% for num in "123" %}
{% with var_name="total_"|add:num %}
{{ var_name }}: {{ data|getvar:var_name }}
{% endwith %}
{% endfor %}
3.自定义一个过滤器
@register.filter
def getvar(dictionary, key):
return dictionary.get(key, '')
有没有更 decent 的方法,难怪都去用 vue 了。 ]]>
早起把网站的友链网页和自主添加友链功能撸出来了,过来收集一波友链
实现功能:
- 友链显示页面,友链提交页面
- 网站 celery 定时任务自动检测友链,主要是将无法访问的友链标记出来不做跳转,同时将恢复访问的友链恢复显示
- 自主提交友链后给管理员发送系统消息,管理员可以及时审核,审核通过的直接显示到友链页面
友联页面效果:
系统推送信息:
定时任务检查自动更新友链状态
感兴趣的可以交换一波友情链接
]]>from django.db import models class Category(models.Model): name = models.CharField(max_length=50) parent = models.ForeignKey('self', on_delete=models.CASCADE, blank=True, null=True, related_name='children') def __str__(self): return self.name 需要跟前端合作, 需要告知他新 api 的使用方式. 现在是丢给他保存了 example 的 postman 让他自己看. 这种方式对前端友好吗?
文档肯定是最好, 但一条一条 api 写文档感觉比较低效, 只是用爱发电的小项目,也花不起太多时间.
不知道有没有事后补救的办法? ]]>
很简单的数据, 就是踩赞数随时间变化的趋势之类的
谢谢! ]]>
django 的数据库是要在 docker build container 的时候,就把服务器的数据库配置写到 settings.py 里吗,那 build 完 image ,肯定要在本地看看能不正常启动这个 container ,没问题才可以 push 上去吧。那我每次改 setting 配置,在 git 版本控制的时候,其实这些配置改动不算是一种迭代更新,因为一个程序会运行在许多个服务器,会用到许多个数据库。
除非数据库也用 docker 启动,到时候服务器启动 django 和数据库两个容器。
但是我启动数据库容器的操作也是挺麻烦的,也得改改数据库容器的配置。而且我看到 docker hub 上一些官方镜像,比如 postgresql 也有提到启动完镜像,进去创建数据库这种操作。
综上,我觉得还不如本地调试完 django container ,服务器 pull 下来,改改这个数据库和其他的一些配置。像数据库这种算基础设施,安装在宿主机上,而且这种软件不会像我们写的程序遇到太多安装问题。
整理了一下
数据库开发环境和服务器不一致,所以就要有两种数据库配置(开发 /生产环境)
-
构建好的镜像本地应该调试好了(不是指调试代码运行的问题,是指调试代码部署的问题),那就要求本地调试的时候,能用上服务器的数据库配置。
-
开发环境安装数据库软件,并创建和服务器的数据库一样的配置
-
或者构建数据库镜像
-
程序会多次部署,会用到不同数据库,每次改动数据库配置,在版本控制上来讲不算是一次迭代更新,所以觉得构建镜像前先改好数据库配置不合理
我最终的想法是,生产环境的配置先把 key 写好了,value 不写。本地测试部署,服务器部署的时候,进入镜像改改再运行
]]>github django-gettext
这也是我写的第一个 vscode 插件,功能非常简单,目前只支持高亮语法和跳转链接
借鉴了别人的 gettext 插件( Django 的国际化模块本质上还是调用的 GNU gettext ), 但是不支持不带行号的跳转,本来想提个 mr 的,但是人家的插件是给 gettext 写的比较通用,不太好支持我这种小众需求,于是我就打算自己尝试写一个
结果稍微看一下 vscode 的文档发现写一个小插件还是比较简单的
欢迎大家尝试一下,后续我也会慢慢改进的
补充提醒大家一下 django 的国际化可以调用 django-admin 的
django-admin makemessages --add-location=file -a 命令
]]>d2 = Department.objects.first()
如何知道 d1 是通过 user 访问的呢?
我想如果是通过 user.department 访问的,就给这个 department 加上一个属性 department.from=user ,怎么操作好? ]]>
但是这两天一个偶然机会突然发现,在我自己电脑开发环境调试模式下,访问 admin 后台,部分 admin 自带的 css 文件访问返回 200 ,但是大小为 0 。
清空浏览器缓存,更换浏览器后仍然如此。
到生产服务器上看,collectstatic 完成后,static/admin/css 目录下,有几个 css 文件,大小也为 0 ,只有两三个文件大小正常。
具体情况如图:
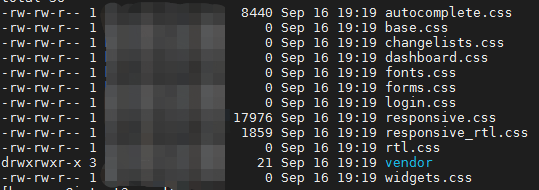
服务器上 static 目录下这部分大小为 0 的文件,在我自己开发环境用浏览器访问大小为 0 ,大小非 0 的文件在开发环境也都能正常访问。
查看本机和服务端 site-package 中的 django 目录,这些 css 文件都是有内容的。
目前发现 js 目录有一个 related-widget-wrapper.js 文件大小为 0 (这个文件在 lib 中 django 同级目录下没发现),其他没发现异常。
django2.1.5 我们这边几个项目在用,目前发现有的项目有这个问题,有的正常。 对比了下 settings 设置,也没发现什么特殊的地方。admin 看上样式也都正常。
这个是怎么回事?有什么解决思路吗?
麻烦各位指教。 ]]>
时间没到之前是个介绍页面,时间到了之后进入真正的 view 处理函数。
触发条件不一定是时间,也可能是后台控制的。就是要做到程序不重启,同一 url 对应的 view 变了。
我是这样做的,加了个全局变量,然后在 url 对应个 view 函数里做判断,后台改变这个全局变量,执行不同的 view 函数。
IS_RELEASE 是全局变量,entrance 函数是入口函数,release 函数是改变入口的视图函数。
IS_RELEASE = False
def entrance(request):
global IS_RELEASE
if IS_RELEASE:
return index2022(request)
else:
return index2(request)
@login_required
def release(request):
global IS_RELEASE
if IS_RELEASE:
IS_RELEASE = False
else:
IS_RELEASE = True
return redirect("/conf/")
这个方法在本地调试没问题,但是上到服务器后,出现执行 release 函数后 IS_RELEASE 没按预期改变,或者有秒级的延迟,我猜是不是有 cdn 的影响,但是这个都应该是动态页面,每个请求都要回服务器处理的。
]]>{ "code": 200, "msg": "ok", "data": { some data } } { "code": 404, "msg": "http not found", "data": null } 我说一下我之前的实现,这种实现我认为很怪,而且并不能完美封装一些 500 错误,想请教一下有没有什么可以优雅的方式。
首先我使用一个 dataclasses.dataclass 进行定义返回数据结构(code,msg,data)
from dataclasses import dataclass from typing import Any @dataclass class Result: code: int msg: str data: Any 后面我需要打各种补丁
- 在 api view 中使用 JsonResponse 进行返回,当然也包括一些业务上的逻辑判断都可以在这里进行处理
from dataclasses import asdict from django.http import JsonResponse from rest_framework import views class SomeApiView(views.APIView): def get(, request, *args, **kwargs) -> JsonResponse: # do something return JsonResponse(asdict(Result(200, 'ok', null))) - modelviewset 的处理(继承 mixin 对返回做处理),如下,只写了一个举例:
from dataclasses import asdict from django.http import JsonResponse from rest_framework import status, mixins class MyRetrieveModelMixin(mixins.RetrieveModelMixin): def retrieve(self, request, *args, **kwargs): instance = self.get_object() serializer = self.get_serializer(instance) return JsonResponse(asdict(Result(200, 'ok', serializer.data))) - 全局异常处理,对类似 drf-jwt,drf-serializer 中的一些错误,只能在 settings.py 中的 rest framework 中进行异常处理配置,并且用这个方法去处理,这种形式总感觉特别怪。
# 配置 REST_FRAMEWORK = { # ... # 异常处理(统一封装为 code msg data 格式) 'EXCEPTION_HANDLER': 'utils.result_handler.custom_exception_handler', # ... } def custom_exception_handler(exc, context): respOnse= exception_handler(exc, context) if response is not None: # logger # 进行一些处理 处理成 Result(code, msg, data) # 这里对很多处理,尤其 serializer 中的处理 特别烦! # 比如手机号唯一约束,前端就想要 code:400 msg:"该手机号已被使用" return JsonResponse(...) 说实话这些补丁看的我有些难受,很想知道有没有什么优雅的处理方式
thanks !
]]>from django.db import connection with connection.cursor() as cursor: cursor.execute(sql, params=params_dict) result = dictfetchall(cursor) return result 这种写法有问题吗?
]]>请各位大神指点 ]]>
产品需求
- 不要定期触发的定时任务,比如 1 分钟一次查数据库,不够精准,耗资源
- 用指定时间任务的形式触发修改上下架状态,(用下架时间判断上下架的方式,这样就不用定时任务触发,pass )
所以想问问,django 有没有接口触发,创建任务,在指定的日期时间运行一次的模块。
]]>select be.id, be.fullName1, be.workEmail from employees as be left join id_mapping as ci on be.id = ci.user_id where be.id like '%Steven%' or be.fullName1 like '%Steven%' or be.workEmail like '%Steven%' or ci.new_id like '%Steven%' group by be.id - 研究了一下午,暂无头绪.先用 raw 运行着 sql 语句.
- 请各位出手相助.
图片正确的路径是:
http://127.0.0.1:8000/media/img/2022/02/13/%E6%9C%AA%E6%A0%87%E9%A2%98-1_z6YBLvG.jpg 后台超级链接的路径是:
http://127.0.0.1:8000/admin/web/detectioninfo/4/change/media/img/2022/02/13/%E6%9C%AA%E6%A0%87%E9%A2%98-1_z6YBLvG.jpg 还没学明白,不知道哪里的问题,求指点
url.py 的 urlpatterns
re_path(r'^media/(?P<path>.*)$', serve, {'document_root': settings.MEDIA_ROOT}, name='media'), class DetectionInfo(models.Model): img_1 = models.ImageField(verbose_name="现场图", upload_to='img/%Y/%m/%d',blank=True,null=True) 是为了减轻数据库压力吗?还是说兼容其他没有 on update 的数据库?
]]>需求上大概是这么描述:
- 有一个包括一些静态属性的表, 比如
用户表. 里面有两条记录是id=1, name='Tom', age=28,id=2, name='Tom', age=35. 注意到有两个同名的用户, 是用id保证唯一性的 - 现在还有一个项目表, 要将项目分派给某个人. 出于使用上的考虑, 肯定不会直接提供
id让用户填写, 一般都是提供name比较合理. 这里的问题是,name字段是有重名情况的
所以我的需求是, 当用户选择了 Tom 这个人的时候, 会动态显示这个 Tom 的其他属性在页面上, 可以显示在表单里自动补全, 也可以做个模态框都行(但模态框最好是做个问号图标, 鼠标悬停在上面就显示)
这样一来, 虽然有名字重名的情况, 但我可以通过这个人的其他属性分辨出来某个项目是否分配给了合适的人 (age 当然也会重复, 这里只是举个例子)
如果是 django 里面自己写的页面, 用 ajax 向数据库查询一下应该就好了, 但是现在暂时要利用一下现成的 django admin 模块的话, 要怎么在 django admin change 页面实现这个功能呢?
我找过一些方法, 比如扩展 django admin change 这个模版之类的, 但不确定这么做是不是最佳实践
谢谢大佬们赐教
明明选了 markdown 格式, 但是不知道为什么没有正确显示代码引用……
]]>nginx+uwsgi+django 框架下,用 django-apscheduler 定时执行任务,但我的任务是保存在内存(MemoryJobStore),不能用数据库保存(因为数据库用的是 sqlite ,任务本身需要读取读写数据库,会造成 database is locked 导致后面任务不执行)。
问题
怎么获取到 scheduler 实例?因为现在不确定是否添加了任务,原来在本地 debug 下将 scheduler 设成全局变量,通过全局变量和 get_jobs()方法是可以获取到任务列表,但这个方法貌似在服务器的生产环境上用不了。
有大神提一下建议吗?
]]>有人可以分享下 i18n,英文翻译成中文的 demo 或项目吗 ]]>
第二家公司 b 端业务 saas 开发 直接用 django 参数校验都不做 问了同事就说 一般都按正确的传 参数有问题开发的时候就解决了。。
第三家公司 也是直接用 django 倾向原生 sql 代码看着挺难受的 一直拼接 if xxx: sql += 'xxx' 写下来 一大堆怼在 views 里面 刚开始也比较抵触 难维护 容易出语法错误 开发效率低 感觉写接口就贼慢 先去 navicat 写 sql 调好了 复制到代码里面 也不用 orm 建表 先 navicat 建表 建好了在写 model 。。。不过 sql 能力是锻炼了,但感觉开发效率不行,感觉这样没必要用 django
你们公司的 django 项目是怎样的
]]>想过滤满足 A 表中 age 大于等于 13 的,且关联 B 表的,且关联的 B 表中记录的 is_admin 为真的所有 A 表记录,为啥上面的 queryset 啥都查不出来,但是下面的能查出来呢?看了官网感觉 filter 和 exclude 没啥区别啊,都是过滤出想要的东西,就是 select foo from bar where xxx=yyy ( filter ),select foo from bar where xxx!=yyy ( exclude )。求大佬解释一下。 ]]>
class BaseSerializer(serializers.HyperlinkedModelSerializer): def __new__(cls, *args, **kwargs): media_field = kwargs["context"]["request"].accepted_media_type if hasattr(cls, "related_fields"): for name, fields in cls.related_fields.items(): if "text" in media_field: field = fields.get("text", None) elif "json" in media_field: field = fields.get("json", None) elif "yaml" in media_field: field = fields.get("yaml", None) else: log.error(f"{name} not found any type field") continue cls._declared_fields[name] = field cls.Meta.fields += (name,) return super().__new__(cls, *args, **kwargs) 根据请求头里包含的 accepted_media_type 来判断
使用方法
class PermissionSerializer(BaseSerializer): url = serializers.HyperlinkedIdentityField( view_name='permission-detail', lookup_field="codename", # lookup_url_kwarg="codename", ) name = serializers.CharField(max_length=255) codename = serializers.CharField(max_length=100) content_type = serializers.SlugRelatedField( read_Only=True, slug_field="app_label" ) related_fields = dict( user_set=dict( text=serializers.HyperlinkedRelatedField( view_name='user-detail', many=True, queryset=User.objects.get_queryset(), lookup_field="username", required=False, ), json=serializers.StringRelatedField(many=True), yaml=serializers.StringRelatedField(many=True), ), group_set=dict( text=serializers.HyperlinkedRelatedField( view_name='group-detail', many=True, queryset=Group.objects.get_queryset(), lookup_field="name", required=False, ), json=serializers.StringRelatedField(many=True), yaml=serializers.StringRelatedField(many=True), ), ) class Meta: model = Permission fields = ( 'name', 'codename', 'content_type', 'url' ) 测试可行,还有其他好用的方法吗?
或者说我这个方法符合 REST 的风格吗?
具体业务就是设计了一个 Redis Set 队列控制并发,任务正常运行的时候是可以加入、弹出的,但是如果任务在运行过程中发生死机,或者其它未知的 Django 整体崩溃,虽然概率很小,但是一旦发生这个队列就会产生脏数据,我现在是考虑启动 Django 的时候,自动清空这个队列,但是就要求这个函数仅运行一次,如果实现不了,我就只能考虑其他办法。
请问有什么其他方法能让我的业务代码在启动的时候就运行一次么?
]]>年纪大了,发现还是得要深入一个领域,才行。勿在浮沙筑高台。 ]]>
{ "A": 1, "B": 2 } 我想筛选字段 "A" 的值为 2 ,或者 字段里面包含 B 这个 Key ,这种条件下,Django 的索引会加快查询速度么?
]]>这时中间表除了指向的源表是不一样的,其他字段包括目标表都是一样的,比如:
# base model class Created(models.Model): created = models.DateTimeField(auto_now_add=True) class Meta: abstract = True required_db_vendor = "postgresql" class CreatedModified(Created): last = models.DateTimeField(auto_now=True) class Meta(Created.Meta): abstract = True class Argument(CreatedModified): ... class ArgumentThrough(CreatedModified): # argument 中间表基类 argument = models.ForeignKey( to=Argument, on_delete=models.PROTECT ) value = models.JSONField(blank=True) def clean(self): argument_value_validator(self.argument, self.value) class Meta(CreatedModified.Meta): abstract = True class Inventory(CreatedModified): ... class Meta(CreatedModified.Meta): abstract = True class Host(Inventory): inventory_variables = models.ManyToManyField( to=Argument, through="HostArgument", blank=True, help_text=_("Variables for host") ) class HostArgument(ArgumentThrough): # Host 到 Argument 的中间表 host = models.ForeignKey( to=Host, on_delete=models.CASCADE ) class Group(Inventory): inventory_variables = models.ManyToManyField( to=Argument, through="GroupArgument", blank=True, help_text=_("Variables for group") ) class GroupArgument(ArgumentThrough): # Group 到 Argument 的中间表 group = models.ForeignKey( to=Group, on_delete=models.CASCADE ) 可以看到 Host 和 Group 的两个关联 Argument 的中间表除了指向的源表以外,其他字段几乎是一模一样的,所以可以改成这样:
class Host(Inventory): ... class Group(Inventory): ... def add_related_field__argument(cls): through_cls_dict = { cls.__name__.lower(): models.ForeignKey( to=cls, on_delete=models.CASCADE ), "__module__": cls.__module__ } cls.add_to_class( "inventory_variables", models.ManyToManyField( to=Argument, through=type( f"{cls.__name__}Argument", (ArgumentThrough,), through_cls_dict ), blank=True, ) ) for model in (Host, Group): add_related_field__argument(model) 用这种方法,就可以不用写“重复”的代码了。
不知道你们是怎么解决这类问题的,希望我能抛砖引玉。